利用 TFX, Amazon SageMaker和kubernets 的能力构建可靠的 MLOPS 平台
第一章
了解kubefolw 如何工作。了解kubernetes的架构功能,如service,pod,ingress 创建PVC绑定文件存储以保存代码和数据等,学习构建docker 镜像,
k8s 架构
k8s如何工作
- Master:控制集群,包含三个部分
- API Server:通过 RESTful 接口提供 Kubernetes 功能并存储集群状态
- Scheduler:scheduler监视 新 Pod的 API Server的请求。它与Nodes 通信以创建新的 pod 并将工作分配给nodes,同时分配资源或施加约束
- Controller Manager:运行 controllers,包括Node controller, Endpoint Controller, Namespace
Controller等
- Slave(Nodes):这些机器执行请求、分配的任务。 Kubernetes master 控制它们。Nodes内部有以下四个组件
- Pod:所有容器都将在 pod 中运行。 Pod 将网络和存储从底层容器中抽象出来。应用将在pod中运行
- Kubelet:Kubectl 向集群注册节点,监视调度程序的工作分配,实例化新的 Pod,并向Master节点报告
- Container Engine:负责管理容器、镜像拉取、停止容器、启动容器、销毁容器等
- Kube Proxy:它负责将应用程序用户请求转发到正确的 pod
k8s 组件
Node
我们可以简单地将每台机器视为一组可以利用的 CPU 和 RAM 资源。这样,任何机器都可以替代 Kubernetes 集群中的任何其他机器
Cluster
node 的集和,单个节点故障不影响整体
Pod
pod 内的容器共享存储资源和网络,就好像容器在同一台机器上,同时彼此保持一定程度的隔离。pod也是副本replication 的单位,pod自动被分配唯一的IP地址,pod内容器之间共享相同的网络命名空间包括IP地址和端口,容器之间通过 localhost 交互。Pod 可以指定一组可以在容器之间共享的共享存储卷
Deployment
pod 通常不直接在集群上启动,而是由deployment管理。deployment的主要目的是声明一次应该运行多少个 pod 副本。当deployment添加到集群时,它会自动启动请求数量的 pod,然后监控它们。如果 pod 死亡,deployment将自动重新创建它。
Service
-
Kubernetes 中的service是一个 REST 对象,类似于 Pod。与所有 REST 对象一样,可以将Service定义发布到 API Server以创建新实例。service的名称必须是有效的 DNS 标签名称。
-
例如,假设有一组 Pod,每个 Pod 都侦听 TCP 端口 9376 并带有标签 app=MyApp - 此规范创建一个名为“my-service”的新service对象,该对象以任何 TCP 端口 9376 ,具有app=MyApp 标签的 Pod 为目标。 Kubernetes 为该 Service 分配一个 IP 地址(有时称为“集群 IP”),供 Service 代理使用。 Pod 中的端口定义有名称,您可以在 Service 的 targetPort 属性中引用这些名称
-
在 Kubernetes 集群中,每个 Pod 都有一个内部 IP 地址。但是 Deployment 中的 Pod 来来去去,它们的 IP 地址会发生变化。因此,直接使用 Pod IP 地址是没有意义的。使用 Service,即使成员 Pod 的 IP 地址发生变化,也可以在 Service 生命周期内使用的稳定 IP 地址。
-
service还提供负载平衡。客户端调用一个单一的、稳定的 IP 地址,并且他们的请求在作为服务成员的 Pod 之间进行平衡
Service的类型
- ClusterIP:在集群内部使用,默认值,内部客户端将请求发送到稳定的内部 IP 地址。
- NodePort:在所有安装了 Kube-Proxy 的节点上打开一个端口,此端口可以代理至后端
Pod,可以通过 NodePort 从集群外部访问集群内的服务,格式为 NodeIP:NodePort。 - LoadBalancer:使用云提供商的负载均衡器公开服务,成本较高。
- ExternalName:内部客户端使用service的 DNS 名称作为外部 DNS 名称的别名,需要 1.7 或
更高版本 kube-dns 支持 - Headless:在需要 Pod 分组但不需要稳定 IP 地址的情况下使用无头服务
Ingress
默认情况下,Kubernetes 提供 pod 和外部世界之间的隔离。如果要与运行在 pod 中的service进行通信,则必须打开通信通道
Ingress 将集群外部的 HTTP 和 HTTPS 路由暴露给集群内的 services。流量路由由 Ingress 上定义的规则控制。以下是一个简单的示例,其中 Ingress 将其所有流量发送到一个 Service

Ingress 可能是暴露服务的最强大方式,但同时也是最复杂的。Ingress 控制器有各种类型,包括 Google Cloud Load Balancer, Nginx,Contour,Istio,等等。它还有各种插件,比如 cert-manager (它可以为你的服务自动提供 SSL 证书)
Ingress 可以给 Service 提供集群外部访问的 URL、负载均衡、SSL 终止、HTTP 路由等。为了配置这些 Ingress 规则,集群管理员需要部署一个 Ingress Controller,它监听 Ingress 和 Service 的变化,并根据规则配置负载均衡并提供访问入口
Namespace
Namespace 提供一个名称的范围。资源的名称在 Namespace 内必须是唯一的,而不是跨Namespace,Namespace不能相互嵌套,每个 Kubernetes 资源只能在一个命名空间中
Kubeflow 组件
Central Dashboard

