【图像分类】2022-MaxViT ECCV
论文题目:MaxViT: Multi-Axis Vision Transformer
论文链接:https://arxiv.org/abs/2204.01697
论文代码:https://github.com/google-research/maxvit
发表时间:2022年4月
团队:谷歌
引用:Tu Z, Talebi H, Zhang H, et al. Maxvit: Multi-axis vision transformer[J]. arXiv preprint arXiv:2204.01697, 2022.
引用数:4
1. 简介
1.1 摘要
由于自注意力的机制对于图像大小方面缺乏可扩展性,限制了它们在视觉主干中的应用。本文提出了一种高效的可拓展的全局注意,该模型包括两个方面:阻塞的局部注意和拓展的全局注意。作者通过将该注意模型与卷积有效结合,并简单的将这些模块堆叠,形成了了一个分层的视觉主干网络MaxVit。值得注意的是,MaxVit能在整个网络中看到全局甚至是在早期的高分辨率的阶段。在分类任务上,该模型在ImaegNet 1K上达到86.5%的 top-1准确率,在imageNet-21K上纪进行预训练,top-1准确率可以达到88.7%。对于一些下游任务如目标检测和图像美学评估,该模型同样具有好的性能。
1.2 解决的问题
研究发现,如果没有广泛的预训练,ViT在图像识别方面表现不佳。这是由于Transformer具有较强的建模能力,但是缺乏归纳偏置,从而导致过拟合。
其中一个有效的解决方法就是控制模型容量并提高其可扩展性,在参数量减少的同时得到性能的增强,如Twins、LocalViT以及Swin Transformer等。这些模型通常重新引入层次结构以弥补非局部性的损失,比如Swin Transformer通过在移位的非重叠窗口上应用自我注意。但在灵活性与可扩展性得到提高的同时,由于这些模型普遍失去了类似于ViT的非局部性,即具有有限的模型容量,导致无法在更大的数据集上扩展(ImageNet-21K、JFT等)。
综上,研究局部与全局相结合的方法来增加模型灵活性是有必要的。然而,如何实现对不同数据量的适应,如何有效结合局部与全局计算的优势成为本文要解决的目标。
本文设计了一种简单而有效的视觉Backbone,称为多轴Transformer(MaxViT),它由Max-SA和卷积组成的重复块分层叠加。
- MaxViT是一个通用的Transformer结构**,在每一个块内都可以实现局部与全局之间的空间交互**,同时可适应不同分辨率的输入大小。
- Max-SA通过分解空间轴得到窗口注意力(Block attention)与网格注意力(Grid attention),将传统计算方法的二次复杂度降到线性复杂度。
- MBConv作为自注意力计算的补充,利用其固有的归纳偏差来提升模型的泛化能力,避免陷入过拟合。
2. 网络
2.1 整体架构
本文引入了一种新的注意力模块——多轴自注意力(multi-axis self-attention, MaxSA),将传统的自注意机制分解为**窗口注意力(Block attention)与网格注意力(Grid attention)**两种稀疏形式,在不损失非局部性的情况下,将普通注意的二次复杂度降低到线性。由于Max-SA的灵活性和可伸缩性,我们可以通过简单地将Max-SA与MBConv在分层体系结构中叠加,从而构建一个称为MaxViT的视觉 Backbone,如图2所示。
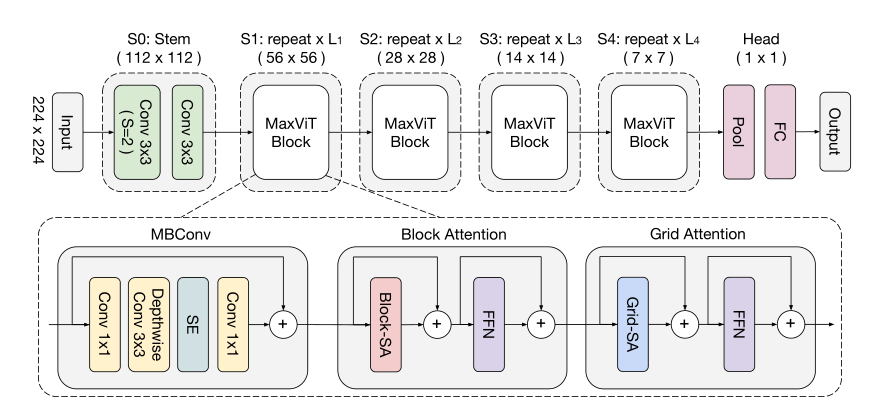
2.2 Multi-axis Attention
与局部卷积相比,全局相互作用是自注意力机制的优势之一。然而,直接将注意力应用于整个空间在计算上是不可行的,因为注意力算子需要二次复杂度,为了解决全局自注意力导致的二次复杂度,本文提出了一种多轴注意力的方法,通过**分解空间轴得到局部(block attention)与全局(grid attention)**两种稀疏形式,具体过程如下:
1) Block attention
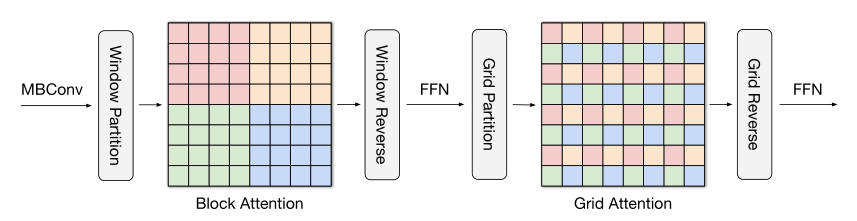
**block attention:**对于输入特征图 X ∈ R H × W × C X\in R^{H\times W\times C} X∈RH×W×C, 转化为形状张量 ( H P × P , W P × P , C ) \left(\frac{H}{P} \times P, \frac{W}{P} \times P, C\right) (PH×P,PW×P,C)以表示划分为不重叠的窗口, 其中每个窗口的大小为 p × p p\times p p×p,最后在每一个窗口中执行自注意力计算。
Block : ( H , W , C ) → ( H P × P , W P × P , C ) → ( H W P 2 , P 2 , C ) \text { Block }:(H, W, C) \rightarrow\left(\frac{H}{P} \times P, \frac{W}{P} \times P, C\right) \rightarrow\left(\frac{H W}{P^{2}}, P^{2}, C\right) Block :(H,W,C)→(PH×P,PW×P,C)→(P2HW,P2,C)
def block(x,window_size):
B,C,H,W = x.shape
x = x.reshape(B,C,H//window_size[0],window_size[0],W//window_size[1],window_size[1])
x = x.permute(0,2,4,1,3,5).contiguous()
return x
def unblock(x):
B,H,W,C,win_H,win_W = x.shape
x = x.permute(0,3,1,4,2,5).contiguous().reshape(B,C,H*win_W,H*win_W)
return x
class Window_Block(nn.Module):
def __init__(self, dim, block_size=(7,7), num_heads=8, mlp_ratio=4., qkv_bias=False,qk_scale=None, drop=0.,
attn_drop=0.,drop_path=0., act_layer=nn.GELU ,norm_layer=Channel_Layernorm):
