文章目录
- 1.语义级业务过程模型相似性度量技术2016
- 2.How to Make Process Model Matching Work Better? An Analysis of Current Similarity Measures2017
- 3.Similarity of Business Process Models:Metrics and Evaluation 2011
- 4.基于变迁标签图编辑距离的过程模型相似性度量2016
- 5.基于任务发生关系的流程模型相似性度量2017
- 6.Measuring Similarity between Semantic Business Process Models2007
1.语义级业务过程模型相似性度量技术2016
业务过程相似性度量的研究主要集中在元素标签、模型逻辑结构和行为语义3个方面的比较。

实际业务过程模型比较中,完全相同或完全不同的模型比较少见,更多的情况是似是而非,即两个模型具有一定的相似性,因此进程代数研究的等价概念无法区分“非常相似”和
“有点相似”的差异。
活动标签作为模型相似度判断的依据,两个模型中标签相同的活动越多,模型相似度越大,反之越小。该算法具有易于实现和计算速度快的优点,但没有体现过程模型的结构性差异。
Minor提出的度量用出现在两个模型间的节点和边数量以及两个模型的节点和边的总数计算,该方法假设只有当两个节点具有相同标签时才是相同的,因此无法处理标签语义异构问题。
而图编辑距离主要考查图形结构的差异性,缺少对业务过程行为信息的表述和分析。
在实际中,大型组织的业务过程模型规模庞大,往往涉及多个专业领域,需要大量人员共同建模。然而建模人员的背景知识不同,模型之间存在大量的同形异义词和异形同义词,这种过程模型的语义异构问题在引入参考模型的建模过程中尤为突出。因此基于公共术语集的模型相似性度量过于理想化,很难应用于企业实际模型库。
2.How to Make Process Model Matching Work Better? An Analysis of Current Similarity Measures2017
过程模型匹配是指自动识别两个过程模型之间的相应活动,即代表相同或相似行为的活动。通过自动产生这种活动对应关系,过程模型匹配技术是许多高级分析技术的先决条件。除其他外,活动对应的标识对于协调流程模型变体[1,2],流程模型搜索[3,4]和检测流程模型克隆[5,6]是必需的。
先对过程模型匹配进行结构化文献综述。我们概述了现有技术及其用于识别类似活动的特定技术。
过程模型匹配问题
流程模型匹配技术旨在自动识别代表两种模型中相似行为的活动对应。图1通过显示来自两个不同公司的招聘过程来说明匹配问题。灰色阴影突出显示了两个过程之间的对应关系。例如,来自公司B的活动“评估”对应于来自公司A的活动“检查等级”和“检查就业参考”。这些对应关系表明,这两种模型所使用的术语有所不同(例如,“资格评估”对比“能力测试”)及其详细程度(例如,“评估”在公司A的模型中有更详细的描述)。鉴于这些差异,正确识别两个过程模型之间的对应关系可能会成为一项复杂而具有挑战性的任务。适中的性能也突出了匹配任务的复杂性。

按照Gal [14],我们可以将匹配过程细分为第一行匹配和第二行匹配。第一行匹配器将过程模型中的活动A1和A2集作为输入,并生成具有| A1 |的相似性矩阵M(A1,A2)。行和
| A2 |列。其中,可以通过比较活动标签来获得这种相似性矩阵。第二行匹配器将由第一行匹配器产生的一个或多个相似性矩阵作为输入,并将它们转换为条目为0或1的二进制相似性矩阵M(A1,A2)。后者表示两个活动之间的对应关系。重要的是要注意,第一行匹配对于整体匹配结果起着特别重要的作用。如果第一行匹配器为两个活动计算相似度为零,那么第二行匹配器将不太可能在最终的一组对应关系中包含该特定活动对。

采用两个过程模型作为输入并在某个阶段产生一组活动对应关系。
表1中的每一行都列出了一种用于识别活动对应关系的度量类型。 “总计”列指示使用相应度量类型的匹配系统总数,“参考”列显示讨论这些匹配系统的论文。总体而言,表1显示了我们总共确定了10种量度类型,将其分为句法和语义量度

