前言:C++语法知识繁杂,要考虑的细节很多,要想学好C++一上来就啃书并不是一个很好的方法,书本的内容一般是比较严谨的,但对于初学者来说,很多概念无法理解,上来就可能被当头一棒。因此建议在学习C++之前学好C语言,再听听入门课程,C++有很多的语法概念是对C语言的一种补充,学习过C语言能更好的理解为什么要这样设计,笔者也是初学者,写的这类文章仅是用于笔记总结及对一些概念进行分析探讨,方便以后回忆,因知识有限,错误难以避免,欢迎大佬阅读指教
目录
引用
引用的定义
不知道你是否有被指针给绕晕的情况,尤其是想改变指针的内容,那就要传二级指针过去,在使用指针的时候还要解引用,用着用着就蒙了。有时候会想能不能不用传指针过去就能够改变原变量空间的值呢?C++给我们提供了一种功能——引用,或许能帮助我们解决上面的问题
引用其实就是给变量再重新取一个名字,引用并不会开辟一块新的空间,是和原变量同一块空间,就像叫你的小名和正式名,都是在叫你,总不能叫你的小名再叫你的正式名,就多出来一个你吧
引用在创建的时候,是必须要有对象的,否则是不能创建的,这个很容易理解,压根就没这个人的时候,又怎么给取其它名字呢,使用引用时用符号 '&',一块空间可以引用多次,也就是有多个别名

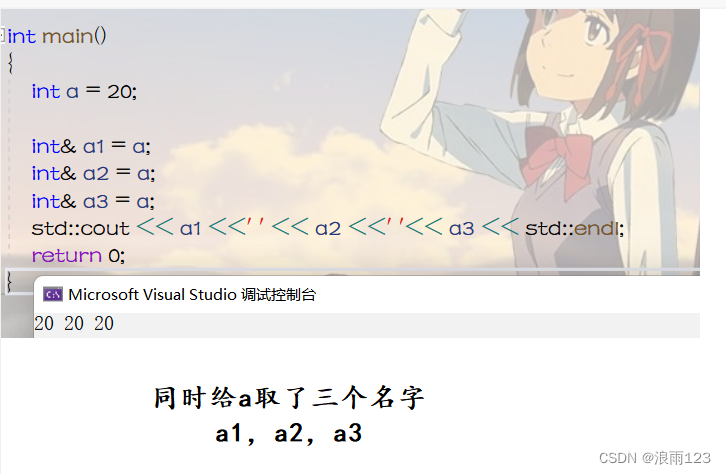
引用的用法
1.引用作为函数定义时的参数
这样使用有类似指针的效果,不需要传指针过去,就能够改变原变量的值

这样就不怕被指针给绕晕,还减少了空间的开辟,效率有所提高
使用引用时要注意权限的问题,在引用赋值中,权力可以缩小,但是不能扩大
int main()
{
int a = 20;
int& ta = a; //权限平移,不变
const int b = 10;
int& tb = b; //这里的tb的权限是高于b的,tb是左值,而b是右值
//tb的权限扩大了。不可以
const int b = 10;
const int& mb = b; //这样权限就是相等的
int b = 10;
const int& nb = b; //这里tb的权限缩小了,这样是可以的
return 0;
}2.引用作为函数的返回值
引用作为函数返回值是有前提条件的,我们都知道函数在创建的时候会开辟一个栈帧,调用结束后,栈帧会被销毁,内存返还给操作系统,既然栈里的内容都被销毁了,那么函数的返回值该怎么处理呢,事实上,函数调用结束后,如果有返回值,那么在栈帧销毁前,还会创建一个临时变量,用来保存最后的返回值

问题的关键是,返回引用,返回的就是一个名字而已 ,引用指向的对象是在这个栈帧里的,栈帧一旦被销毁了,那么你返回一个名字又有什么用呢?这块空间已经不属于你了,就像有些人离开了这个世界,喊它的名字,它再也不会出现
想要返回引用,那就要确保引用的对象在栈销毁后不会消失,比如静态区的全局变量以及堆区的变量,不过好处就是引用作为返回值效率是比传值高的
引用作为返回值出错情况
如果引用的对象的声明周期在栈中,那么在栈帧销毁后,再次使用引用变量会发生什么呢
1.已被销毁的栈帧未来得及清理,那么有可能返回原来的值
2.被销毁的栈帧已经被清理了,那么返回的就是随机值
3.栈帧被销毁后,又开辟了其他的栈帧,已销毁的栈帧的数据被新开的栈帧的数据覆盖
int& test(int x, int y)
{
int c = x + y;
return c;
}
int main()
{
int& tmp = test(3, 4);
test(10, 10);//再次调用后,就会将原先栈帧内的数据覆盖掉
std::cout << tmp << std::endl;
return 0;
}
引用与指针的区别
1.指针的开辟是单独开辟一块空间,空间里存着指向对象的地址,而引用的开辟并没有单独开辟一块新空间,而是和原变量同一块空间
2.引用在定义是必须要初始化,而指针没有要求
3.引用在指定对象之后,就不能够再更换,而指针是可以更换的
4.在sizeof()中的含义不同,引用则表示对象的大小,而指针的大小是有硬件决定的