super().__init__()
self.block_size = block_size
mlp_hidden_dim = int(dim * mlp_ratio)
self.norm1 = norm_layer(dim)
self.norm2 = norm_layer(dim)
self.mlp = Mlp(dim, mlp_hidden_dim, act_layer=act_layer, drop=drop)
self.attn = Rel_Attention(dim, block_size, num_heads, qkv_bias, qk_scale, attn_drop, drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self,x):
assert x.shape[2]%self.block_size[0] == 0 & x.shape[3]%self.block_size[1] == 0, 'image size should be divisible by block_size'
# self.block_size = 7,也就是按照7×7大小的window划分。
out = block(self.norm1(x),self.block_size)
out = self.attn(out)
x = x + self.drop_path(unblock(self.attn(out)))
out = self.mlp(self.norm2(x))
x = x + self.drop_path(out)
return x
虽然避免了全局自注意力机制的复杂计算,但是局部注意模型已经被证明不适用于大规模的数据集。所以作者提出一种稀疏的全局自注意力机制,被称作grid attention(网格注意力机制)。
2) Grid attention
**grid attention:**不同于传统使用固定窗口大小来划分特征图的操作,grid attention 使用固定的 G × G G\times G G×G,均匀网格将输人张量网格化为 G × G , H G × H G , C G\times G,\frac{H}{G}\times \frac{H}{G},C G×G,GH×GH,C, 此时 得到自适应大小的窗口 H G × H G \frac{H}{G}\times \frac{H}{G} GH×GH, 最后在 G × G G\times G G×G上使用自注意力计算。需要注意, 通过使用相同的窗口 p × p p\times p p×p和网格 G × G G\times G G×G, 可以有效平衡局部和全局之间的计算 (且仅具有线性复杂度)。
Grid : ( H , W , C ) → ( G × H G , G × W G , C ) → ( G 2 , H W G 2 , C ) → ( H W G 2 , G 2 , C ) ⏟ swapaxes ( axis 1 = − 2 , axis 2 = − 3 ) \text { Grid }:(H, W, C) \rightarrow\left(G \times \frac{H}{G}, G \times \frac{W}{G}, C\right) \rightarrow \underbrace{\left(G^{2}, \frac{H W}{G^{2}}, C\right) \rightarrow\left(\frac{H W}{G^{2}}, G^{2}, C\right)}_{\text {swapaxes }(\text { axis } 1=-2,\text { axis }2=-3)} Grid :(H,W,C)→(G×GH,G×GW,C)→swapaxes ( axis 1=−2, axis 2=−3)
(G2,G2HW,C)→(G2HW,G2,C)
class Grid_Block(nn.Module):
def __init__(self, dim, grid_size=(7,7), num_heads=8, mlp_ratio=4., qkv_bias=False,qk_scale=None, drop=0.,
attn_drop=0.,drop_path=0., act_layer=nn.GELU ,norm_layer=Channel_Layernorm):
super().__init__()
self.grid_size = grid_size
mlp_hidden_dim = int(dim * mlp_ratio)
self.norm1 = norm_layer(dim)
self.norm2 = norm_layer(dim)
self.mlp = Mlp(dim, mlp_hidden_dim, act_layer=act_layer, drop=drop)
self.attn = Rel_Attention(dim, grid_size, num_heads, qkv_bias, qk_scale, attn_drop, drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self,x):
assert x.shape[2]%self.grid_size[0] == 0 & x.shape[3]%self.grid_size[1] == 0, 'image size should be divisible by grid_size'
grid_size = (x.shape[2]//self.grid_size[0], x.shape[3]//self.grid_size[1])
# grid_size 是网格窗口的数量,x.shape[2]//self.grid_size[0] = H // G。
out = block(self.norm1(x),grid_size)
out = out.permute(0,4,5,3,1,2).contiguous()
out = self.attn(out).permute(0,4,5,3,1,2).contiguous()
x = x + self.drop_path(unblock(out))
out = self.mlp(self.norm2(x))
x = x + self.drop_path(out)
return x