句法度量
句法量度与简单的字符串比较有关,并且不考虑单词的含义或上下文。运用最广泛的句法量度是基于距离的量度,例如Levenshtein距离。给定两个标签l1和l2,Levenshtein距离计算将l1转换为l2所需的编辑操作(即插入,删除和替换)的数量。另一个基于距离的度量是JaroWinkler距离,它的工作方式类似,但是产生的值介于0和1之间。
除了基于距离的度量外,许多匹配系统还依赖于纯字比较。非常常见的度量包括Jaccard和Dice系数,它们均基于共享和非共享单词的数量来计算两个活动标签之间的相似度。
基于单词比较的另一种方法是余弦相似度。为了计算余弦相似度,通常通过将单词的出现频率加权来将其转换为矢量。然后,通过两个活动矢量之间的角度的余弦来给出余弦相似度。
考虑单词分布的另一种方法是Jensen-Shannon距离,这是一种用于测量两个概率分布的相似性的方法。但是,到目前为止,它仅被Weidlich等人的方法采用。 [30]。
常见的预处理步骤是考虑活动之间的子字符串关系。例如,Dadashina等。如果l1是l2的子字符串,则认为两个活动标签l1和l2相似(反之亦然)[12]。然后,将此类标签从其他相似性考虑因素中删除,并且仅获得相似性得分1。
语义度量
语义度量旨在考虑单词的含义。这样做的一种非常常见的策略是使用词汇数据库WordNet [35]来识别同义词。通常,匹配系统在预设步骤中检查同义词,然后应用其他(通常也是句法)相似性度量[12]。
最突出的语义度量是Lin相似度。 Lin相似度是一种根据WordNet分类法根据单词的信息内容来计算单词的语义相关性的方法。为了使用Lin相似度来度量两个活动(大多数活动包含多个单词)之间的相似度,通常将Lin相似度与词袋模型结合使用。
词袋模型将活动转换为单词的多个集合,而忽略了语法和单词顺序。然后可以通过从具有最高Lin得分的两个袋子中识别单词对并计算它们的平均值来获得Lin相似性。基于WordNet词典的其他度量包括Wu&Palmer和Lesk。前者通过考虑WordNet分类法中两个单词之间的路径长度来计算两个单词之间的相似度。后者比较两个单词的WordNet词典定义。一些方法还直接检查上位词的关系(上位词是更常见的词)。例如,Hake等。 [12]将“汽车”和“车辆”视为相同的词,因为“车辆”是“汽车”的上位词。
句法度量起着主要的作用。如距离度量。基于编辑的距离量度的缺点不仅在于它们无法识别同义词,还在于它们倾向于将无关的词视为相似。例如,考虑不相关的单词“合同”和“联系”。这些词之间的Levenshtein距离仅为1,表明这些词之间的相似度很高。
最突出使用的句法和语义测度(即Levenshtein距离和基于词袋的Lin相似度)。计算对应关系的匹配度。
未来工作
- 仅将语法技术用于预处理:语法技术对于识别平凡或几乎平凡的对应关系非常有用。我们发现性能最好的系统主要使用语法技术作为预处理步骤:它们首先匹配相同且几乎相同的标签,然后应用语义技术。
3.Similarity of Business Process Models:Metrics and Evaluation 2011
==在相似性度量方面做出了很多研究,提出了较多的相似性度量算法,最简单的一种叫标签对齐的相似性度量算法.==提出一种用因果足迹(casualfootprints,CF)计算相似性的方法,该算法的主要思路是把过程模型用向量表示,但是由于向量中有过多的冗余信息,因此高维度的向量导致计算非常低效.
大型和复杂的组织通常会维护业务流程模型的存储库,以便记录并不断改善其运营。本文将解决在存储库中检索最类似于给定过程模型或其片段的那些过程模型的问题。(通过存储库搜索相似的业务流程模型)
提出了三个相似性度量:
- 标签匹配相似性,用于比较附加到过程模型元素的标签;
- 比较元素标签和过程模型拓扑的结构相似性;
- 行为相似性,用于比较元素标签以及过程模型中捕获的因果关系。
这些相似性度量是根据准确性和查全率以及度量与人类判断的相关性进行实验评估的。实验结果表明,所有三个指标均产生可比较的结果,结构相似性略好于其他两个指标。
意义
大型过程模型存储库的管理和使用需要有效的搜索技术。例如,在将新的流程模型添加到存储库之前,需要检查是否还没有类似的模型以防止重复。同样,在公司合并的背景下,流程分析师需要确定通用或相似的业务流程来分析它们的重叠并确定合并的领域。
这些任务要求用户根据与给定“搜索模型”的相似性来检索过程模型。我们使用术语过程模型相似性查询来指代过程模型存储库中的此类搜索查询。
传统的搜索引擎基于关键字搜索和文本相似性。它们没有考虑过程模型的结构和行为语义。
本文研究了旨在回答流程模型相似性查询的三个相似性指标。
- 第一个指标是基于标签的指标。它利用了过程模型由标记节点组成的事实。度量标准通过比较过程标签之间的计算来计算过程模型中节点之间的最佳匹配。基于此匹配,在考虑模型的整体大小的情况下计算相似性得分。
- 第二个指标是结构指标。它使用现有技术基于图编辑距离[2]进行图比较。此度量标准同时考虑了节点标签和流程模型的拓扑。
- 第三个指标是行为。它考虑了流程模型的行为语义,特别是流程模型中活动之间的因果关系。这些因果关系以因果足迹的形式表示[3]。
评估有两种方式:
- 首先使用精度和召回率的经典概念,
- 其次通过计算每个度量给出的相似性得分与人类专家给出的相似性得分之间的统计相关性。
评估结果表明,考虑到流程模型的结构和行为的相似性指标在回答流程模型相似性查询方面优于搜索引擎。
EPC
在业务流程建模领域中,有许多符号竞争,包括UML活动图,业务流程建模符号(BPMN),事件驱动的流程链(EPC),工作流网等。在本文中,我们使用EPC作为过程建模符号。

