哈希表(Hash table),也称散列表,是一个能够将数值映射而成地址从而进行直接访问的数据结构,通过哈希表我们可以快速、迅捷地访问数据。
哈希表原理
假设我们拥有一个数x(也称关键值,key),那么我们可以通过哈希函数,将这个关键值x映射成一个数k,再将这个数k对应成一个表中的位置,那么我们就可以通过这个表来访问或者存储数据了。
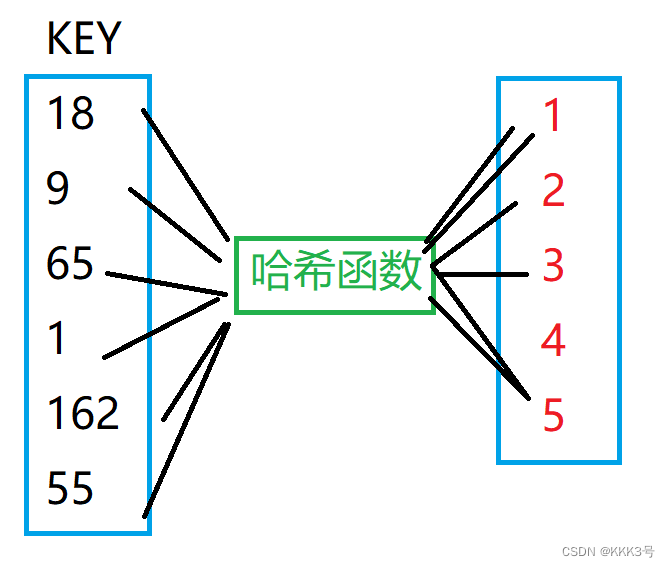
由此可以看出,我们想要创建一个哈希表,首先需要创建一个哈希函数。由上图可以知道,哈希函数主要功能是将一个关键值转换为一个地址,可以理解为一个多变少的过程,例如关键值x的范围假位于-到
之间,那么利用哈希的方式我们可以将这个关键值x的范围缩小到0~
。那么我们要想限制某个数取到一定的区间范围,那么我们自然而然想到取模操作。取模操作可以让限定一个数x变成比所取得模小的数。这里我们想将范围限定到1000以内。但是这里有个问题,如果我们限定关键值为范围-
到
,那么很大情况下多个数通过哈希函数映射出来的是一个数!
拉链法
拉链法原理
为此我们需要在每一个值k后面创建一个链表来存储这些相同映射的关键值,这种方式也称为拉链法。
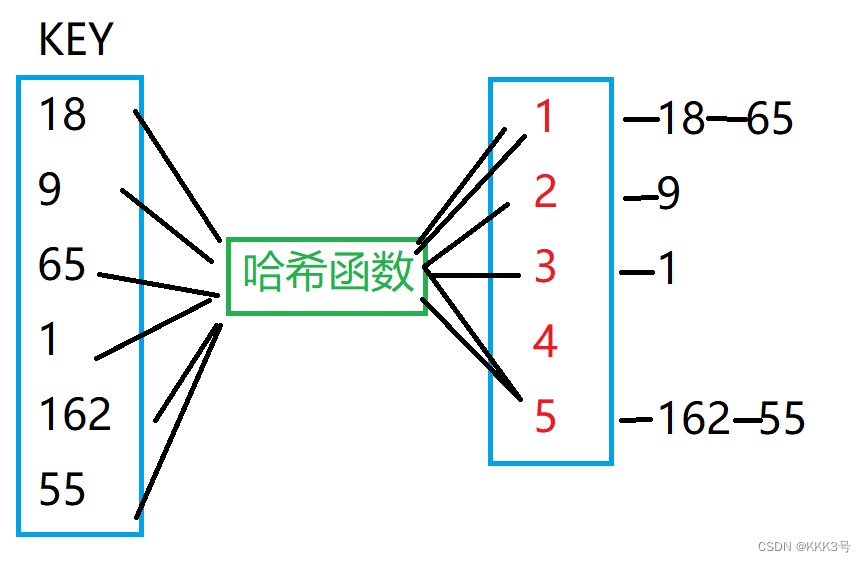
虽然有方法可以解决这个问题,但是我们还是需要尽量避免这种情况的发生,为此我们取需要一个靠近1000的质数N,这里求出来是1003。得到了这个数后,我们就用x除以这个数N取模。但是还有一个问题,我们尽量让取得模是正数,所以要关注关于负数的余数问题,即还需要将其负数的模转换为正数,为此我们将其模加上N本身再取模。
using namespace std;
const int N = 1003;
int Hash_func(int x)
{
return (x % N + N) % N;
}
哈希表插入(拉链法)
在此之后,我们就可以考虑如何插入一个数进哈希表了。首先我们需要有一个数组来存储所有我们可能映射出来的数k的集合。这里开辟一个数组h,因为我们设定最多只有1003个映射位置地址,所以这个数组也是大小为1003。那么我们存储过程就可以理解为在在这个数组下面挂上一串数据。例如我们有一个数据x,我们将其传入哈希函数后得到的位置为k,我们就找到在数组h种下标为k的位置 ,将这个数据挂在其下面,而“挂”的过程可以使用单链表来进行。

对应于代码,我们首先创建一个h数组、单链表指针数组Node、单链表数值数组val和当前下标index,然后获取地址值后在其下方创建一个节点即可,那么数组h[k]就对应单链表的头节点了。所以我们要对h数组所有值进行初始化,赋值为-1(因为单链表头节点在其它节点还没有创建的时候指向下标我们默认设置为-1)。
using namespace std;
const int N = 1003;
int h[N], Node[N],val[N],index;
void Insert(int x)
{
int n = Hash_func(x);
val[index] = x;
Node[index] = h[n];
h[n] = index;
index++;
}
int main()
{
memset(h, -1, sizeof(h));
return 0;
}哈希表查询(拉链法)
对于哈希表的查询操作,我们可以类似参考单链表的遍历查询。首先我们还是需要将需要查的数通过查哈希函数获取其对应的地址,然后在对应的地址下面遍历全部的节点。如果有节点的数值和所需要搜索的数值相同,那么我们就返回真;如果一直都找不到合适的数值,那么我们就返回假(即没有找到)。
bool find(int x)
{
int n = Hash_func(x);
for(int i =h[n];i!=-1;i=Node[i])
{
if (val[i] == x)
return true;
