nn.BCELoss
1、nn.BCELoss
nn.BCELoss()是 二元交叉熵损失函数 (Binary Cross Entropy Loss)- 适用于二分类问题,即
- 模型的输出为一个概率值,表示样本属于某一类的概率
- 标签为二元值:0 或 1
nn.BCELoss()计算的是二元交叉熵损失,也称为对数损失,它将模型 预测值 和 真实标签值 之间的差异转化为一个标量损失值,用于衡量模型预测的准确性。
2、使用场景
假设有一个 二分类任务:判断一张图片中是否包含猫。
我们可以定义一个二元分类模型,用 Sigmoid 输出一个概率值,表示样本属于猫的概率。 标签值为 0 和 1。
使用以下代码构建模型和损失函数:
import torch
import torch.nn as nn
class CatClassifier(nn.Module):
def __init__(self):
super(CatClassifier, self).__init__()
self.fc = nn.Linear(3*256*256, 1)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
x = x.view(x.size(0), -1)
x = self.fc(x)
x = self.sigmoid(x)
return x
model = CatClassifier()
criterion = nn.BCELoss()
在每次迭代时,我们可以通过以下代码计算损失:
outputs = model(inputs)
loss = criterion(outputs, labels.float())
3、nn.BCELoss 计算公式
L = − 1 N ∑ i = 1 N [ y i log ( y i ^ ) + ( 1 − y i ) log ( 1 − y i ^ ) ] L = -\frac{1}{N} \sum_{i=1}^{N} [y_i \log(\hat{y_i}) + (1-y_i) \log(1-\hat{y_i})] L=−N1i=1∑N[yilog(yi^)+(1−yi)log(1−yi^)]
其中:
- N N N 表示样本数量
- y i y_i yi 表示第 i i i 个样本的实际标签
- y i ^ \hat{y_i} yi^ 表示第 i i i 个样本的预测值
如果 y i = 1 y_i=1 yi=1,则第一项 y i log ( y i ^ ) y_i \log(\hat{y_i}) yilog(yi^) 生效,第二项 ( 1 − y i ) log ( 1 − y i ^ ) (1-y_i) \log(1-\hat{y_i}) (1−yi)log(1−yi^) 失效;
如果 y i = 0 y_i=0 yi=0,则第一项失效,第二项生效。
因为 y i ^ \hat{y_i} yi^ 值的范围是 0 ~ 1, 所以, log ( y i ^ ) \log(\hat{y_i}) log(yi^) 和 log ( 1 − y i ^ ) \log(1-\hat{y_i}) log(1−yi^) 的值都是负数,如下图红色曲线。 所以,损失函数的最前面有个负号,将损失值变为正数。
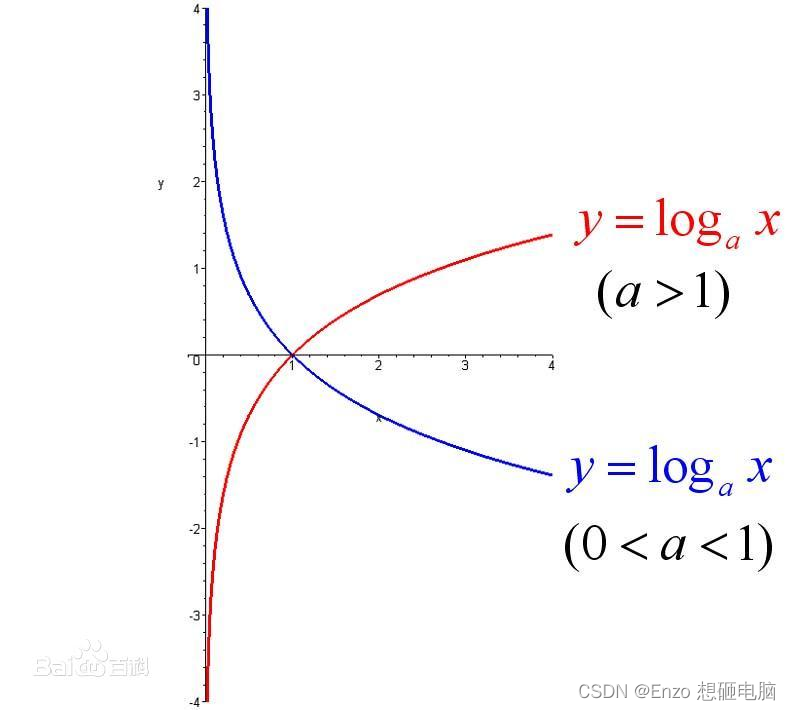
因此,当模型的预测值与标签值越接近时,损失值越小。
4、torch.nn.BCEWithLogitsLoss() 与 nn.BCELoss() 的区别
