系统可靠性模型
与系统故障模型对应的就是系统的可靠性模型。人们经常说某系统“十分可靠”,那么这个“十分”究竟如何衡量呢?下面介绍几种常用的模型。
1 时间模型
最著名的时间模型是由 Shooman 提出的可靠性增长模型,这个模型基于这样一个假设:一个软件中的故障数目在 t = 0 时是常数,随着故障被纠正,故障数目逐渐减少。
在此假设下,一个软件经过一段时间的调试后剩余故障的数目可用下式来估计:
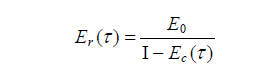
其中,τ 为调试时间, Er (τ ) 为在时刻 τ 软件中剩余的故障数, E0 为τ = 0 时软件中的故障数, Er (τ ) 为在[0,τ]内纠正的故障数,I 为软件中的指令数。
由故障数 Er (τ ) 可以得出软件的风险函数:
Z(t)=C⋅Er(τ)
其中 C 是比例常数。于是,
软件的可靠度为:

软件的平均无故障时间为:
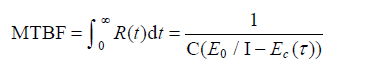
在 Shooman 的模型中,需要确定在调试前软件中的故障数目,这往往是一件很困难的任务。
2 故障植入模型
故障植入模型是一个面向错误数的数学模型,其目的是以程序的错误数作为衡量可靠性的标准,模型的原型是 1972 年由 Mills 提出的。
Mills 提出的故障植入模型的基本假设如下:
(1)程序中的固有错误数是一个未知的常数。
(2)程序中的人为错误数按均匀分布随机植入。
(3)程序中的固有错误数和人为错误被检测到的概率相同。
(4)检测到的错误立即改正。
用 N0 表示固有错误数,N1 表示植入的人为错误数,n 表示检测到的错误数,ξ 表示被检测到的错误中的人为错误数,则:
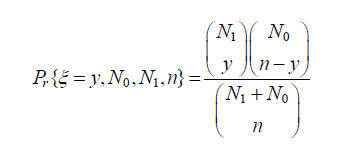
对于给定的 N1,n,在测试中检测到的人为错误数为 k,用最大似然法求解可得固有错误数 N0 的点估计值为:
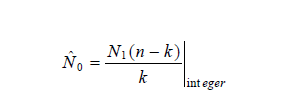
考虑到实施植入错误时遇到的困难,Basin 在 1974 年提出了两步查错法,这个方法是由两个错误检测人员独立对程序进行测试,检测到的错误立即改正。用 N0 表示程序中的固有错误数,N1 表示第一个检测员检测到的错误数,n 表示第二个检测员检测到的错误数,用随机变数 η 表示两个检测员检测到的相同的错误数,则:
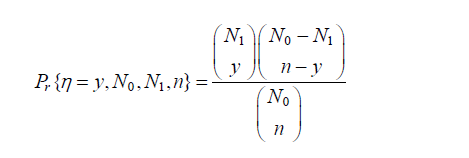
如果实际测得的相同错误数为 k,则程序固有错误数 N 0 的点估计值为:
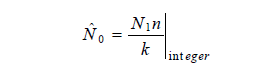
3 数据模型
在数据模型下,对于一个预先确定的输入环境,软件的可靠度定义为在 n 次连续运行中软件完成指定任务的概率。
最早的一个数据模型是 Nelson 于 1973 年提出的,其基本方法如下:
设说明所规定的功能为 F,程序实现的功能为 F′,预先确定的输入集。
E={ ei:i=1,2,- - -,N }
令导致软件差错的所有输入的集合为 Ee ,即:
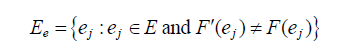
则软件运行一次出现差错的概率为:
P1=|Ee|/|E|
一次运行正常的概率为:
R1=1−P1=1−Ee /E
在上述讨论中,假设了所有输入出现的概率相等,如果不相等,且ei出现的概率为pi(i =1,2,- - -,n),则软件运行一次出现差错的概率为:
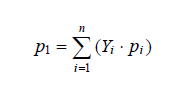
其中:
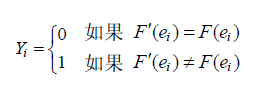
于是,软件的可靠度(n 次运行不出现差错的概率)为:
R(n)=R1n=(1-P1)n
只要知道每次运行的时间,上述数据模型中的 R(n)就很容易转换成时间模型中的 R(t)。