第三章–卷积神经网络
3.1-卷积神经网络的结构
卷积神经网络由输入层、卷积层、池化层、全连接层和输出层组成。通过增加卷积层和池化层可以得到更加深层次的网络,其后的全连接层也可以用多层结构。
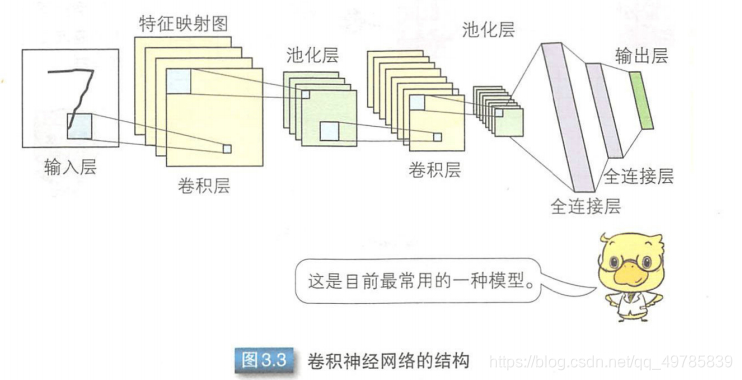
那么这么多不同的层,他们的作用分别是什么呢?
3.2–卷积层
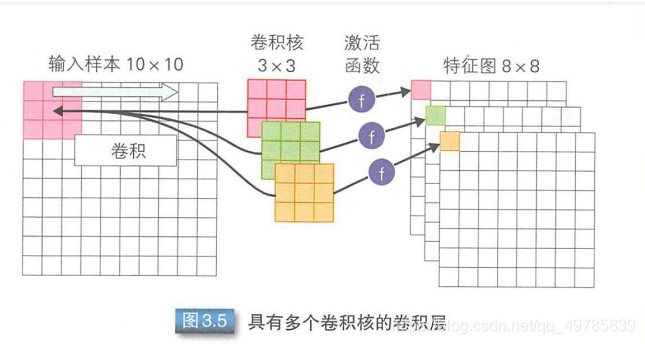
卷积层所做的工作就是将输入样本和卷积核内积,在该操作之后可以得到特征图。但是卷积的结果不能直接作为特征图,而是需要激活函数计算后,把函数输出结果作为特征图。特征图的个数取决于卷积核的个数。
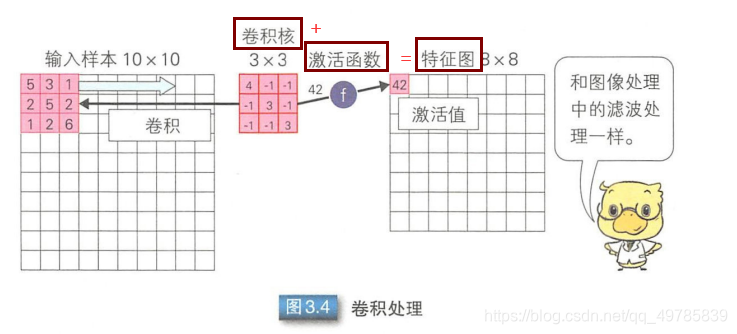
当用三个卷积核时,就会得到三个特征图:
3.3–池化层
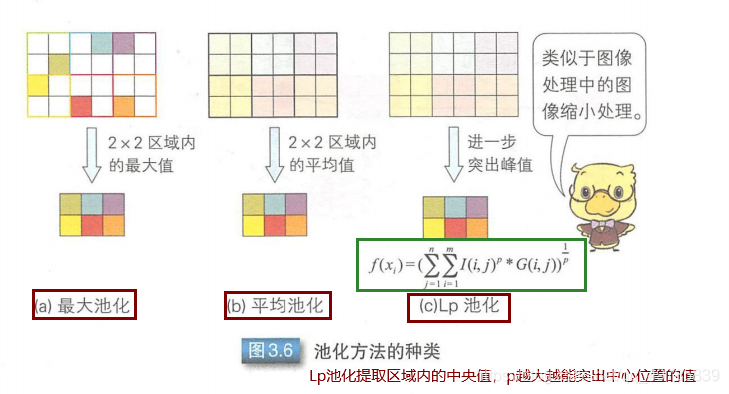
池化层的作用时减小卷积层产生的特征图的尺寸。选取一个区域根据该区域的特征图信息得到新的特征图,这个过程就是池化操作。最为熟悉的就是最大池化,提取选取图像区域内最大值作为新的特征图,此外还有平均池化、Lp池化等等。
3.4–全连接层
全连接层就是先计算激活值,然后通过激活函数计算各单元的输出值。全连接层的输入就是卷积层或者池化层的输出,将其展平然后进行计算。

3.5–输出层
对于分类问题,输出层使用似然函数计算各类别的似然概率;
对于回归问题,输出层使用线性输出函数计算输出值。
3.6–神经网络的训练方法
3.6.1–误差更新方法
卷积神经网络的参数包括卷积核大小、全连接层的W和b。卷积神经网络的参数训练也是采用误差反向传播的方式更新参数。全连接层的权重前面介绍过了,这里介绍一下池化层和卷积层的参数训练方式。
- 池化层的误差反向传播
无论max pooling还是mean pooling,都没有需要学习的参数。因此,在卷积神经网络的训练中,Pooling层需要做的仅仅是将误差项传递到上一层,而没有梯度的计算。
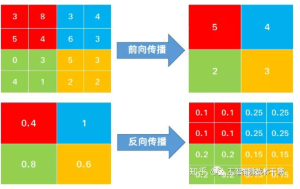
(1)max pooling层:对于max pooling,下一层的误差项的值会原封不动的传递到上一层对应区块中的最大值所对应的神经元,而其他神经元的误差项的值都是0;
(2)mean pooling层:对于mean pooling,下一层的误差项的值会平均分配到上一层对应区块中的所有神经元。
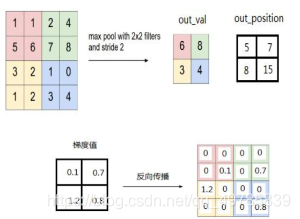
池化层在反向传播时,它是不可导的,因为它是对特征图进行下采样会导致特征图变小,两层之间经过池化操作后,特征图尺寸改变,无法一一对应,这使得梯度无法按位传播。那么如何解决池化层不可导但却要参与反向传播呢?