注意:遵循Swin Transformer中窗口设置大小, P = G = 7 P=G=7 P=G=7。本文提出的Max-SA模块可以直接替换Swin注意模块力,具有完全相同的参数和FLOPs数量。并且,它享有全局交互能力,而不需要 masking, padding, or cyclic-shifting,使其更易于实现,比移位窗口方案更可取。
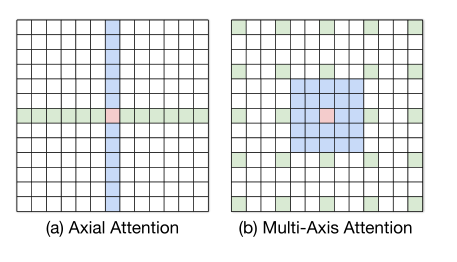
Multi-Axis attention与Axial attention区别:
和轴向注意力的区别
本文所提出的方法不同于 Axial attention。如图 3 所示, 在 Axial attention 中 首先使用列注意力(column-wise attention),然后使用行注意力( row-wise attention) 来计算全局 注意力,相当于 O ( N N ) O(N\sqrt{N}) O(NN)的计算复杂度,然而 Multi-Axis attention 则先采用局部注意力 (block attention), 再使用稀疏的全局注意力 (grid attention), 这样的 设计充分考虑了图像的 2D 结构,并且仅具有 O ( N ) O(N) O(N)的线性复杂度。
2.4 MBConv
为了获得更丰富的特征表示,首先使用逐点卷积进行通道升维,在升维后的投影空间中进行Depth-wise卷积,紧随其后的SE用于增强重要通道的表征,最后再次使用逐点卷积恢复维度。可用如下公式表示:
x ← x + Proj ( S E ( D W Conv ( Conv ( Norm ( x ) ) ) ) ) x \leftarrow x+\operatorname{Proj}(S E(D W \operatorname{Conv}(\operatorname{Conv}(\operatorname{Norm}(x))))) x←x+Proj(SE(DWConv(Conv(Norm(x)))))
对于每个阶段的第一个MBConv块,下采样是通过应用stride=2的深度可分离卷积( Depthwise Conv3x3)来完成的,而残差连接分支也 应用pooling 和 channel 映射:
x ← Proj ( Pool 2 D ( x ) ) + Proj ( S E ( D W Conv ↓ ( Conv ( Norm ( x ) ) ) ) ) x \leftarrow \operatorname{Proj}(\operatorname{Pool} 2 D(x))+\operatorname{Proj}(S E(D W \operatorname{Conv} \downarrow(\operatorname{Conv}(\operatorname{Norm}(x))))) x←Proj(Pool2D(x))+Proj(SE(DWConv↓(Conv(Norm(x)))))
MBConv就是有以下特点:
- 1)采用了Depthwise Convlution,因此相比于传统卷积,Depthwise Conv的参数能够大大减少;
- 2)采用了“倒瓶颈”的结构,也就是说在卷积过程中,特征经历了升维和降维两个步骤,并利用卷积固有的归纳偏置,在一定程度上提升模型的泛化能力与可训练性。
- 3)相比于ViT中的显式位置编码,在Multi-axis Attention则使用MBConv来代替,这是因为深度可分离卷积可被视为条件位置编码(CPE)。
3. 代码
"""
MaxViT
A PyTorch implementation of the paper: `MaxViT: Multi-Axis Vision Transformer`
- MaxViT: Multi-Axis Vision Transformer
Copyright (c) 2021 Christoph Reich
Licensed under The MIT License [see LICENSE for details]
Written by Christoph Reich
代码来源 https://github.com/ChristophReich1996/MaxViT
"""
from typing import Type, Callable, Tuple, Optional, Set, List, Union
import torch
import torch.nn as nn
from timm.models.efficientnet_blocks import SqueezeExcite, DepthwiseSeparableConv
from timm.models.layers import drop_path, trunc_normal_, Mlp, DropPath
def _gelu_ignore_parameters(
*args,
**kwargs
) -> nn.Module:
""" Bad trick to ignore the inplace=True argument in the DepthwiseSeparableConv of Timm.
Args:
*args: Ignored.
**kwargs: Ignored.
Returns:
activation (nn.Module): GELU activation function.
"""
activation = nn.GELU()
return activation
class MBConv(nn.Module):
""" MBConv block as described in: https://arxiv.org/pdf/2204.01697.pdf.
Without downsampling:
x ← x + Proj(SE(DWConv(Conv(Norm(x)))))
With downsampling:
x ← Proj(Pool2D(x)) + Proj(SE(DWConv ↓(Conv(Norm(x))))).
Conv is a 1 X 1 convolution followed by a Batch Normalization layer and a GELU activation.
SE is the Squeeze-Excitation layer.
Proj is the shrink 1 X 1 convolution.
Note: This implementation differs slightly from the original MobileNet implementation!
