1、论文
论文题名:《GhostNet: More Features from Cheap Operations》
arxiv:https://arxiv.org/abs/1911.11907
github:https://github.com/huawei-noah/ghostnet
作者翻译:https://zhuanlan.zhihu.com/p/109325275
2、摘要
本篇论文是华为诺亚方舟实验室在CVPR2020上提出的一种轻量级网络GhostNet。
在优秀CNN模型中,特征图存在冗余是非常重要的,但是很少有人在模型结构设计上考虑特征图冗余问题(The redundancy in feature maps)。而本文就从特征图冗余问题出发,提出一个仅通过少量计算(cheap operations)就能生成大量特征图的结构——Ghost Module。
Ghost Module通过一系列线性操作/廉价操作(a series of linear transformations/cheap operations)生成冗余的特征图,其中,经过线性操作生成的特征图称为ghost feature maps,而被操作的特征图称为intrinsic feature maps。
Ghost Module的优点:
(1)即插即用:Ghost Module是一个即插即用模块,可以无缝衔接在现有的CNN中。
(2)采用Ghost Module组成的Ghost bottlenecks,设计出GhostNet,在ILSVRC-2012上top1超过Mobilenet V3,并且参数更少。
3、引言
3.1 什么是特征图冗余?

如图,这个是对ResNet-50第一个残差块特征图进行可视化的结果,当我们向一个神经网络输入一张图片时,我们可以得到许多的特征图,一对相似的特征图用同一种颜色注释,上图有三对相似的特征图。
利用小扳手连接起来的两幅特征图,它们的相似性很高,这就是神经网络中存在的特征图冗杂的情况。作者认为在一对相似的特征图中,一个特征图可以通过廉价操作(扳手)将另一个特征图变换而获得。将相似的特征图认为是彼此的Ghost。
3.2 什么是Ghost feature maps和Intrinsic feature maps?
经过线性操作生成的特征图称为ghost feature maps,而被操作的特征图称为intrinsic feature maps,即intrinsic feature maps执行linear operations得到ghost feature maps。
下图表示,假设一组特征图中,一部分是Intrinic,而另外一部分是可以由intrinsic通过cheap operations来生成的,cheap operations反复出现多次。
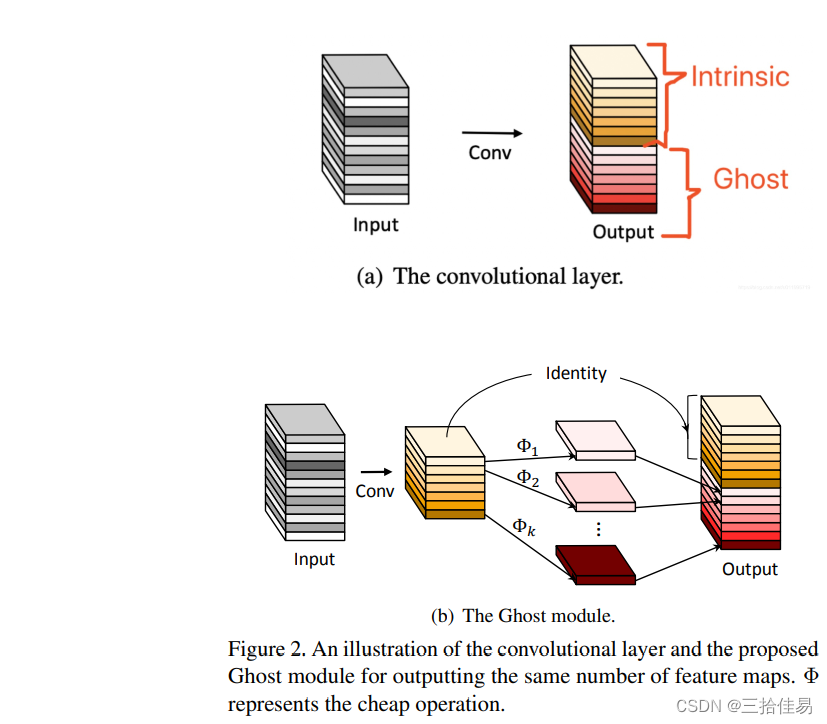
3.3 什么是linear transformations和cheap operations?
linear transformations = cheap operations
一个intrinsic特征图可以具有一个或多个ghost特征图。
线性运算是在通道上运行,对每一个通道单独做运算,其计算量比普通卷积少得多。实际上,Ghost Module中可能有几种不同的线性运算,例如3×3和5×5线性内核。
4、Ghost Module
如上图2的a、b图所示,Ghost Module的功能是代替普通卷积,分两步操作来生成和普通卷积层相同数量的特征图。
首先Ghost Module采用1×1卷积降维,得到channel较少的特征图(少量卷积),这个1x1卷积的作用类似于特征整合,生成输入特征层的特征浓缩(比如正常用32个卷积核,这里就用16个,从而减少一半的计算量);然后再利用深度可分离卷积(3×3或5×5的DW深度卷积),也就是上述说的cheap operation生成Ghost特征图;最后将两次卷积的输出特征图再维度上堆叠concat,组合成新的output输出特征图。
步骤:
(1)利用1x1卷积Conv生成一些intrinsic feature maps
(2)对(1)生成的intrinsic feature maps进行DW深度可分离卷积(廉价操作)生成冗余特征图(特征浓缩的相似特征图ghost feature maps)
(3)最后将(1)(2)所生成的intrinsic feature maps和ghost feature maps进行concat拼接
注意:ratio表示Ghost Module中第一个1×1卷积下降通道数的倍数, 一般为2。
4.1 Ghost Module的计算量
如图2所示,假设输入图像大小是:h×w×c,卷积核的大小是:k×k,第一步生成的intrinsic特征图的大小是:h’×w’×m,s是第二步对intrinsic特征图中的每个特征(intrinsic特征图的m个通道)进行廉价操作的总映射,Ghost Module最终输出的特征图大小是:h’×w’×n,其中m << n。
可以得出:n = m * s
由于Ghost Module的第二步廉价操作中有1个identity恒等映射和s-1个ghost特征图,所以第二步Ghost Module具有m(s-1)个线性运算,即m(s-1) = n/s(s-1)个线性运算,并且每个线性运算的平均内核大小是d×d(d×d和k×k大小相似)。

