文章目录
前言
Playwright是一个强大的Python库,仅用一个API即可自动执行Chromium、Firefox、WebKit等主流浏览器自动化操作,并同时支持以无头模式、有头模式运行。 Playwright提供的自动化技术是绿色的、功能强大、可靠且快速,支持Linux、Mac以及Windows操作系统。
一、Playwright的安装与使用
1.安装
- 要使用 Playwright,需要 Python 3.7 版本及以上,请确保 Python 的版本符合要求。
安装 Playwright,命令如下:
# 安装playwright库
pip install playwright
# 安装浏览器驱动文件(安装过程稍微有点慢)
playwright install
2.录制
- 使用Playwright无需写一行代码,我们只需手动操作浏览器,它会录制我们的操作,然后自动生成代码脚本
输入如下命令
# 帮助命令
playwright codegen --help
# 尝试启动一个 Firefox 浏览器,然后将操作结果输出到 script.py 文件
playwright codegen -o script.py -b firefox
二、案例实现
1.思路
- 通过 playwright 打开浏览器来获取JavaScript渲染后的数据,从而绕过解密 JavaScript 加密的数据,跟 Selenium 一样的,都是模拟人为打开浏览器来获取数据。
2.引入库
代码如下(示例):
from playwright.sync_api import sync_playwright
from lxml import etree
import pymongo
# pymongo有自带的连接池和自动重连机制,但是仍需要捕捉AutoReconnect异常并重新发起请求。
from pymongo.errors import AutoReconnect
from retry import retry
# logging 用来输出信息
import logging
import time
# 开始时间
start = time.time()
# 日志输出格式
logging.basicConfig(level=logging.INFO,
format='%(asctime)s - %(levelname)s: %(message)s')
3.驱动浏览器进行访问
- 通过打开浏览器 访问 https://www.oklink.com/zh-cn/btc/tx-list?limit=100&pageNum=1然后获得网页源码,再将网页源码传入生成器中,便于下次调用
代码如下(示例):
BTC_URL = 'https://www.oklink.com/zh-cn/btc/tx-list?limit=100&pageNum={pageNum}'
def run(playwright):
# 驱动浏览器,并开启无头模式
browser = playwright.chromium.launch(headless=True)
# 打开窗口
page = browser.new_page()
for Num in range(1, 3):
# 触发 事件
page.on('response', on_response)
# 访问URL
page.goto(BTC_URL.format(pageNum=Num))
# 调用了 wait_for_load_state 方法等待页面某个状态完成,这里我们传入的 state 是 networkidle,也就是网络空闲状态
page.wait_for_load_state('networkidle')
# 生成器
yield page.content()
# html = page.content()
# Get_the_data(page.content())
# print(html)
browser.close()
4.触发事件
- on_response 方法是用于判断某一些请求( /api/explorer/v1/btc/transactionsNoRestrict )返回的状态是否为 200,如果是 200 ,就可以获取该请求返回的数据,也就是加密后的数据
代码如下(示例):
def on_response(response):
try:
# 筛选请求,并判断状态
if '/api/explorer/v1/btc/transactionsNoRestrict' in response.url and response.status == 200:
# 返回json格式数据
logging.info('get invalid status code %s while scraping %s',
response.status, response.url)
# data_set = response.json().get('data').get('hits')
# for item in data_set:
# Transaction_hashing = item.get('hash')
# The_block= item.get('blockHeight')
# print(Transaction_hashing)
# print(The_block)
return response.json()