Args:
in_channels (int): Number of input channels.
out_channels (int): Number of output channels.
downscale (bool, optional): If true downscale by a factor of two is performed. Default: False
act_layer (Type[nn.Module], optional): Type of activation layer to be utilized. Default: nn.GELU
norm_layer (Type[nn.Module], optional): Type of normalization layer to be utilized. Default: nn.BatchNorm2d
drop_path (float, optional): Dropout rate to be applied during training. Default 0.
"""
def __init__(
self,
in_channels: int,
out_channels: int,
downscale: bool = False,
act_layer: Type[nn.Module] = nn.GELU,
norm_layer: Type[nn.Module] = nn.BatchNorm2d,
drop_path: float = 0.,
) -> None:
""" Constructor method """
# Call super constructor
super(MBConv, self).__init__()
# Save parameter
self.drop_path_rate: float = drop_path
# Check parameters for downscaling
if not downscale:
assert in_channels == out_channels, "If downscaling is utilized input and output channels must be equal."
# Ignore inplace parameter if GELU is used
if act_layer == nn.GELU:
act_layer = _gelu_ignore_parameters
# Make main path
self.main_path = nn.Sequential(
norm_layer(in_channels),
DepthwiseSeparableConv(in_chs=in_channels, out_chs=out_channels, stride=2 if downscale else 1,
act_layer=act_layer, norm_layer=norm_layer, drop_path_rate=drop_path),
SqueezeExcite(in_chs=out_channels, rd_ratio=0.25),
nn.Conv2d(in_channels=out_channels, out_channels=out_channels, kernel_size=(1, 1))
)
# Make skip path
self.skip_path = nn.Sequential(
nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2)),
nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=(1, 1))
) if downscale else nn.Identity()
def forward(
self,
input: torch.Tensor
) -> torch.Tensor:
""" Forward pass.
Args:
input (torch.Tensor): Input tensor of the shape [B, C_in, H, W].
Returns:
output (torch.Tensor): Output tensor of the shape [B, C_out, H (// 2), W (// 2)] (downscaling is optional).
"""
output = self.main_path(input)
if self.drop_path_rate > 0.:
output = drop_path(output, self.drop_path_rate, self.training)
output = output + self.skip_path(input)
return output
def window_partition(
input: torch.Tensor,
window_size: Tuple[int, int] = (7, 7)
) -> torch.Tensor:
""" Window partition function.
Args:
input (torch.Tensor): Input tensor of the shape [B, C, H, W].
window_size (Tuple[int, int], optional): Window size to be applied. Default (7, 7)
Returns:
windows (torch.Tensor): Unfolded input tensor of the shape [B * windows, window_size[0], window_size[1], C].
"""
# Get size of input
B, C, H, W = input.shape
# Unfold input
windows = input.view(B, C, H // window_size[0], window_size[0], W // window_size[1], window_size[1])
# Permute and reshape to [B * windows, window_size[0], window_size[1], channels]
windows = windows.permute(0, 2, 4, 3, 5, 1).contiguous().view(-1, window_size[0], window_size[1], C)
return windows
def window_reverse(
windows: torch.Tensor,
original_size: Tuple[int, int],
window_size: Tuple[int, int] = (7, 7)
) -> torch.Tensor:
""" Reverses the window partition.
Args:
windows (torch.Tensor): Window tensor of the shape [B * windows, window_size[0], window_size[1], C].
original_size (Tuple[int, int]): Original shape.
window_size (Tuple[int, int], optional): Window size which have been applied. Default (7, 7)
Returns:
output (torch.Tensor): Folded output tensor of the shape [B, C, original_size[0], original_size[1]].
"""
# Get height and width
H, W = original_size
# Compute original batch size
B = int(windows.shape[0] / (H * W / window_size[0] / window_size[1]))
# Fold grid tensor
output = windows.view(B, H // window_size[0], W // window_size[1], window_size[0], window_size[1], -1)
output = output.permute(0, 5, 1, 3, 2, 4).contiguous().view(B, -1, H, W)
return output
def grid_partition(
input: torch.Tensor,
grid_size: Tuple[int, int] = (7, 7)
) -> torch.Tensor:
""" Grid partition function.
Args:
input (torch.Tensor): Input tensor of the shape [B, C, H, W].
grid_size (Tuple[int, int], optional): Grid size to be applied. Default (7, 7)
Returns:
grid (torch.Tensor): Unfolded input tensor of the shape [B * grids, grid_size[0], grid_size[1], C].
"""
# Get size of input
B, C, H, W = input.shape
# Unfold input
grid = input.view(B, C, grid_size[0], H // grid_size[0], grid_size[1], W // grid_size[1])
# Permute and reshape [B * (H // grid_size[0]) * (W // grid_size[1]), grid_size[0], window_size[1], C]
grid = grid.permute(0, 3, 5, 2, 4, 1).contiguous().view(-1, grid_size[0], grid_size[1], C)
return grid
def grid_reverse(
grid: torch.Tensor,
original_size: Tuple[int, int],
grid_size: Tuple[int, int] = (7, 7)
) -> torch.Tensor:
""" Reverses the grid partition.
Args:
Grid (torch.Tensor): Grid tensor of the shape [B * grids, grid_size[0], grid_size[1], C].
original_size (Tuple[int, int]): Original shape.
grid_size (Tuple[int, int], optional): Grid size which have been applied. Default (7, 7)
Returns:
output (torch.Tensor): Folded output tensor of the shape [B, C, original_size[0], original_size[1]].
