总览
1、训练检测网络
(1)数据
(2)损失函数
2、测试
(1)检测后处理及跟踪
1、训练
(1)数据
数据集类JointDataset在src\lib\datasets\dataset\jde.py文件中:
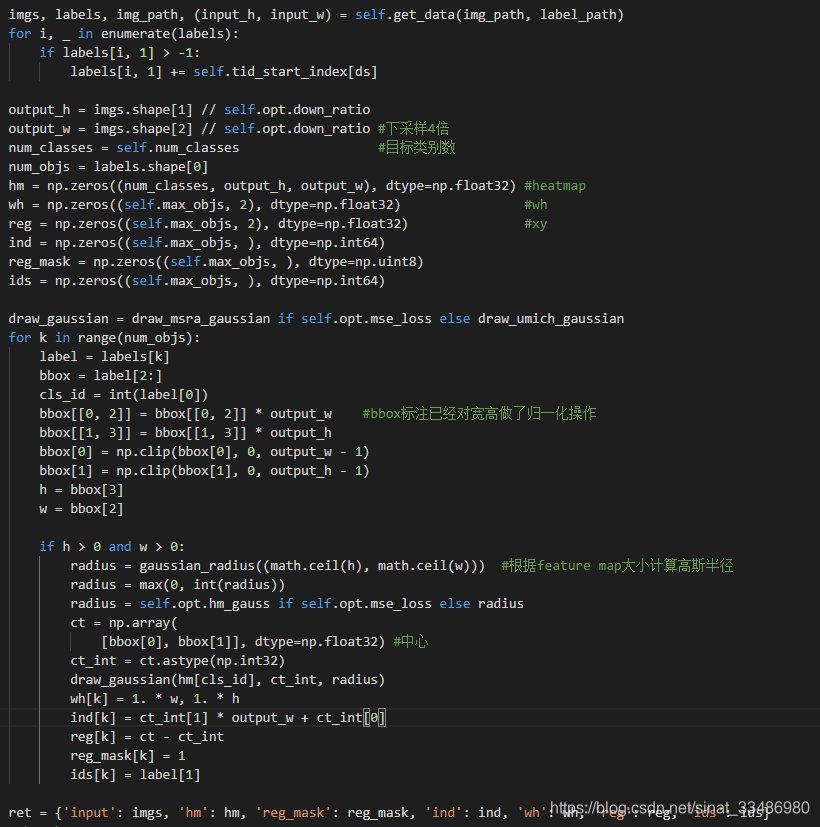
首先__getitem__方法中读取图片和对应的标签,做简单的数据增强,统计所有数据集的ID最大值,也就是最多有多少个需要跟踪的对象。由于FairMOT的检测网络有三个分支:目标类别分类,目标位置和大小回归,还有区分目标的特征提取。所以训练数据也要做对应的label。FairMOT使用的是centernet类型的点回归方式来检测目标的中心点以及确定目标的宽高。主干的最后加了三个网络构造来输出预测值,默认是C个类(hm)、2个预测的宽高值(wh)、2个中心点的偏置(xy)。
类别(hm):而这C个类别是通过C通道的heatmap来预测的,heatmap的值是在0~1之间的概率值。一个通道表示一类,heatmap的大小是原图下采样4倍之后的大小,也就是说,网络在经过4次下采样之后的特征图上做预测。如果图像中有某个类别的目标,那么这个目标的中心点在heatmap上的概率值为1,其余周围概率成高斯分布逐渐衰减,如图所示:

对应的heatmap:

两个红色的点,表示两个目标的中心点的概率值最大,在其周围有渐变的一个小圆圈,这个圆圈成高斯分布,其半径和目标的大小有关系,越靠近圆心的位置,是目标中心点的概率就越大。
目标宽高(wh),目标中心偏移(xy):通过回归得到。
目标ID(id): 交叉熵分类得到。
这部分label设置代码如下:
(2)损失函数
通过(1)中的分析,损失包括:heatmap分类loss,宽高回归loss,目标中心点偏移回归loss,目标ID分类loss。
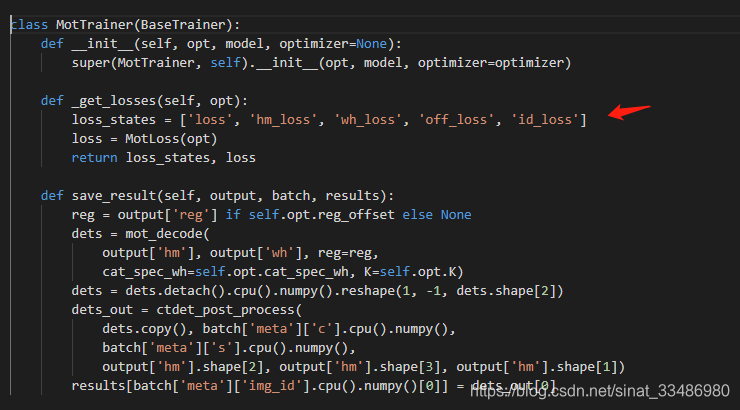
MOTloss类定义了这几个loss,在src\lib\trains\mot.py文件中
class MotLoss(torch.nn.Module):
def __init__(self, opt):
super(MotLoss, self).__init__()
self.crit = torch.nn.MSELoss() if opt.mse_loss else FocalLoss() #分类loss
self.crit_reg = RegL1Loss() if opt.reg_loss == 'l1' else \
RegLoss() if opt.reg_loss == 'sl1' else None #中心点x,y的offset
self.crit_wh = torch.nn.L1Loss(reduction='sum') if opt.dense_wh else \
NormRegL1Loss() if opt.norm_wh else \
RegWeightedL1Loss() if opt.cat_spec_wh else self.crit_reg #宽高回归loss
self.opt = opt
self.emb_dim = opt.reid_dim #reid特征长度
self.nID = opt.nID #所有目标的ID数
self.classifier = nn.Linear(self.emb_dim, self.nID)
self.IDLoss = nn.CrossEntropyLoss(ignore_index=-1) #ID loss
#self.TriLoss = TripletLoss()
self.emb_scale = math.sqrt(2) * math.log(self.nID - 1)
self.s_det = nn.Parameter(-1.85 * torch.ones(1))
self.s_id = nn.Parameter(-1.05 * torch.ones(1))