许多大型过程模型存储库都可以用作EPC。特别是,我们在实验中使用的存储库由EPC组成。本文定义的标签相似性度量标准与所使用的特定过程建模符号无关,而结构相似性度量标准可以应用于任何基于图的过程建模符号,并且行为相似性度量标准也可用于可以映射到因果足迹的任何符号。
EPC表示法是一种基于图的语言,用于记录组织中功能和事件之间的时间和逻辑依赖性。
因果图是一组活动以及这些活动何时发生的条件。因果足迹保持相对较小的业务过程模型。因果足迹有回溯和超前连接,如(a, B) ,a发生会导致B,这是超前,(A, b)是b发生,前面一定有A发生。
因果图和因果足迹。
例如,图1中EPC的可能因果足迹包括前瞻链接(“收货”,{‘验证发票’,‘转移到仓库’})和回溯链接({‘收货’},'验证发票”)和({‘收货’},“转移至仓库”)。此示例说明了因果足迹是EPC行为的近似值,因为存在多个具有相同因果足迹的EPC(例如,可以通过在XOR-分裂)。同样,此EPC有多个可能的因果足迹。
流程模型元素的相似性
在比较业务流程模型时,假设它们的元素(节点)仅具有完全相同的标签是等效的,这是不现实的。图2就是一个例子:流程建模者认为功能“客户查询处理”和“客户查询处理”实际上是相同的,尽管它们具有不同的标签。
因此,作为衡量业务流程模型之间相似性的基础,我们必须能够衡量它们之间的相似性。
我们考虑了三种测量不同过程模型元素之间的相似性的方法:
- 1)句法相似性,其中仅考虑标签的语法;
- 2)语义相似性,其中从语法中进行抽象并查看单词中语义的相似性。以及
- 3)上下文相似性,我们不仅考虑元素本身的标签,还考虑这些元素所在的上下文。
所有这些指标(如下所述)都会导致相似性得分在0到1之间,其中0表示没有相似性,而1表示相同元素。因此,将所有度量组合以获得加权相似度得分是微不足道的。
句法相似性
给定两个标签,句法相似性量度将返回通过字符串编辑距离测量的相似度。字符串编辑距离[11]是从一个字符串到另一个字符串所需的原子字符串操作数。这些原子字符串操作包括:删除字符,插入字符或将字符替换为另一个。
语义相似性
在两个标签之间,它们的语义相似度是基于它们组成的词之间的对等程度。我们假设完全匹配比同义词匹配更受青睐。因此,相同的单词的等效得分为1,而同义的单词的等效得分为0.75(请参见下面的说明)。因此,语义相似性分数定义如下。
考虑的是同义词的映射。
上下文相似性
第三个相似性度量,该度量在确定两个模型元素的相似性时,还应考虑在它们之前和之后的模型元素。这种相似性度量标准对于EPC尤其有用,因为在EPC中,功能始终位于事件的前面和后面。因此,当比较两个函数时,上下文相似性度量会考虑周围的事件。
对于上下文相似性而言,另一种特别有用的过程建模技术是Petri网,因为在Petri网中,“变迁(活动)”始终位于库所的前面和后面(反之亦然)。我们将前面的模型元素称为输入上下文,并将后面的模型元素称为另一个模型元素的输出上下文。
为了确定业务流程模型元素之间的上下文相似性,我们需要在它们的输入和输出上下文中的元素之间进行映射。这样的映射本身基于相似性度量,例如来自句法度量或语义度量的度量之一,并且称为等效映射。
标签匹配相似度
标签匹配相似度得分是匹配节点对的标签相似度得分之和。为了获得0到1之间的分数,我们将总和除以节点总数。
结构相似度
我们研究的第二个相似性度量是通过将EPC视为带标签的图,对EPC的结构进行相似性度量。如果我们将EPC视为图,则其功能,事件和连接器是图的节点,弧线是图的边缘。对于功能和事件,它们的标签将成为相应节点的标签。
然后,我们可以通过计算两个EPC的图形编辑距离来为其分配相似度分数[2]。两个图之间的图编辑距离是从一个图到另一个图所需的最小图编辑操作数。可以考虑不同的图形编辑操作。我们考虑以下因素:节点删除或插入,节点替换(一个节点是一个图,它映射到另一个具有不同标签的图中的节点),以及边删除或插入。像标签匹配相似度一样,图形编辑距离是通过首先计算EPC节点之间的映射并随后计算最佳图形编辑距离来获得的。该分数计算如下。
4.基于变迁标签图编辑距离的过程模型相似性度量2016
以petri网为输入,计算基于行为的过程相似性。
与字符串编辑距离类似,图编辑距离[17]是将一个图转换成另一个图所需的最小变形操作次数,通过定义转换操作(或编辑操作)及其代价,可以量化两个图之间的距离。图编辑操作包括节点和边的插入、删除和替换。
(u→v)表示用节点v替换节点u,(u→ε)表示删除节点u,(ε→v)表示插入节点v,同理可以定义边的编辑操作。
如图1所示,从图1a转换到图1f的过程中,先后进行了如下图的编辑操作:删除(a,b),(b,c),(d,e)三条边,删除一 个 节 点b,插入 一 个 节 点f,插入(e,f),(d,f)两条边,最后替换e,d两个节点。