"""
# Get height, width, and channels
(H, W), C = original_size, grid.shape[-1]
# Compute original batch size
B = int(grid.shape[0] / (H * W / grid_size[0] / grid_size[1]))
# Fold grid tensor
output = grid.view(B, H // grid_size[0], W // grid_size[1], grid_size[0], grid_size[1], C)
output = output.permute(0, 5, 3, 1, 4, 2).contiguous().view(B, C, H, W)
return output
def get_relative_position_index(
win_h: int,
win_w: int
) -> torch.Tensor:
""" Function to generate pair-wise relative position index for each token inside the window.
Taken from Timms Swin V1 implementation.
Args:
win_h (int): Window/Grid height.
win_w (int): Window/Grid width.
Returns:
relative_coords (torch.Tensor): Pair-wise relative position indexes [height * width, height * width].
"""
coords = torch.stack(torch.meshgrid([torch.arange(win_h), torch.arange(win_w)]))
coords_flatten = torch.flatten(coords, 1)
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :]
relative_coords = relative_coords.permute(1, 2, 0).contiguous()
relative_coords[:, :, 0] += win_h - 1
relative_coords[:, :, 1] += win_w - 1
relative_coords[:, :, 0] *= 2 * win_w - 1
return relative_coords.sum(-1)
class RelativeSelfAttention(nn.Module):
""" Relative Self-Attention similar to Swin V1. Implementation inspired by Timms Swin V1 implementation.
Args:
in_channels (int): Number of input channels.
num_heads (int, optional): Number of attention heads. Default 32
grid_window_size (Tuple[int, int], optional): Grid/Window size to be utilized. Default (7, 7)
attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
drop (float, optional): Dropout ratio of output. Default: 0.0
"""
def __init__(
self,
in_channels: int,
num_heads: int = 32,
grid_window_size: Tuple[int, int] = (7, 7),
attn_drop: float = 0.,
drop: float = 0.
) -> None:
""" Constructor method """
# Call super constructor
super(RelativeSelfAttention, self).__init__()
# Save parameters
self.in_channels: int = in_channels
self.num_heads: int = num_heads
self.grid_window_size: Tuple[int, int] = grid_window_size
self.scale: float = num_heads ** -0.5
self.attn_area: int = grid_window_size[0] * grid_window_size[1]
# Init layers
self.qkv_mapping = nn.Linear(in_features=in_channels, out_features=3 * in_channels, bias=True)
self.attn_drop = nn.Dropout(p=attn_drop)
self.proj = nn.Linear(in_features=in_channels, out_features=in_channels, bias=True)
self.proj_drop = nn.Dropout(p=drop)
self.softmax = nn.Softmax(dim=-1)
# Define a parameter table of relative position bias, shape: 2*Wh-1 * 2*Ww-1, nH
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * grid_window_size[0] - 1) * (2 * grid_window_size[1] - 1), num_heads))
# Get pair-wise relative position index for each token inside the window
self.register_buffer("relative_position_index", get_relative_position_index(grid_window_size[0],
grid_window_size[1]))
# Init relative positional bias
trunc_normal_(self.relative_position_bias_table, std=.02)
def _get_relative_positional_bias(
self
) -> torch.Tensor:
""" Returns the relative positional bias.
Returns:
relative_position_bias (torch.Tensor): Relative positional bias.
"""
relative_position_bias = self.relative_position_bias_table[
self.relative_position_index.view(-1)].view(self.attn_area, self.attn_area, -1)
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous()
return relative_position_bias.unsqueeze(0)
def forward(
self,
input: torch.Tensor
) -> torch.Tensor:
""" Forward pass.
Args:
input (torch.Tensor): Input tensor of the shape [B_, N, C].
Returns:
output (torch.Tensor): Output tensor of the shape [B_, N, C].
"""
# Get shape of input
B_, N, C = input.shape
# Perform query key value mapping
qkv = self.qkv_mapping(input).reshape(B_, N, 3, self.num_heads, -1).permute(2, 0, 3, 1, 4)
q, k, v = qkv.unbind(0)
# Scale query
q = q * self.scale
# Compute attention maps
attn = self.softmax(q @ k.transpose(-2, -1) + self._get_relative_positional_bias())
# Map value with attention maps
output = (attn @ v).transpose(1, 2).reshape(B_, N, -1)
# Perform final projection and dropout
output = self.proj(output)
output = self.proj_drop(output)
return output
class MaxViTTransformerBlock(nn.Module):
""" MaxViT Transformer block.
With block partition:
x ← x + Unblock(RelAttention(Block(LN(x))))
x ← x + MLP(LN(x))
With grid partition:
x ← x + Ungrid(RelAttention(Grid(LN(x))))
x ← x + MLP(LN(x))
Layer Normalization (LN) is applied after the grid/window partition to prevent multiple reshaping operations.
Grid/window reverse (Unblock/Ungrid) is performed on the final output for the same reason.
