简介
Jaccard相似性是一种常见的接近度测量,用于计算两个对象之间的相似性,例如两个文本文件。Jaccard相似性可以用来寻找两个二进制向量之间的相似性,或者寻找两个集合之间的相似性。在需要度量二进制变量之间的相似程度,Jaccard便是可用的度量之一。
它常被用于以下场景:
文本挖掘:根据两个文本文件中使用相同术语数量,找到两个文本文件之间的相似度
电子商务:从一个有数千名顾客和数百万件商品的市场数据库中,通过他们的购买历史找到相似的顾客
推荐系统: 电影推荐算法采用Jaccard系数来寻找相似的客户。

计算
对于集合来说,它的计算公式如下
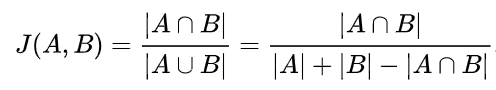

对于二进制变量来说,有对称和非对称两种计算方式,但是普遍使用的是非对称的计算方式:
a: A==1&B==1的元素数量
b: A==1&B==0的元素数量
c: A==0&B==1的元素数量
d: A==0&B==0的元素数量
其中非对称的算法:
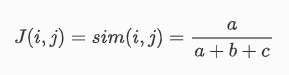
对称算法是将d加入到分子分母。这里并将未d考虑在内,原因是我们只对同为1的元素感兴趣,如果同为0的元素如果过多,分母太大则会稀释结果使其不敏感。例如想考察两个顾客超市购买物品的相似性,超市可能有成千上万种物品,对于两个顾客来说大部分未购买(值为0),如果将其纳入计算,会使得不准确。
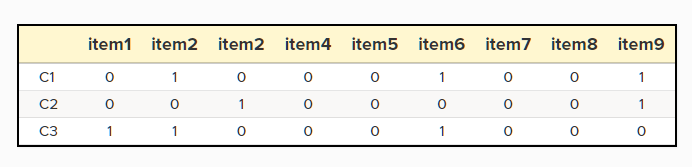
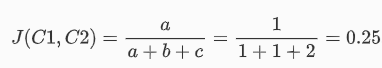

另外一个经常用的指数就是Dice,它的计算将a的权重增加,a替换为2a即可。由于计算时权重增加,Dice比Jaccard获得的相似性更高,距离更小。Dice和Jaccard可以直接换算:
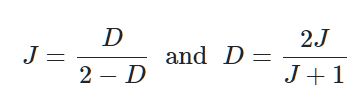
在实际计算中的是非相似性(也就是距离),获得的值相当于1-J或者1-D
mat = matrix(c(1, rep(0, 9), rep(1, 4), rep(0, 6)), ncol = 2)
> mat
[,1] [,2]
[1,] 1 1
[2,] 0 1
[3,] 0 1
[4,] 0 1
[5,] 0 0
[6,] 0 0
[7,] 0 0
[8,] 0 0
[9,] 0 0
[10,] 0 0
stats::dist(t(mat), method='binary') #需要转置
1
2 0.75
arules::dissimilarity(t(mat), method = 'jaccard')
1 2
1 0.00 0.75
2 0.75 0.00
arules::dissimilarity(t(mat), method = 'dice')
1 2
1 0.0 0.6
2 0.6 0.0参考资料:
https://stats.stackexchange.com/questions/238684/what-are-the-difference-between-dice-jaccard-and-overlap-coefficients
https://www.learndatasci.com/glossary/jaccard-similarity/