5.基于任务发生关系的流程模型相似性度量2017
流程模型的管理包括模型分析、模型检索和模型重用等方面[2].流程模型相似性度量在流程模型管理的各个方面都发挥着非常重要的作用.
元素标签映射的相似性度量,是基于节点的成对标签比较.它是通过定义2个模型的节点标签之间的映射,从而计算出相似性.标签匹配相似度等于匹配的节点数除以总节点数.
结构相似性度量方法,是把模型看作一个图,利用公共子图同构和图编辑距离对模型的相似性进行度量.图编辑距离详细定义了从一个图转换到另一个图所需的最小原子级图操作.Dijkman等人[7]提出了一种结构相似性度量方法,该方法定义了进行每一种编辑操作都必须付出相应代价,通过从一个模型到另一个模型的编辑距离,达到求出相似性的目的.基于上述算法,LaRosa等人[8]又提出了一种算法,结合了图的编辑距离和活动匹配的方法
基于行为语义的相似性度量主要从模型的行为语义(如执行序列、任务关系)角度去考虑提取模型的行为关系,进而进行相似性的计算.
本文的基于任务间发生关系的模型相似性度量算法
- 1)基于完全前缀展开.首先把给定的 Petri网模型进行完全前缀展开,这样可以保持流程模型的所有标识及任务间发生关系,便于后续提取流程模型的行为特征。

- 2)节点遍历编号.逐层广度优先遍历得到的完全前缀展开,对其节点按照遍历的层次编号,并存储节点和其对应的编号.

- 3)求出任务发生关系.根据最近公共前驱算法求出每2个任务的最近公共前驱并作相应的存储,从而进一步求出任务发生关系.根据求出的最近公共前驱以及特殊结构的处理方式,确定任务之间的发生关系.
- 4)模型相似性计算.在相应的任务间关系集合的基础上,通过关系集合之间的加权相似性计算出模型之间的相似性.
并行关系、互斥关系以及因果关系的权重分别用如下公式计算

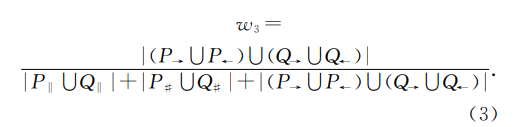
直接采用各类二元关系个数在所有二元关系总数中的比重,认为并行关系、互斥关系和因果关系具有相同的重要性。
相似性计算
根据Jaccard系数,并行关系、互斥关系以及因果关系的相似性分别用如下公式计算

6.Measuring Similarity between Semantic Business Process Models2007
提出了基于标签语义的相似性度量方法.该类算法思路简单、计算快速,但未对模型的拓扑结构和行为语义加以考虑,导致计算结果不够精准.