Args:
in_channels (int): Number of input channels.
partition_function (Callable): Partition function to be utilized (grid or window partition).
reverse_function (Callable): Reverse function to be utilized (grid or window reverse).
num_heads (int, optional): Number of attention heads. Default 32
grid_window_size (Tuple[int, int], optional): Grid/Window size to be utilized. Default (7, 7)
attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
drop (float, optional): Dropout ratio of output. Default: 0.0
drop_path (float, optional): Dropout ratio of path. Default: 0.0
mlp_ratio (float, optional): Ratio of mlp hidden dim to embedding dim. Default: 4.0
act_layer (Type[nn.Module], optional): Type of activation layer to be utilized. Default: nn.GELU
norm_layer (Type[nn.Module], optional): Type of normalization layer to be utilized. Default: nn.BatchNorm2d
"""
def __init__(
self,
in_channels: int,
partition_function: Callable,
reverse_function: Callable,
num_heads: int = 32,
grid_window_size: Tuple[int, int] = (7, 7),
attn_drop: float = 0.,
drop: float = 0.,
drop_path: float = 0.,
mlp_ratio: float = 4.,
act_layer: Type[nn.Module] = nn.GELU,
norm_layer: Type[nn.Module] = nn.LayerNorm,
) -> None:
""" Constructor method """
super(MaxViTTransformerBlock, self).__init__()
# Save parameters
self.partition_function: Callable = partition_function
self.reverse_function: Callable = reverse_function
self.grid_window_size: Tuple[int, int] = grid_window_size
# Init layers
self.norm_1 = norm_layer(in_channels)
self.attention = RelativeSelfAttention(
in_channels=in_channels,
num_heads=num_heads,
grid_window_size=grid_window_size,
attn_drop=attn_drop,
drop=drop
)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm_2 = norm_layer(in_channels)
self.mlp = Mlp(
in_features=in_channels,
hidden_features=int(mlp_ratio * in_channels),
act_layer=act_layer,
drop=drop
)
def forward(self, input: torch.Tensor) -> torch.Tensor:
""" Forward pass.
Args:
input (torch.Tensor): Input tensor of the shape [B, C_in, H, W].
Returns:
output (torch.Tensor): Output tensor of the shape [B, C_out, H (// 2), W (// 2)].
"""
# Save original shape
B, C, H, W = input.shape
# Perform partition
input_partitioned = self.partition_function(input, self.grid_window_size)
input_partitioned = input_partitioned.view(-1, self.grid_window_size[0] * self.grid_window_size[1], C)
# Perform normalization, attention, and dropout
output = input_partitioned + self.drop_path(self.attention(self.norm_1(input_partitioned)))
# Perform normalization, MLP, and dropout
output = output * self.drop_path(self.mlp(self.norm_2(output)))
# Reverse partition
output = self.reverse_function(output, (H, W), self.grid_window_size)
return output
class MaxViTBlock(nn.Module):
""" MaxViT block composed of MBConv block, Block Attention, and Grid Attention.
Args:
in_channels (int): Number of input channels.
out_channels (int): Number of output channels.
downscale (bool, optional): If true spatial downscaling is performed. Default: False
num_heads (int, optional): Number of attention heads. Default 32
grid_window_size (Tuple[int, int], optional): Grid/Window size to be utilized. Default (7, 7)
attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
drop (float, optional): Dropout ratio of output. Default: 0.0
drop_path (float, optional): Dropout ratio of path. Default: 0.0
mlp_ratio (float, optional): Ratio of mlp hidden dim to embedding dim. Default: 4.0
act_layer (Type[nn.Module], optional): Type of activation layer to be utilized. Default: nn.GELU
norm_layer (Type[nn.Module], optional): Type of normalization layer to be utilized. Default: nn.BatchNorm2d
norm_layer_transformer (Type[nn.Module], optional): Normalization layer in Transformer. Default: nn.LayerNorm
"""
def __init__(
self,
in_channels: int,
out_channels: int,
downscale: bool = False,
num_heads: int = 32,
grid_window_size: Tuple[int, int] = (7, 7),
attn_drop: float = 0.,
drop: float = 0.,
drop_path: float = 0.,
mlp_ratio: float = 4.,
act_layer: Type[nn.Module] = nn.GELU,
norm_layer: Type[nn.Module] = nn.BatchNorm2d,
norm_layer_transformer: Type[nn.Module] = nn.LayerNorm
) -> None:
""" Constructor method """
# Call super constructor
super(MaxViTBlock, self).__init__()
# Init MBConv block
self.mb_conv = MBConv(
in_channels=in_channels,
out_channels=out_channels,
downscale=downscale,
act_layer=act_layer,
norm_layer=norm_layer,
drop_path=drop_path
)
# Init Block and Grid Transformer
self.block_transformer = MaxViTTransformerBlock(
in_channels=out_channels,
partition_function=window_partition,
reverse_function=window_reverse,
num_heads=num_heads,
grid_window_size=grid_window_size,
attn_drop=attn_drop,
drop=drop,
drop_path=drop_path,
mlp_ratio=mlp_ratio,
act_layer=act_layer,
norm_layer=norm_layer_transformer
)
self.grid_transformer = MaxViTTransformerBlock(
in_channels=out_channels,
partition_function=grid_partition,
reverse_function=grid_reverse,
num_heads=num_heads,
grid_window_size=grid_window_size,
attn_drop=attn_drop,
drop=drop,
drop_path=drop_path,
mlp_ratio=mlp_ratio,
act_layer=act_layer,
norm_layer=norm_layer_transformer
)
def forward(self, input: torch.Tensor) -> torch.Tensor:
""" Forward pass.