def forward(self, outputs, batch):
opt = self.opt
hm_loss, wh_loss, off_loss, id_loss = 0, 0, 0, 0
for s in range(opt.num_stacks):
output = outputs[s]
if not opt.mse_loss:
output['hm'] = _sigmoid(output['hm'])
hm_loss += self.crit(output['hm'], batch['hm']) / opt.num_stacks #修改过后的focal loss
#wh_loss
if opt.wh_weight > 0:
if opt.dense_wh:
mask_weight = batch['dense_wh_mask'].sum() + 1e-4
wh_loss += (
self.crit_wh(output['wh'] * batch['dense_wh_mask'],
batch['dense_wh'] * batch['dense_wh_mask']) /
mask_weight) / opt.num_stacks
else:
wh_loss += self.crit_reg(
output['wh'], batch['reg_mask'],
batch['ind'], batch['wh']) / opt.num_stacks
#xyoffset_loss
if opt.reg_offset and opt.off_weight > 0:
off_loss += self.crit_reg(output['reg'], batch['reg_mask'],
batch['ind'], batch['reg']) / opt.num_stacks
#id loss
if opt.id_weight > 0:
id_head = _tranpose_and_gather_feat(output['id'], batch['ind'])
id_head = id_head[batch['reg_mask'] > 0].contiguous()
id_head = self.emb_scale * F.normalize(id_head)
id_target = batch['ids'][batch['reg_mask'] > 0]
id_output = self.classifier(id_head).contiguous()
id_loss += self.IDLoss(id_output, id_target)
#id_loss += self.IDLoss(id_output, id_target) + self.TriLoss(id_head, id_target)
#loss = opt.hm_weight * hm_loss + opt.wh_weight * wh_loss + opt.off_weight * off_loss + opt.id_weight * id_loss
det_loss = opt.hm_weight * hm_loss + opt.wh_weight * wh_loss + opt.off_weight * off_loss
loss = torch.exp(-self.s_det) * det_loss + torch.exp(-self.s_id) * id_loss + (self.s_det + self.s_id)
loss *= 0.5
#print(loss, hm_loss, wh_loss, off_loss, id_loss)
loss_stats = {'loss': loss, 'hm_loss': hm_loss,
'wh_loss': wh_loss, 'off_loss': off_loss, 'id_loss': id_loss}