Registration Flow
你可能需要在第一次登录Kubeflow时创建一个命名空间。命名空间有时被称为配置文件或工作组,命名空间的默认名字是你的用户名。
Metadata
Metadata项目的目标是通过跟踪和管理工作流产生的Metadata,帮助Kubeflow用户了解和管理他们的 machine learning workflows。
Jupyter Notebook server
Katib
使用Katib对你的ML模型的超参数和架构进行自动调优。欲了解更多信息,请访问以下链接https://www.kubeflow.org/docs/components/katib/
Getting Started in GCP Kubeflow setup
这儿没有GCP环境,记录一下重点
- Google Kubernetes Engine (GKE)

- 这儿由一些资料 2nd Annual MLOps World: Machine Learning in Production Conference
- knative 是什么。终于有人把Knative讲明白了,文档网站:https://knative.dev/docs/
- 定制 jupyter 镜像-》启动notebook 选定CPU和RAM,设置数据卷和PV
第二章
构建一个端到端的Tensorflow 分类模型,然后使用kubeflow进行部署,包括到GCP(谷歌云平台)的 K8S集群上安装kubeflow,使用docker和kubeflow SDK构建pipeline,使用KF serving 推理,在grafana dashboard 跟踪监控推理性能

每一步构建docker镜像,然后push到GCR(Google Container Registry)
看代码学习python库
- click 命令行神器
- dill:Python中增强版的pickle,文档:https://dill.readthedocs.io/en/latest/dill.html
- KFServing
- kfp: Kubeflow Pipelines SDK
- Kubernetes官方维护的Python客户端client-python
KF-Serving 架构
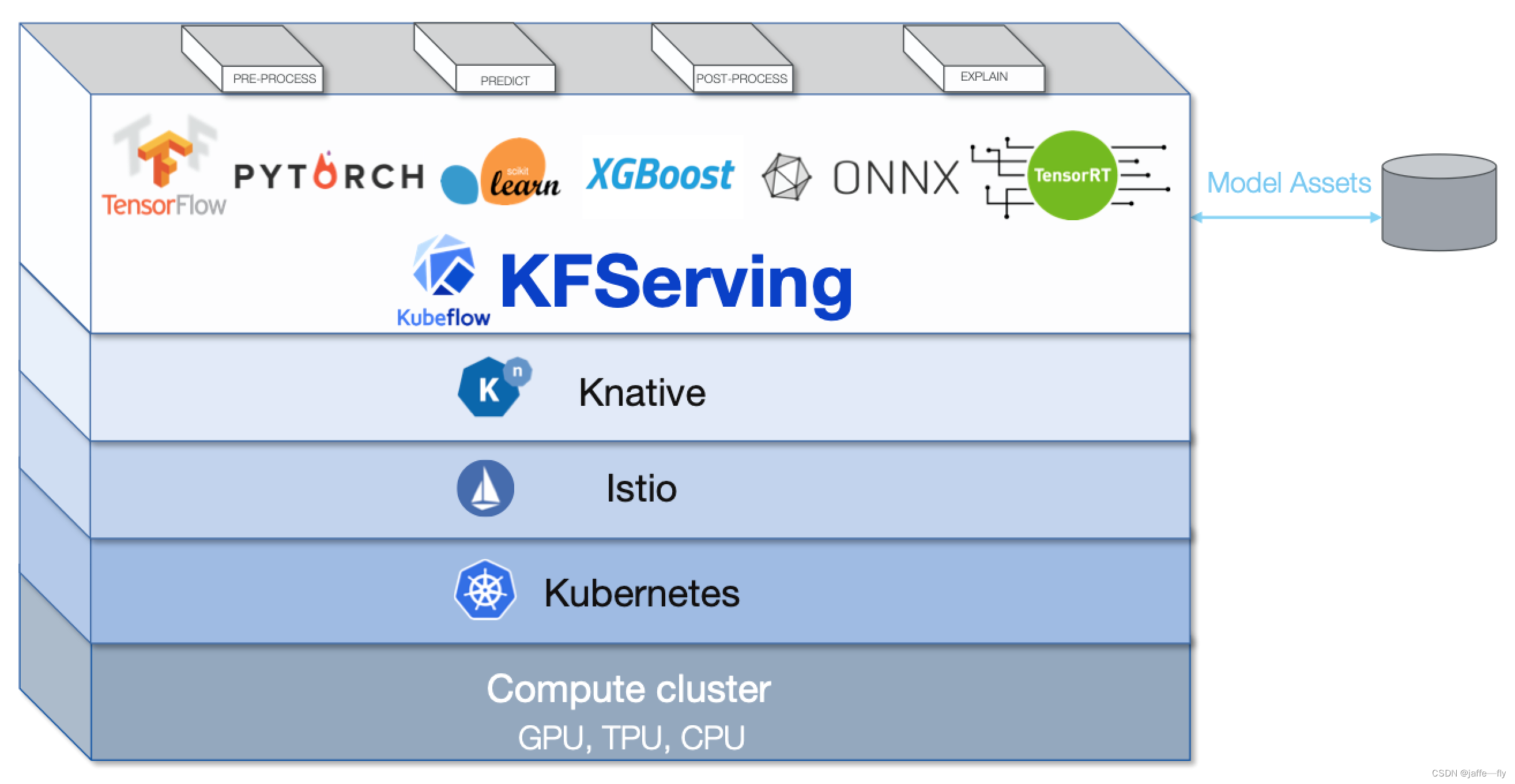