Args:
input (torch.Tensor): Input tensor of the shape [B, C_in, H, W]
Returns:
output (torch.Tensor): Output tensor of the shape [B, C_out, H // 2, W // 2] (downscaling is optional)
"""
output = self.grid_transformer(self.block_transformer(self.mb_conv(input)))
return output
class MaxViTStage(nn.Module):
""" Stage of the MaxViT.
Args:
depth (int): Depth of the stage.
in_channels (int): Number of input channels.
out_channels (int): Number of output channels.
num_heads (int, optional): Number of attention heads. Default 32
grid_window_size (Tuple[int, int], optional): Grid/Window size to be utilized. Default (7, 7)
attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
drop (float, optional): Dropout ratio of output. Default: 0.0
drop_path (float, optional): Dropout ratio of path. Default: 0.0
mlp_ratio (float, optional): Ratio of mlp hidden dim to embedding dim. Default: 4.0
act_layer (Type[nn.Module], optional): Type of activation layer to be utilized. Default: nn.GELU
norm_layer (Type[nn.Module], optional): Type of normalization layer to be utilized. Default: nn.BatchNorm2d
norm_layer_transformer (Type[nn.Module], optional): Normalization layer in Transformer. Default: nn.LayerNorm
"""
def __init__(
self,
depth: int,
in_channels: int,
out_channels: int,
num_heads: int = 32,
grid_window_size: Tuple[int, int] = (7, 7),
attn_drop: float = 0.,
drop: float = 0.,
drop_path: Union[List[float], float] = 0.,
mlp_ratio: float = 4.,
act_layer: Type[nn.Module] = nn.GELU,
norm_layer: Type[nn.Module] = nn.BatchNorm2d,
norm_layer_transformer: Type[nn.Module] = nn.LayerNorm
) -> None:
""" Constructor method """
# Call super constructor
super(MaxViTStage, self).__init__()
# Init blocks
self.blocks = nn.Sequential(*[
MaxViTBlock(
in_channels=in_channels if index == 0 else out_channels,
out_channels=out_channels,
downscale=index == 0,
num_heads=num_heads,
grid_window_size=grid_window_size,
attn_drop=attn_drop,
drop=drop,
drop_path=drop_path if isinstance(drop_path, float) else drop_path[index],
mlp_ratio=mlp_ratio,
act_layer=act_layer,
norm_layer=norm_layer,
norm_layer_transformer=norm_layer_transformer
)
for index in range(depth)
])
def forward(self, input=torch.Tensor) -> torch.Tensor:
""" Forward pass.
Args:
input (torch.Tensor): Input tensor of the shape [B, C_in, H, W].
Returns:
output (torch.Tensor): Output tensor of the shape [B, C_out, H // 2, W // 2].
"""
output = self.blocks(input)
return output
class MaxViT(nn.Module):
""" Implementation of the MaxViT proposed in:
https://arxiv.org/pdf/2204.01697.pdf
Args:
in_channels (int, optional): Number of input channels to the convolutional stem. Default 3
depths (Tuple[int, ...], optional): Depth of each network stage. Default (2, 2, 5, 2)
channels (Tuple[int, ...], optional): Number of channels in each network stage. Default (64, 128, 256, 512)
num_classes (int, optional): Number of classes to be predicted. Default 1000
embed_dim (int, optional): Embedding dimension of the convolutional stem. Default 64
num_heads (int, optional): Number of attention heads. Default 32
grid_window_size (Tuple[int, int], optional): Grid/Window size to be utilized. Default (7, 7)
attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
drop (float, optional): Dropout ratio of output. Default: 0.0
drop_path (float, optional): Dropout ratio of path. Default: 0.0
mlp_ratio (float, optional): Ratio of mlp hidden dim to embedding dim. Default: 4.0
act_layer (Type[nn.Module], optional): Type of activation layer to be utilized. Default: nn.GELU
norm_layer (Type[nn.Module], optional): Type of normalization layer to be utilized. Default: nn.BatchNorm2d
norm_layer_transformer (Type[nn.Module], optional): Normalization layer in Transformer. Default: nn.LayerNorm
global_pool (str, optional): Global polling type to be utilized. Default "avg"
"""
def __init__(
self,
in_channels: int = 3,
depths: Tuple[int, ...] = (2, 2, 5, 2),
channels: Tuple[int, ...] = (64, 128, 256, 512),
num_classes: int = 1000,
embed_dim: int = 64,
num_heads: int = 32,
grid_window_size: Tuple[int, int] = (7, 7),
attn_drop: float = 0.,
drop=0.,
drop_path=0.,
mlp_ratio=4.,
act_layer=nn.GELU,
norm_layer=nn.BatchNorm2d,
norm_layer_transformer=nn.LayerNorm,
global_pool: str = "avg"
) -> None:
""" Constructor method """
# Call super constructor
super(MaxViT, self).__init__()
# Check parameters
assert len(depths) == len(channels), "For each stage a channel dimension must be given."