}
return false;
}开放寻址法
除了拉链法,我们还可以寻找另一种方法来解决哈希表的冲突,那就是开放寻址法。开放寻址法不同于拉链法在数组每一个元素后创建单链表来存储关键值。它只开辟一个数组,这个数组就可用来存储关键值,那它是如何处理哈希冲突的呢?
开放寻址法原理
首先我们开辟一个很大的数组,一般比预定最大大小还要大两三倍的数组。如果有一个关键值9,它通过哈希函数后得到的数是1,但是它查询后发现k=1的位置已经有一个哈希函数计算值也为1的关键值36占据了,那么它将会向后继续找空余的位置。而它后面是哈希函数值为2的关键值54,但是第三个位置是空的,那么它就可以存储在这里了。

同理,如果我们需要在这里寻找是否有某个数x,它的哈希函数计算值为1,那么我们就先通过哈希函数求得第一个满足哈希函数的关键值的在数组中的下标,然后找到这个值,将其与要求寻找的数x进行对比,如果不是就继续往后找,寻找有无和x相等的关键值,如果找到一个位置为空,那可以判断这个要找到值x不存在了。
下面我们用代码实现一下:
首先依旧是需要写一个哈希函数,并且创建一个一维数组,这里我创建比原来大两倍。但是这里有个问题,我们应该如何判断一个格子是否为空?因为一个数组会进行初始化,里面会存一些其它的数值。为此,我们决定利用一个在关键值的有效区间外的大数作为“空”的参照物。一开始这个数会充满整个一维数组,那么此时我们就可以认为这个数字“空”了。所以我们还设置了一个变量is_Empty。
#include<iostream>
#include<cstring>
using namespace std;
const int N = 2003, is_Empty = 10000;
int h[N];
int hash_func(int x)
{
return (x % N + N) % N;
}下面就是需要实现一个find函数,它起到的是查询操作。这里依旧是调用哈希函数获得地址,然后就是关键的一步,通过一个while循环来判断是否存在关键值x。while循环的终止条件有两个:一是我们找到了x(h[k]==x);二是h[k]的地方为“空”(里面存的是我们预设的大数),那么此时这个x就不存在了。如果找一遍都找不到,那么我们会选择将一个合适的空位返回去(而不是返回布尔变量之类的,这么做有利于我们后边的插入操作)。
int find(int x)
{
int k = hash_func(x);
while (h[k] != is_Empty && h[k] != x )
{
k++;
if (k == N)
k = 0;
}
return k;
}下面就是插入操作,由于我们之前设置find函数返回的是一个合适存储x的位置,所以Insert函数我们直接将这个值赋予给这个下标k的位置即可。
void Insert(int x)
{
int k = find(x);
h[k] = x;
}
总的代码:
#include<iostream>
#include<cstring>
using namespace std;
const int N = 2003, is_Empty = 10000;
int h[N];
int hash_func(int x)
{
return (x % N + N) % N;
}
int find(int x)
{
int k = hash_func(x);
while (h[k] != is_Empty && h[k] != x )
{
k++;
if (k == N)
k = 0;
}
return k;
}
void Insert(int x)
{
int k = find(x);
h[k] = x;
}
int main()
{
for (int i = 0; i < N; i++)
h[i] = is_Empty;
Insert(10);
return 0;
}参考资料