1.1引言
我印象最深的一句话就是:机器的分类能力比人强。
我们为什么要学习机器视觉?周志华教授开篇以西瓜的几个属性(比如色泽、根蒂、敲声)来判断一个西瓜是否是好瓜,这些都是靠人的经验完成的。
机器学习即是一门这样的学科,致力于研究通过计算机的手段,利用经验来改善系统自身性能。机器学习的主要研究内容:关于“学习算法”的学问。有了学习算法我们把经验数据传输给他,他就能产生出相对应的模型,在面对新的情况时,模型就会给我们提供一个相应的判断。
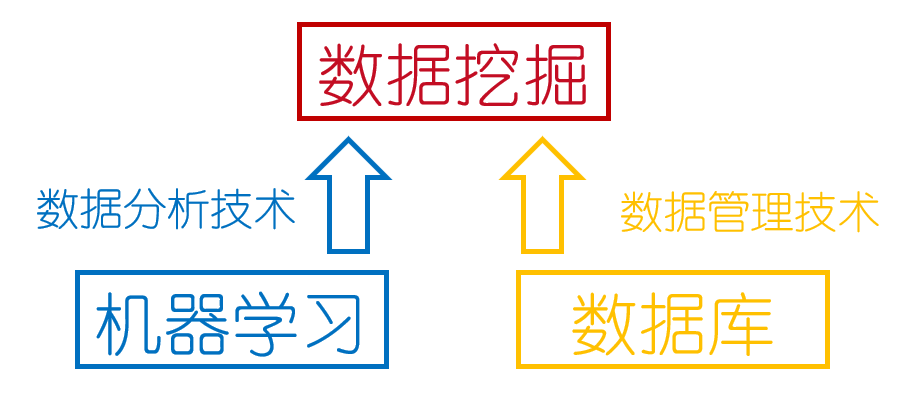
机器学习与数据挖掘的关系:很多人一开始被数据挖掘啊,大数据啊撩得眼花缭乱,其实本质上机器学习才是王。直接上图:
1.2基本术语
数据集:就是一组记录的组合,其中训练过程中使用的数据叫做训练数据,测试的叫做测试集,验证并达到调参目的的是验证集,与测试集不同的是,测试集主要是面对测试模型的性能及泛化能力的。
属性:或者叫做特征,反映事件或对象在某方面的表现或性质。
属性空间:属性作为坐标组成的一个多维空间。如一个西瓜的张成空间是:敲声、根蒂、色泽组成的三维坐标轴。这这里特别要注重理解空间的概念,矩阵理论中对空间的解释就非常到位。
分类:预测的目标是离散值的学习任务是分类,只有两个类别的叫做二分类。
回归:预测目标是连续值的学习任务是回归。
聚类:将目标数据集分为若干个互不相交的样本簇。
泛化能力:学得模型适用于新样本的能力。
假设空间:把学习过程看作为一个在所有假设组成的空间中进行搜索的过程,搜索目标是找到与训练集“匹配”的假设; 在这个假设空间中,可能有多个假设和训练集一致,我们称之为“版本空间”。
归纳偏好:机器学习算法在学习过程中对某种类型假设的偏好。或简称偏好 比如:上午复习数学,下午复习英语就是比上午复习英语下午复习数学要强。 当然,没有免费的午餐,当你运用某种归纳偏好可能对你目前的应用比较好,但是可能在另一方面就会有所缺失。

奥卡姆剃刀:是一种常用的、自然科学研究中最基本的原则,即“若有多个假设与观察一致,选最简单的那个”。
对于没有免费的午餐,我们来看下下面的讨论:


可以看出无论算法有多聪明,最后的期望性能竟然相同,但是别慌:NFL免费的午餐定理的前提条件是所有问题同等重要,所以说什么都要联系实际,实践是真理的唯一标准。
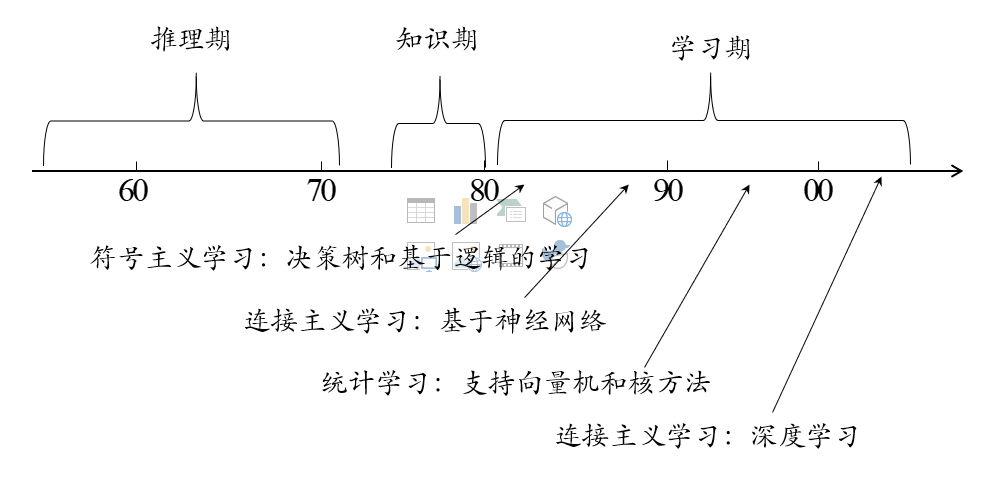
1.3发展历程
1.4应用现状


1.5阅读材料