5.指针访问实体需要解引用,引用则是由编译器来实现
6.有多级指针,但是没有多级引用
7.引用自加即引用的实体增加1,指针自加即指针向后偏移一个类型的大小
内联函数
内联函数的定义
什么是内联函数呢?在说内联函数之前,不妨先回忆一下C语言的宏定义函数,我们知道C语言的宏函数在预编译阶段就完成替换,省去了在栈中开辟函数的花销,运行速度也是刷刷的快。但是吧,宏函数的缺点也是很明显,首先就是不能够调试,还有就是容易引起歧义,要加不少的括号,阅读这种代码也非轻松之事,这些缺点也表明这是大佬的写法,为了更清晰的观察宏函数的缺点,我们写一个简单的宏函数来分析
#include<stdio.h>
#define Add(x, y) ((x)*3 + (y))
int main()
{
int a = 10;
int b = 20;
int c = Add(a, b);
printf("%d ", c);
}
#include<stdio.h>
#define Add(x, y) ((x)*3 + (y))
int main()
{
//如果不给x加括号, (x*3 + (y)) 其传过去一个表达式,比如Add( 1+5, 10)
int c = Add(1+5, 10);
//那么在定义替换时将会是这样 ( 1 + 5 *3 + (10) ) 这就产生了歧义
printf("%d ", c);
//如果把最外面的大括号去掉, (x)*3 + (y) 然后调用之后乘以3
int c = Add(5, 10) *3;
//那么在定义替换时将会是这样 (5) *3 + (10) *3 这就又产生了歧义
printf("%d ", c);
}
由上面的例子,我们能发现,宏函数任何一对括号可能都是有道理的,这就导致写不好写,看不好看,还不能调试,可即使缺点不少,仍耐不住它快这个优点,要是宏函数能像普通函数一样可以调试,不用注意那么多细节就好了。还真有!大佬们在C++中加入了内联函数这个概念就是为了解决这种问题,内联函数就是在定义普通函数时加上关键字 inline ,加上这个关键字之后,你可以接着编写你的函数,其他的不用管,当编译器识别到 inline 时,会考虑将你编写的这个函数给优化成宏函数,注意:加上inline只是建议编译器将其优化成宏函数,并不是一定会优化成,如果你的函数很长很复杂,本身就不适合转换成宏,那么编译器可以选择忽略建议
内联函数需要注意的点
所以说内联函数适合短小简明的函数,有效利用才会提高效率,事实上,如果你频繁调用某个内联函数,那么内联函数可能就是在用空间换取时间了,什么意思呢?接着用刚才的那个例子来看看
#include<iostream>
using namespace std;
inline int Add(int x, int y)
{
return x+y;
)
int add(int x, int y)
{
return x+y;
}
int main()
{
int c = Add(10, 10);
int d = Add(10, 10);
int e = Add(10, 10);
int f = Add(10, 10);
int g = Add(10, 10);
int h = Add(10, 10);
int i = Add(10, 10);
int j = Add(10, 10);
int k = Add(10, 10);
}
分别用内联函数和普通函数实现两数相加,因为内联函数会将其优化成宏函数,在编译的时候全部展开到调用函数的地方。我们写的比较简单,假设 Add 和 add 里面都有10个语句,同时调用两个函数各一万次,那么内联函数在展开时,总共有1w * 10 个语句,而普通函数则有1w + 10 个语句,显然内联函数的代码所占用的空间是更多的,不过其速度仍然是很快
内联函数的声明和定义是不能够分开的,什么意思呢?我们平时喜欢把函数的声明放在头文件里,然后函数的实现放在另一个头文件里,但对于内联函数来说,这样分开放是不行的,声明和定义须放在一起,为什么呢?