return loss, loss_stats有了数据和loss,就可以训练了。
2、测试
(1)检测后处理及跟踪
检测每一帧输入的图像,src\demo.py

src\track.py
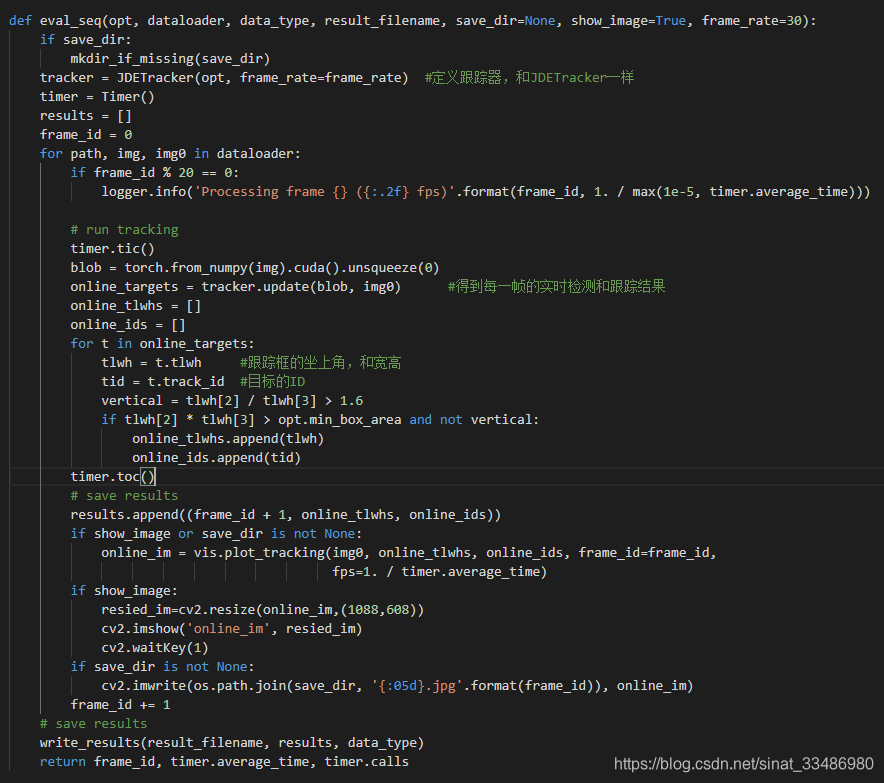
src\lib\tracker\multitracker.py————> tracker.update ()
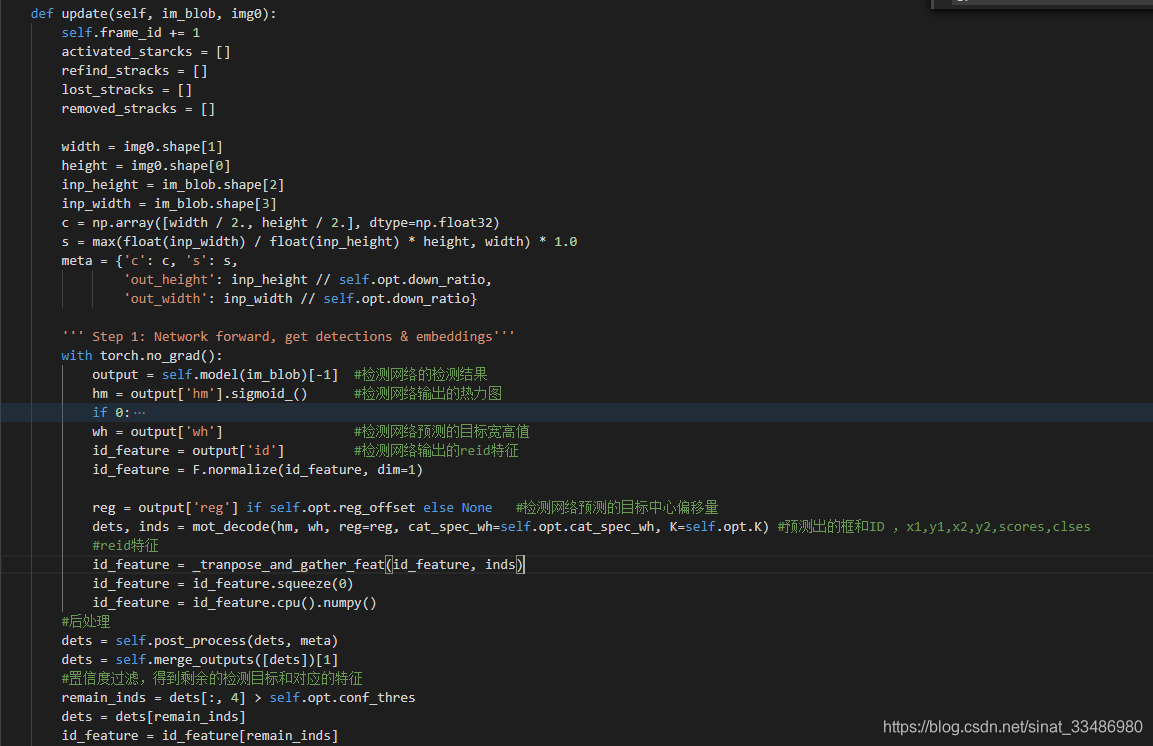
接下来就是类似于Deepsort的跟踪流程了,初始化跟踪器,根据特征距离和马氏距离计算匹配矩阵,匈牙利匹配,处理匹配和未匹配的检测框和跟踪器等。
if len(dets) > 0:
'''Detections'''
detections = [STrack(STrack.tlbr_to_tlwh(tlbrs[:4]), tlbrs[4], f, 30) for
(tlbrs, f) in zip(dets[:, :5], id_feature)] #将特征保存在每一个跟踪目标中
else:
detections = []
''' Add newly detected tracklets to tracked_stracks'''
unconfirmed = []
tracked_stracks = [] # type: list[STrack]
for track in self.tracked_stracks:
if not track.is_activated:
unconfirmed.append(track)
else:
tracked_stracks.append(track)
''' Step 2: First association, with embedding'''
strack_pool = joint_stracks(tracked_stracks, self.lost_stracks)
# Predict the current location with KF
#for strack in strack_pool:
#strack.predict()
STrack.multi_predict(strack_pool) #卡尔曼滤波预测新位置
dists = matching.embedding_distance(strack_pool, detections) #计算跟踪框和检测框的特征余弦距离矩阵
#dists = matching.gate_cost_matrix(self.kalman_filter, dists, strack_pool, detections)
dists = matching.fuse_motion(self.kalman_filter, dists, strack_pool, detections) #计算马氏距离矩阵
matches, u_track, u_detection = matching.linear_assignment(dists, thresh=0.7) #匈牙利匹配
for itracked, idet in matches:
track = strack_pool[itracked]
det = detections[idet]
if track.state == TrackState.Tracked:
track.update(detections[idet], self.frame_id)
activated_starcks.append(track)
else:
track.re_activate(det, self.frame_id, new_id=False)
refind_stracks.append(track)
''' Step 3: Second association, with IOU'''
detections = [detections[i] for i in u_detection]
