一。 什么是机器学习(Machine Learning)?
首先学习的对象是电脑
学习指的其实就是算法
机器学习就是基于数据基于算法从数据中去提炼对事物的认知和规律 掌握了这些特征和规律后就可以对新的事物去进行预测和判断
二。 什么叫训练,什么叫模型?
1. 训练是只有在监督学习中才有的概念,监督学习即家长告诉小孩这个动物叫啥,而与之对应的无监督学习就是小孩自发性对动物进行辨识和分类。
2. 口水话去解释:训练就是不断地试错,直至最优
3. 训练实质上是一种优化,提出一种模型,已知一组数据,定义一种代价函数(Cost Function 或者叫损失函数),然后用数学方法得到使得代价函数或损失函数最小的过程,也可以理解为优化参数
4. 比较专业的说法:根据已知数据寻找模型参数的过程就是训练,最终搜索到的映射被称为训练出来的模型。
5.机器学习中大概有如下步骤:
确定模型----训练模型----使用模型。
模型简单说可以理解为函数。
确定模型是说自己认为这些数据的特征符合哪个函数。
训练模型就是用已有的数据,通过一些方法(最优化或者其他方法)确定函数的参数,参数确定后的函数就是训练的结果
使用模型就是把新的数据代入函数求值
三。 什么叫监督学习(Supervised Learning)?
我们给算法一个包含了正确答案的数据集又叫训练集(Train set),算法的目的就是根据这些训练集得到一个模型然后用模型去预测一个新来的数据x他对应的答案y
简单来说监督学习中的训练集是这样的一些数据:这些数据的特征x和正确答案y都给我们了 我们通过他们去刻画一个预测模型
监督学习一般包含两类:
当y是连续值的叫Regression(回归):
举个例子我们想预测房屋价格y 这里特征x有很多比如x1是屋子大小 x2屋子地理位置 x3……
当特征很多(xi i=1,2,3……)时我们常用支持向量机svm(后面的章节安卓老师会介绍)来处理
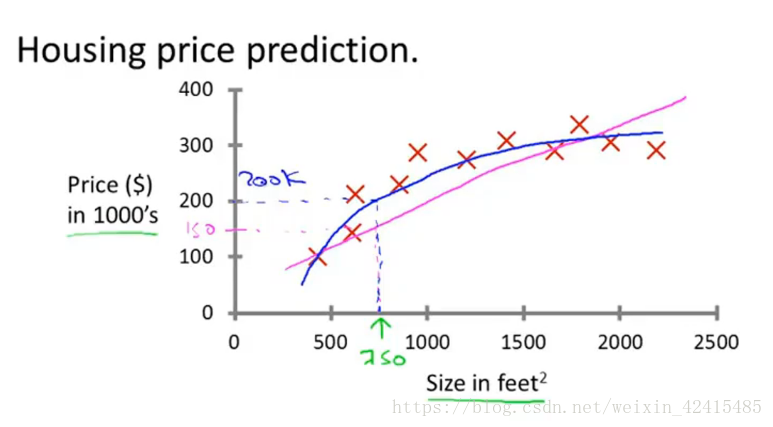
当y是离散值的如0/1(YES/no,boy/girl);1,2,3,4这种叫Classfication(分类):
肿瘤的良性恶性分类问题:

四。 什么叫无监督学习(Unsupervised Learning)?
即喂进去的数据只有x没有y
举例如下:
计算机自动根据数据的规律进行自动分类:(即没有人为固定规则)
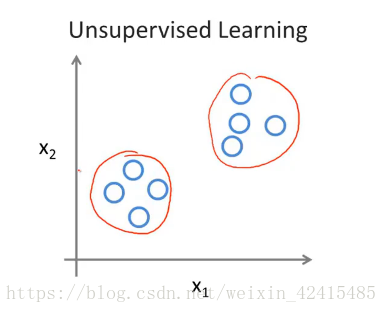
如google将新闻自动分类很多不同的组别(政治 体育 音乐 八卦……)
如鸡尾酒聚会的语音分离,这里区别他是无监督学习的关键是你事先并不知道这些交织在一起的语音中到底来自几个不同的声线
如聚类问题(如二分K均值)(注意区别聚类与分类:分类是监督学习如SVM)