【Kubeflow】KFServing的架构分析,这个结合上面的图理解起来更容易
如果没配置Canary Endpoint,则全部业务分配到Default Endpoint中,为蓝绿发布;如果配置了Canary Endpoint,则为金丝雀发布。
在Transformer、Explainer、Predictor中,Predictor是必须的,是系统的核心,用于响应用户的预测请求,其他两个是可选的。
Explainer提供模型解释。用户可以定义自己的模型解释代码或镜像,KFServing可以使用相关的Endpoint对其进行配置。
Transformer使用户可以在预测和解释工作流程之前定义预处理和后期处理步骤。
KFModel uses the tornado web server
Tornado 和现在的主流 Web 服务器框架(包括大多数 Python 的框架)有着明显的区别:它是非阻塞式服务器,而且速度相当快。得利于其 非阻塞的方式和对 epoll的运用,Tornado 每秒可以处理数以千计的连接,因此 Tornado 是实时 Web 服务的一个 理想框架。
Building the pipeline end to end

第三章
使用opencv构建一个端到端的tensorflow 的计算机视觉模型,并部署到kubeflow
第四章
构建一个结构化数据分类模型,利用TFX 为生产做好准备,利用TF serving 推理模型。
构建tensorflow ecosystem模型,利用tensorboard和 fairness 可视化评估,学习TFX 的不同组件,TFT,TFMA,TFDV等等
TFX架构组件

TFX 用户指南 :TFX 用户指南
Fairness Indicators:Fairness Indicators
第五章
使用酒店预订数据集,训练一个tensorflow 分类模型,使用tensorboard,SHAP,可视化解释模型的结果
针对结构化的数据以及分类任务,集成模型往往会有较好的效果,如XGBOOST的诞生,不仅风靡各大数据竞赛,也在工程中得到了广泛的应用。
对于集成学习方法,效果虽好,但一直无法解决可解释性的问题。我们知道一个xgboost或lightgbm模型,是由N棵树组成,所以对于特定的一个样本,我们无法知道这个样本的特征值是如何影响最终结果。虽说“不管白猫黑猫,抓住耗子的就是好猫”,但在具体任务中,我们还是希望能够获得样本每个特征与其结果之间的关系,特别是针对模型误分的那些样本,如果能够从特征和结果的角度进行分析,对于提高模型效果或是分析异常样本,是非常有帮助的,此外,针对某些特定的场景,如风控等,我们甚至可以分析拒绝样本的具体原因,提供给运营部门,完善业务流程。
来自于博弈论的方法–SHAP(SHapley Additive exPlanations),解决上面的问题。
- shap 文档,
pip install shap - What-If Tool:不编写程序代码的情况下分析机器学习(ML)模型
- What-If Tool 官网
- witwidget :witwidget 包将 What-If Tool 作为小部件添加到 Jupyter 和 Colaboratory notebook中
pip install --upgrade witwidget - LightGBM 是一个框架,它使用基于树的学习算法。它被设计为分布式和高效的,具有以下优点:更快的训练速度和更高的效率,降低内存使用率,更好的准确性,支持并行、分布式和 GPU 学习,能够处理大规模数据。
- Estimator: High level tools for working with models.
第六章
使用Weight & Biases 监控模型,可以看到模型每次迭代的RMSE(均方根误差)图,使用KF serving 在k8s中部署模型,在grafana dashboard 中监控模型请求率,CPU,GPU 消耗
这一节中的超参数搜索用的是 wandb sweeps
- wandb sweeps :https://docs.wandb.com/sweeps/configuration
- WanDB:全网终极入门指南
- 基于wandb sweeps的pytorch超参数调优实验
- 从 kaggle 拉取数据集,用到kaggle-api
第七章
使用房屋销售价格数据集完整的训练,评估,部署 模型,利用Amazon SageMaker Cloud 环境和S3 数据存储。利用容器内置的XGBoost算法,理解SageMaker 的架构。
第八章
使用Streamlit 构建一个端到端的web应用,使用Heroku容器仓库或者k8s集群发布应用
资料
代码以及书籍附图:https://drive.google.com/drive/folders/11gai4-tcJNCMxbIO-RB1kRFbNeTbFFeI
Github 代码:https://github.com/bpbpublications/Continuous-Machine-Learning-with-Kubeflow
出版商网站:https://bpbonline.com/