assert global_pool in ["avg", "max"], f"Only avg and max is supported but {
global_pool} is given"
# Save parameters
self.num_classes: int = num_classes
# Init convolutional stem
self.stem = nn.Sequential(
nn.Conv2d(in_channels=in_channels, out_channels=embed_dim, kernel_size=(3, 3), stride=(2, 2),
padding=(1, 1)),
act_layer(),
nn.Conv2d(in_channels=embed_dim, out_channels=embed_dim, kernel_size=(3, 3), stride=(1, 1),
padding=(1, 1)),
act_layer(),
)
# Init blocks
drop_path = torch.linspace(0.0, drop_path, sum(depths)).tolist()
self.stages = []
for index, (depth, channel) in enumerate(zip(depths, channels)):
self.stages.append(
MaxViTStage(
depth=depth,
in_channels=embed_dim if index == 0 else channels[index - 1],
out_channels=channel,
num_heads=num_heads,
grid_window_size=grid_window_size,
attn_drop=attn_drop,
drop=drop,
drop_path=drop_path[sum(depths[:index]):sum(depths[:index + 1])],
mlp_ratio=mlp_ratio,
act_layer=act_layer,
norm_layer=norm_layer,
norm_layer_transformer=norm_layer_transformer
)
)
self.global_pool: str = global_pool
self.head = nn.Linear(channels[-1], num_classes)
@torch.jit.ignore
def no_weight_decay(self) -> Set[str]:
""" Gets the names of parameters to not apply weight decay to.
Returns:
nwd (Set[str]): Set of parameter names to not apply weight decay to.
"""
nwd = set()
for n, _ in self.named_parameters():
if "relative_position_bias_table" in n:
nwd.add(n)
return nwd
def reset_classifier(self, num_classes: int, global_pool: Optional[str] = None) -> None:
"""Method results the classification head
Args:
num_classes (int): Number of classes to be predicted
global_pool (str, optional): If not global pooling is updated
"""
self.num_classes: int = num_classes
if global_pool is not None:
self.global_pool = global_pool
self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()
def forward_features(self, input: torch.Tensor) -> torch.Tensor:
""" Forward pass of feature extraction.
Args:
input (torch.Tensor): Input images of the shape [B, C, H, W].
Returns:
output (torch.Tensor): Image features of the backbone.
"""
output = input
for stage in self.stages:
output = stage(output)
return output
def forward_head(self, input: torch.Tensor, pre_logits: bool = False):
""" Forward pass of classification head.
Args:
input (torch.Tensor): Input features
pre_logits (bool, optional): If true pre-logits are returned
Returns:
output (torch.Tensor): Classification output of the shape [B, num_classes].
"""
if self.global_pool == "avg":
input = input.mean(dim=(2, 3))
elif self.global_pool == "max":
input = torch.amax(input, dim=(2, 3))
return input if pre_logits else self.head(input)
def forward(self, input: torch.Tensor) -> torch.Tensor:
""" Forward pass
Args:
input (torch.Tensor): Input images of the shape [B, C, H, W].
Returns:
output (torch.Tensor): Classification output of the shape [B, num_classes].
"""
output = self.forward_features(self.stem(input))
output = self.forward_head(output)
return output
def max_vit_tiny_224(**kwargs) -> MaxViT:
""" MaxViT tiny for a resolution of 224 X 224"""
return MaxViT(
depths=(2, 2, 5, 2),
channels=(64, 128, 256, 512),
embed_dim=64,
**kwargs
)
def max_vit_small_224(**kwargs) -> MaxViT:
""" MaxViT small for a resolution of 224 X 224"""
return MaxViT(
depths=(2, 2, 5, 2),
channels=(96, 128, 256, 512),
embed_dim=64,
**kwargs
)
def max_vit_base_224(**kwargs) -> MaxViT:
""" MaxViT base for a resolution of 224 X 224"""
return MaxViT(
depths=(2, 6, 14, 2),
channels=(96, 192, 384, 768),
embed_dim=64,
**kwargs
)
def max_vit_large_224(**kwargs) -> MaxViT:
""" MaxViT large for a resolution of 224 X 224"""
return MaxViT(
depths=(2, 6, 14, 2),
channels=(128, 256, 512, 1024),
embed_dim=128,
**kwargs
)
if __name__ == '__main__':
def test_partition_and_revers() -> None:
input = torch.rand(7, 3, 14, 14)
windows = window_partition(input=input)
windows = window_reverse(windows=windows, window_size=(7, 7), original_size=input.shape[2:])
print(torch.all(input == windows))
grid = grid_partition(input=input)
grid = grid_reverse(grid=grid, grid_size=(7, 7), original_size=input.shape[2:])
print(torch.all(input == grid))
def test_relative_self_attention() -> None:
relative_self_attention = RelativeSelfAttention(in_channels=128)
input = torch.rand(4, 128, 14 * 14)
output = relative_self_attention(input)
print(output.shape)
def test_transformer_block() -> None:
transformer = MaxViTTransformerBlock(in_channels=128, partition_function=grid_partition,
reverse_function=grid_reverse)
input = torch.rand(4, 128, 7, 7)
output = transformer(input)
print(output.shape)
transformer = MaxViTTransformerBlock(in_channels=128, partition_function=window_partition,
reverse_function=window_reverse)
input = torch.rand(4, 128, 7, 7)
output = transformer(input)
print(output.shape)
def test_block() -> None:
block = MaxViTBlock(in_channels=128, out_channels=256, downscale=True)
input = torch.rand(1, 128, 28, 28)
output = block(input)
print(output.shape)
def test_networks() -> None:
for get_network in [max_vit_tiny_224, max_vit_small_224, max_vit_base_224, max_vit_large_224]:
network = get_network(num_classes=365)
input = torch.rand(1, 3, 224, 224)
output = network(input)
print(output.shape)
test_networks()
ECCV 2022 | 88.7%准确率!谷歌提出MaxViT:多轴视觉Transformer - 知乎 (zhihu.com)