r_tracked_stracks = [strack_pool[i] for i in u_track if strack_pool[i].state == TrackState.Tracked]
dists = matching.iou_distance(r_tracked_stracks, detections)
matches, u_track, u_detection = matching.linear_assignment(dists, thresh=0.5)
for itracked, idet in matches:
track = r_tracked_stracks[itracked]
det = detections[idet]
if track.state == TrackState.Tracked:
track.update(det, self.frame_id)
activated_starcks.append(track)
else:
track.re_activate(det, self.frame_id, new_id=False)
refind_stracks.append(track)
for it in u_track:
track = r_tracked_stracks[it]
if not track.state == TrackState.Lost:
track.mark_lost()
lost_stracks.append(track)
'''Deal with unconfirmed tracks, usually tracks with only one beginning frame'''
detections = [detections[i] for i in u_detection]
dists = matching.iou_distance(unconfirmed, detections)
matches, u_unconfirmed, u_detection = matching.linear_assignment(dists, thresh=0.7)
for itracked, idet in matches:
unconfirmed[itracked].update(detections[idet], self.frame_id)
activated_starcks.append(unconfirmed[itracked])
for it in u_unconfirmed:
track = unconfirmed[it]
track.mark_removed()
removed_stracks.append(track)
""" Step 4: Init new stracks"""
for inew in u_detection:
track = detections[inew]
if track.score < self.det_thresh:
continue
track.activate(self.kalman_filter, self.frame_id)
activated_starcks.append(track)
""" Step 5: Update state"""
for track in self.lost_stracks:
if self.frame_id - track.end_frame > self.max_time_lost:
track.mark_removed()
removed_stracks.append(track)
总结
FairMOT的特色主要在于检测算法和reid特征的融合在一起,检测目标的同时,输出reid特征,而且用了anchor-free的centerNet检测算法,相比于anchor类的方法有很多优势。而真正跟踪流程还是DeepSort那一套。话说anchor-free类算法还是很有前景的。