图2(a)普通卷积的复杂度为:n * h’ * w’ * c * k * k
图2(b)Ghost Module的第一步普通卷积的复杂度为:m * h’ * w’ * c * k * k = n/s * h’ * w’ * c * k * k,第二步廉价操作(恒等映射和线性运算)的复杂度为:m(s-1) * h’ * w’ * d * d = n/s(s-1) * h’ * w’ * d * d(DW操作,分别对每一个通道做运算)
则,使用Ghost Module替换普通卷积的理论加速比为:

5、Ghost bottlenecks
Ghost bottlenecks是由Ghost Module组成的瓶颈结构,其实本质就是用Ghost Module,来代替瓶颈结构里面的普通卷积。

如图所示,Ghost bottleneck类似于ResNet中的基本残差块(Basic Residual Block),不同的是先升维再降维。
stride = 1的Ghost bottleneck:
主干部分由两个Ghost Module串联而成。第一个Ghost Module上升通道数,第二个Ghost Module降低通道数,以与shortcut路径匹配。然后,如果此时两个特征图的shape相同,就使用shortcut连接这两个Ghost Module的输入和输出。
stride = 2的Ghost bottleneck:
主干部分由两个 Ghost Module和一个DW深度卷积组成。第一个Ghost Module上升通道数;在高维空间下使用一个s=2的DW深度卷积下采样,来压缩特征图的高宽;第二个Ghost Module降低通道数。在shortcut路径部分,对输入特征图先使用s=2的DW深度卷积来压缩高宽,再使用1×1卷积调整通道数,使得输入和输出的特征图的shape相同。
注意:
(1)出于效率考虑,Ghost Module中的初始卷积是PW逐点卷积。
(2)第二个Ghost Module之后不使用ReLU,其他层在每层之后都应用了BN和ReLU非线性激活。
6、GhostNet网络结构

- exp:Ghost bottleneck中第一个Ghost Module上升的维度,即上升的通道数
- out:一个Ghost bottleneck的输出通道数
- SE:Ghost bottleneck中是否使用注意力机制,和MobileNet v3中的SE一样。若在s=1的Ghost bottleneck中使用,SE在第一个Ghost Module后使用;若在s=2的Ghost bottleneck中使用,SE在主干部分的DW深度卷积下采样层后使用,即两个Ghost Module之间的DW层的后面使用。
注意:
表格中stride=2表示,在s=2情况下的Ghost bottleneck中,其主干部分的两个Ghost Module之间的DW层的步距为2,其shortcut部分的DW层步距也为2;
无论是s=1还是s=2情况下的Ghost bottleneck中,其主干部分的Ghost Module里的第二步深度可分离卷积的步距一直是1,不受表格中stride的影响。