原先你在 test_a.h 中声明一个函数,在test_b.c中定义该声明的函数, 在test_c.c中调用这个函数,但是这三个文件是独立的,彼此都不认识彼此,最终又是如何在调用的时候找到函数定义的呢?
还记得我们之前提到过,C/C++在编译阶段,每个文件在编译的时候都会进行词法和句法的分析,将定义的符号提取生成一张符号表,函数名或者函数的地址都放到这张符号表上,比如test_a.h 中只有函数的声明,没有函数的定义,那生成的符号表,在函数地址那一块就是无效的,不过之后会再进行链接,将生成的多个符号表进行合并,合并后会保留有效的函数名和有效的函数地址,通过最终的这个符号表就能够找到函数的定义和函数的声明
一般函数都是按上面的方法编译的,但是宏函数不一样,因为宏函数是在预编译阶段就完成替换,就相当于把函数的代码直接展开到调用处,不需要在栈区开一个栈帧,不需要函数地址,因此宏函数的函数名是不会放到符号表中的,而内联函数的目的就是建议将该函数转化成宏函数,所以,无论这个函数最终有没有被替换成宏 ,只要加上 inline 它都不会在符号表中出现
假如你在 test_a.h 中声明一个内联函数 inline int Add( int x, int y),在test_b.c中定义 inline int Add(int x, int y ),然后在test_c.c中调用 Add(10, 10 ) ,这个时候编译器就会报未定义的错误
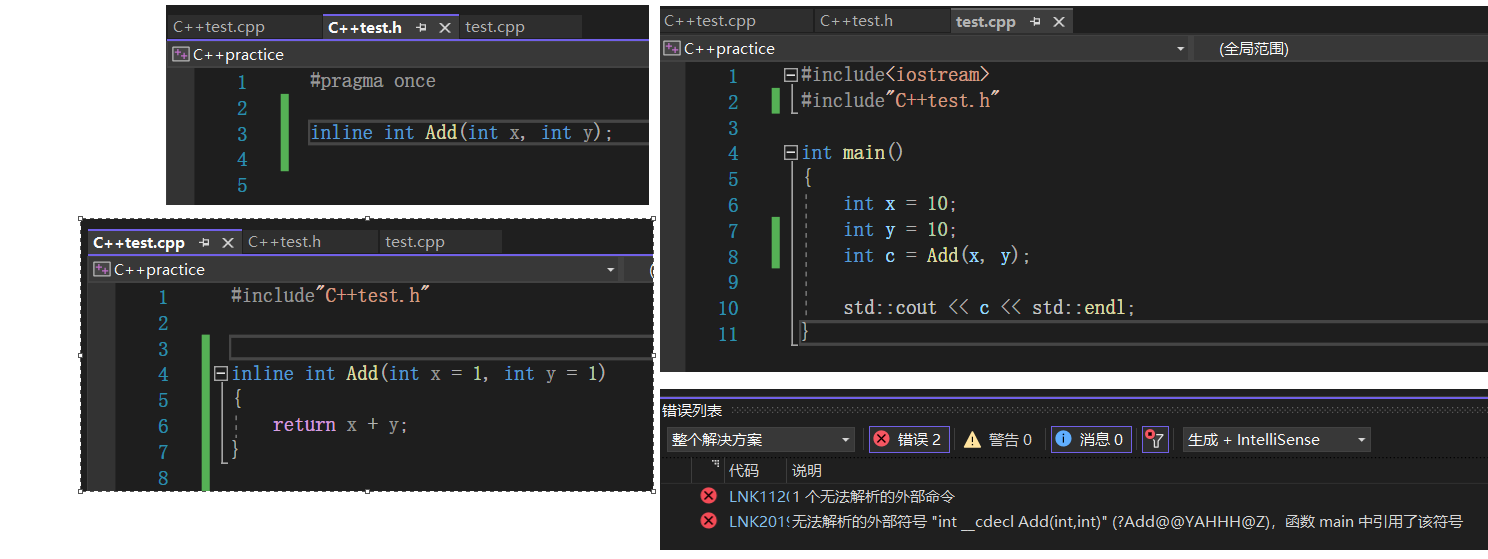
因为内联函数不会进入到符号表,而main函数只包含了声明文件 "C++test.h",也就是说main函数会通过这个函数的声明去符号表里查找这个函数,当然是查找不到的了,所以就报了未定义的错误,如果我们直接包含" C++test.cpp" 这个函数就能够跑起来,因为" C++test.cpp"的内容会直接展开到main这个文件里,所以在定义内联函数时,不要将定义和声明分离开,需要写在一起