nn.BCELoss() 的输入是 二元分类模型的预测值 y ^ \hat{y} y^ 和 实际标签 y y y。并且 y ^ \hat{y} y^ 的范围是 [0,1],因为二元分类模型内部已经对预测结果做了 sigmoid 处理。
n n . B C E L o s s ( ) = − 1 N ∑ i = 1 N [ y i log ( y i ^ ) + ( 1 − y i ) log ( 1 − y i ^ ) ] nn.BCELoss() = -\frac{1}{N} \sum_{i=1}^{N} [y_i \log(\hat{y_i}) + (1-y_i) \log(1-\hat{y_i})] nn.BCELoss()=−N1i=1∑N[yilog(yi^)+(1−yi)log(1−yi^)]
torch.nn.BCEWithLogitsLoss() 的输入是也是 二元分类模型的输出值 z z z 和实际标签 y y y,不同的是 z z z 在模型内部没有经过 sigmoid 处理,是任意实数。这种情况下,sigmoid 处理就被放到了损失函数中,所以,torch.nn.BCEWithLogitsLoss() 函数内部的计算过程是先对 z z z 应用 sigmoid 函数,将其映射到 [0,1] 范围内,然后使用二元交叉熵计算预测值和实际标签之间的损失值。
n n . B C E W i t h L o g i t s L o s s ( ) = − 1 N ∑ i = 1 N [ y i log σ ( z i ) + ( 1 − y i ) log ( 1 − σ ( z i ) ) ] nn.BCEWithLogitsLoss() = -\frac{1}{N} \sum_{i=1}^{N} [y_i \log \sigma{(z_i)} + (1-y_i) \log(1-\sigma{(z_i)})] nn.BCEWithLogitsLoss()=−N1i=1∑N[yilogσ(zi)+(1−yi)log(1−σ(zi))]
另外,torch.nn.BCEWithLogitsLoss() 还支持设置 pos_weight 参数,用于处理样本不平衡的问题。而 nn.BCELoss() 不支持设置 pos_weight 参数。
5、torch.nn.BCELoss() 函数
torch.nn.BCELoss(weight=None, size_average=None, reduce=None, reduction='mean')
参数说明:
- weight :用于样本加权的权重张量。如果给定,则必须是一维张量,大小等于输入张量的大小。默认值为 None。
- reduction :指定如何计算损失值。可选值为 ‘none’、‘mean’ 或 ‘sum’。默认值为 ‘mean’。
6、torch.nn.BCEWithLogitsLoss() 函数
torch.nn.BCEWithLogitsLoss(weight=None,
size_average=None,
reduce=None,
reduction='mean',
pos_weight=None)
参数说明:
- weight:用于对每个样本的损失值进行加权。默认值为 None。
- reduction:指定如何对每个 batch 的损失值进行降维。可选值为 ‘none’、‘mean’ 和 ‘sum’。默认值为 ‘mean’。
- pos_weight:用于对正样本的损失值进行加权。可以用于处理样本不平衡的问题。例如,如果正样本比负样本少很多,可以设置 pos_weight 为一个较大的值,以提高正样本的权重。默认值为 None。