在反向传播时,梯度是按位传播的,那么,一个解决方法,就是如何构造按位的问题,但一定要遵守传播梯度总和保持不变的原则。
对于平均池化,其前向传播是取某特征区域的平均值进行输出,这个区域的每一个神经元都是有参与前向传播了的,因此,在反向传播时,框架需要将梯度平均分配给每一个神经元再进行反向传播。
- 卷积层的误差反向传播
卷积层改写成全连接层,可以把卷积层理解为与特定单元相连接的全连接层,这样就可以计算梯度并进行误差的反向传播。把卷积核的元素看成是权重,把卷积核的所有元素进行梯度计算。把卷积层的卷积核看 全连接层后,就可以根据单元的调整值来调整卷积核元素。
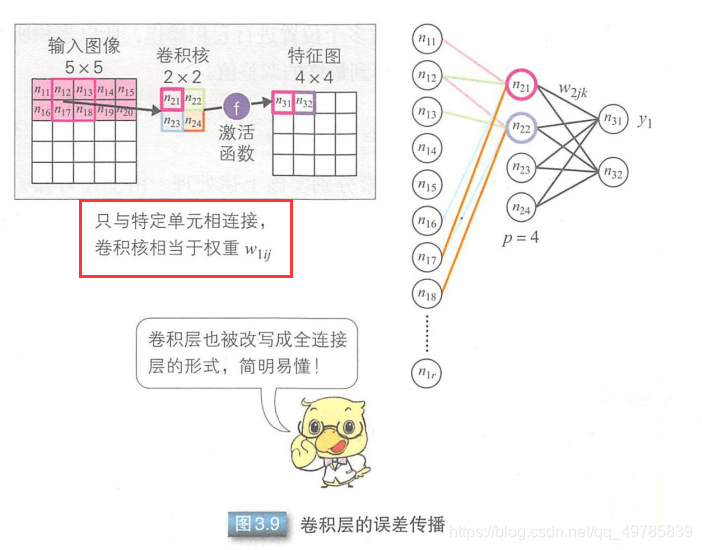
3.6.2–参数的设定方法
与神经网络相关的参数有:
·卷积层的卷积核大小、卷积核个数
·激活函数的种类
·池化方法的种类
·网络的层结构(卷积层的个数、全连接层的个数等)
·全连接层的个数
·Dropout的概率
·有无预处理
·有无归一化
与训练有关的参数如下所示:
·Mini-Batch的大小
·学习率
·迭代次数
·有无预训练
最好的状态是从这些参数中选择最优的组合进行训练,这些参数我们只能根据经验来确定。
经过实验发现:
·卷积核大小不会对误识别率产生显著影响;
·卷积核在每一层采用大小相同的卷积核时,越多识别性能越好;在逐层递增的形式中,随着层数的增加,识别性能越好;
·激活函数RELU效果最好
·增加全连接层或者有无全连接层都没有什么效果;
·有预处理效果更好,尤其是归一化和ZCA白化组合可以很好的提升识别性能;
·使用dropout可以提升性能;
·学习率、Mini-Batch大小对识别性能没有明显效果;
·有无归一化也不会产生明显性能提升效果。
3.7–总结
卷积神经网络能够通过卷积层和池化层使得特征映射具有位移不变性和多层感知器一样,卷积神经网络的训练也是使用误差反向传播算法,卷积层和池化层都可以使用误反向传播算法进行训练在比较不同的数设定后,我发现近年来提出的激活函数和 Dropout等技术能够提高网络的泛化能力。与多层感知器相比,卷积神经网络的参数更少,不容易发生过拟合,因而网络的泛化能力能够得以提高。