if '/api/explorer/v1/btc/transactionsNoRestrict' in response.url and response.status != 200:
# 如果不是200就在日志里打印出响应码和链接
logging.error('get invalid status code %s while scraping %s',
response.status, response.url)
except Exception as e:
# exc_info为布尔值,如果该参数的值为True时,则会将异常信息添加到日志消息中;如果没有则会将None添加到日志信息中。
logging.error('error occurred while scraping %s',
response.url, exc_info=True)
5.获得数据
- 在前面我们已经通过 run()方法来获取到网页源码了,而我们想的数据也已经在网页源码,那就直接用 xpath 来获取数据吧
代码如下(示例):
def Get_the_data(html):
# 格式化源码
selector = etree.HTML(html)
data_set = selector.xpath(
'//*[@id="root"]/main/div/div[3]/div/div[2]/section/div/div/div/div/table/tbody/tr')[1:]
for data in data_set:
Transaction_hashing = data.xpath('td[1]/div/a/text()')[0]
The_block = data.xpath('td[2]/a/text()')[0]
Trading_hours = data.xpath('td[3]/div/span/text()')[0]
The_input = data.xpath('td[4]/span/text()')[0]
The_output = data.xpath('td[5]/span/text()')[0]
quantity = data.xpath('td[6]/span/span/text()')[0]
premium = data.xpath('td[7]/span/span/text()')[0]
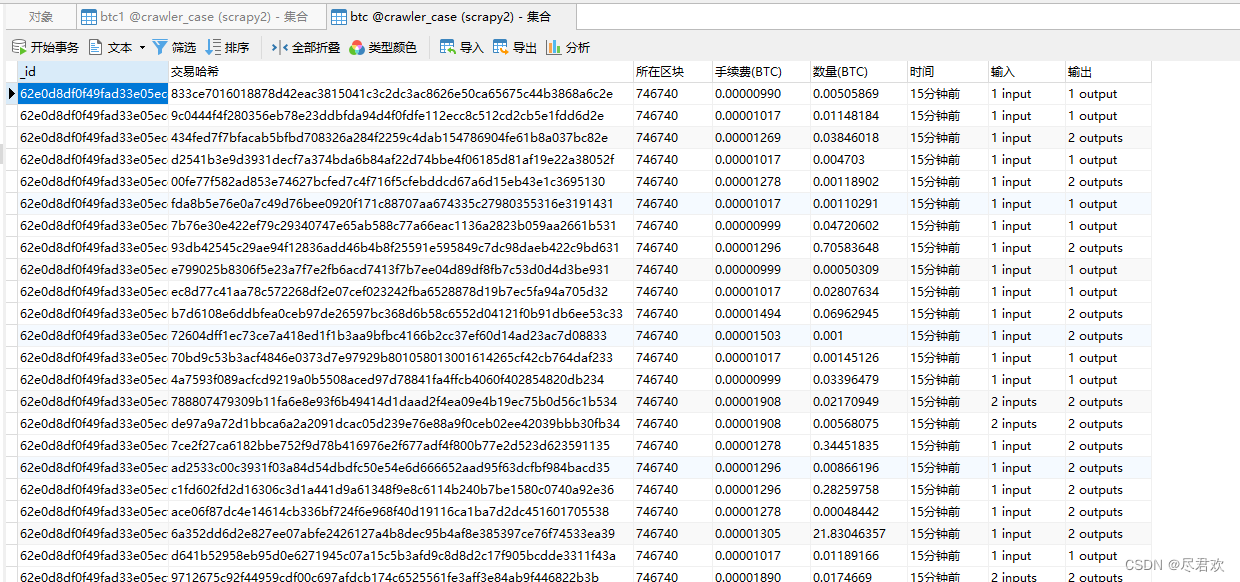
BTC_data = {
'交易哈希': Transaction_hashing,
'所在区块': The_block,
'交易时间': Trading_hours,
'输入': The_input,
'输出': The_output,
'数量(BTC)': quantity,
'手续费(BTC)': premium
}
yield BTC_data
6.保存数据到Mongodb
代码如下(示例):
@retry(AutoReconnect, tries=4, delay=1)
def save_data(data):
"""
将数据保存到 mongodb
使用 update_one() 方法第一个参数为查询的条件,第二个参数为要修改的字段。
upsert:
是一种特殊的更新,如果没有找到符合条件的更新条件的文档,就会以这个条件和更新文档为基础创建一个新的文档;如果找到了匹配的文档,就正常更新,upsert非常方便,不必预置集合,同一套代码既能用于创建文档又可以更新文档
"""
# 存在则更新,不存在则新建,
collection.update_one({
# 保证 数据 是唯一的
'交易哈希': data.get('交易哈希')
}, {
'$set': data
}, upsert=True)
7.调用方法
代码如下(示例):
with sync_playwright() as playwright:
for html in run(playwright):
for data in Get_the_data(html):
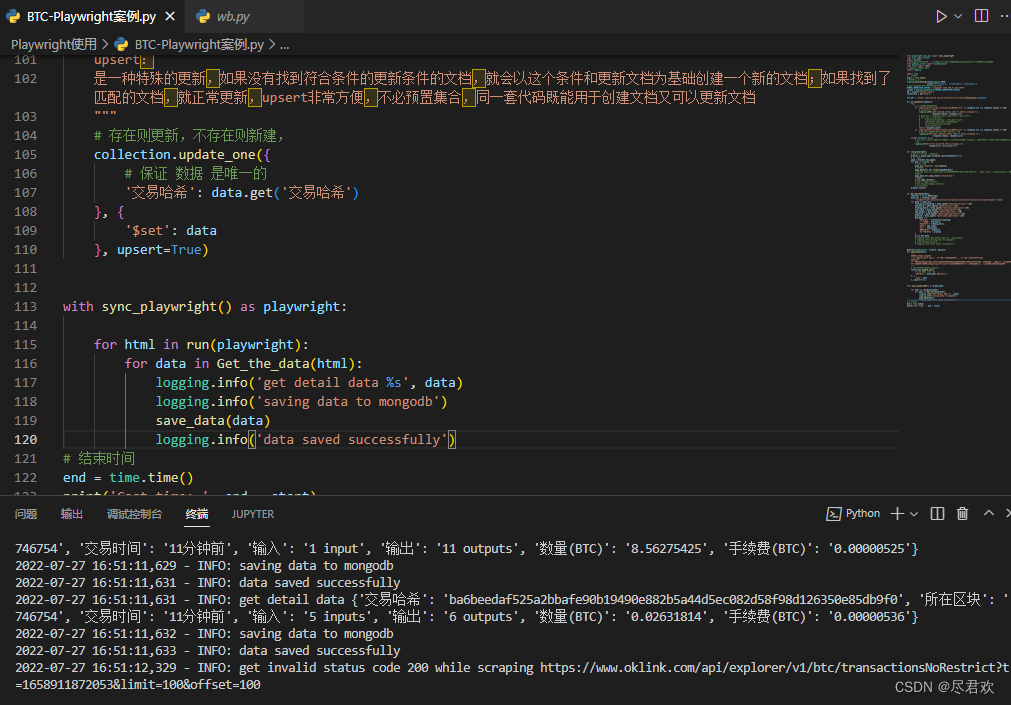
logging.info('get detail data %s', data)
logging.info('saving data to mongodb')
save_data(data)
logging.info('data saved successfully')
# 结束时间
end = time.time()
print('Cost time: ', end - start)
8.运行代码
总结
playwright相比已有的自动化测试工具有很多优势,比如:
- 跨浏览器,支持Chromium、Firefox、WebKit
- 跨操作系统,支持Linux、Mac、Windows
- 可提供录制生成代码功能,解放双手
目前移动端存在的缺点就是生态和文档还不是非常完备。