一、定义和区别
1、一个任务就是一个进程,进程就是资源的集合。比如打开浏览器,启动一个进程。当一个进程需要干很多事的时候,就需要执行多个子任务,这些子任务就是线程。
2、线程是包含在进程中的,每个进程至少有一个默认的线程(主线程),可以有多个线程
3、进程默认有个主线程。而其他子线程则是由主线程启动的。
4、通过线程运行的函数无法return值,如果需要函数返回值,需要专门定义一个list或者字典等来接收
5、多线程运行,一般电脑cpu有几核,就可以同时运行几个线程。但是python中,多线程只能运行一个cpu内核。
因为python中有一个GIL全局解释器,运行python时必须要拿到这把锁才可以执行。遇到I/O操作才会释放。锁只有一把,所以同一时刻也只会有一个线程运行一个cpu内核。那么再写代码运行的时候,为什么有时候多线程看起来确实实在并发,而且比单线程快??请看文章最后
6、多个线程同时修改一个数据时,可能会把数据覆盖。在python2中需要手动加一把锁。但是在python3中会自动加锁
二、多线程
多线程需要引入threading模块:import threading
1、多线程的操作举例:

def run(): time.sleep(3) print('哈哈哈') for i in range(5): t=threading.Thread(target=run)#开启一个线程,用target参数指定要运行的函数,target后跟函数名,不加括号。 t.start()#启动线程
运行结果:
 从上面的运行结果可以看出。5个线程是同时运行的。
从上面的运行结果可以看出。5个线程是同时运行的。
当线程运行的函数需要传递参数时,使用如下:
import threading,time def run(str): time.sleep(3) print('哈哈哈%s:%s'%(time.time(),str)) for i in range(5): t=threading.Thread(target=run,args=(5,))#用args传递参数。注意的是如果参数只有1个,必须加逗号 t.start()
运行结果:

2、线程等待
比如我们来计算多线程执行的时间,代码如下
import threading,time def run(): time.sleep(3) print('哈哈哈哈') start_time=time.time()#记录开始时间 for i in range(5): t=threading.Thread(target=run) t.start() end_time=time.time()#记录结束时间 print('run_time...',end_time-start_time)#结束时间-开始时间得到运行时间
运行结果:
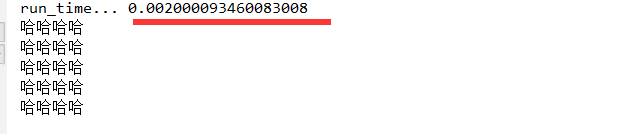
可以看到,运行时间非常小,这肯定是不正确的。毕竟每个线程运行前都有个time.sleep(3)等待3秒,那么多线程运行的时间必定至少得有3秒。那么上述问题在哪里呢?这就关系到我们最开始说的那个默认主线程了。整个python代码运行时是一个进程,默认的有一个主线程。我们开启的5个线程都是由主线程启动的。当主线程把5个子线程自动以后,它就自动往下运行,执行end_time=time.time()了。而不管子线程的运行是否结束。所以最终这个时间计算的是主线程运行的时间。而不是所有线程执行完的时间。
如果想要计算多线程运行时间,那么就要使用线程等待。让主线程等,等到子线程都运行完了以后,再统计结束时间。。线程等待用join().代码修改如下:
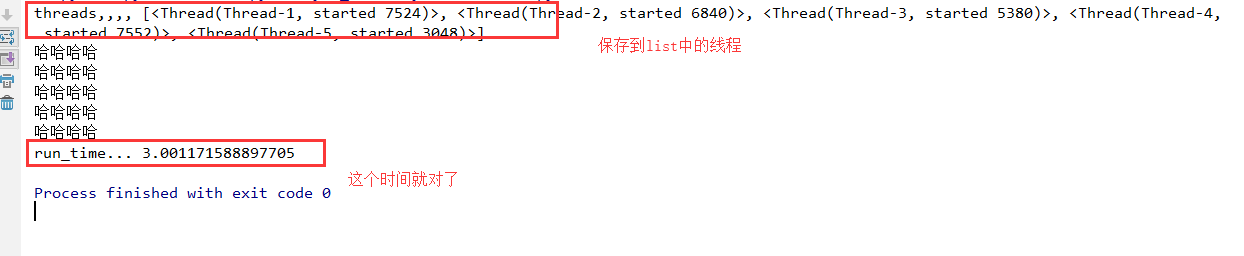
import threading,time def run(): time.sleep(3) print('哈哈哈哈') start_time=time.time() threads=[]#存放启动的五个线程 for i in range(5): t=threading.Thread(target=run) t.start() threads.append(t)#把每个线程都加入到list中保存起来 print('threads,,,,',threads)#可以查看list中保存的5个线程 for t in threads:#主线程循环等待五个子线程 t.join()#等待线程执行结束....虽然是循环挨个等待,但是每个线程都是同时进行的,可能当你等第一个的时候,第二个线程都已经执行完了 #在循环第二个的时候,不用等了直接跳第三个。如果第三四个都执行完了,相当于只等待了第一个执行结束的时间。
#等全部结束了,然后会接着执行下面代码 end_time=time.time()#这个时间就是所有子线程运行结束的时间 print('run_time...',end_time-start_time)
运行结果:
3、守护线程
只要主线程结束,那么子线程立即结束。不管子线程有没有运行完。守护线程的定义:t.setDaemon(True)
示例:
import threading,time def run(): time.sleep(3) print('哈哈哈') for i in range(50): t=threading.Thread(target=run) t.setDaemon(True)#把子线程设置成为守护线程,当主线程死了,守护线程也死 t.start() print('done....运行完毕')
运行结果:

可以看到,并没有打印‘哈哈哈’。这是因为,主线程启动50个线程,然后这50个线程执行run函数的时候,都要必须先time.sleep(3)后才会执行print('哈哈哈')’。但是主线程是继续执行的,很快主线程就执行完了,打印‘done....运行完毕’.因为子线程是主线程的守护线程,所以主线程执行完以后,子线程还没来得及打印就跟着主线程一块死了
4、简单的爬虫示例
爬虫就是抓取网页的数据,保存到本地。然后可以对这些数据进行分析。做其他操作
需求:抓取网页数据,并保存到本地为html格式
urls={'11':'http://www.11.cn', '22':'http://www.22.cn', '33':'http://www.33.cn', '44':'http://www.44.cn'}#爬虫的网址 dic={}#获取每个网址下载并保存的时间 import requests,time def down_html(filename,url): start_time=time.time() req=requests.get(url).content#打开url, .content表示获取url内容返回文件为二进制格式。 open(filename+'.html','wb').write(req)#将抓取到的数据写入一个新的html文件中 end_time=time.time() print(end_time-start_time,url) dic[url]=end_time-start_time#用一个字典获取结果 #并行 threads=[] start_time=time.time() for k,v in urls.items():#循环5次,5个线程启动, t=threading.Thread(target=down_html,args=(k,v))#多线程传参必须用args传参。target的值是函数名,不加括号 #args如果只有一个参数,必须加一个逗号 t.start() threads.append(t) for t in threads:#循环等待子线程运行完 t.join() end_time=time.time() run_time=end_time-start_time print('下载总共花了%s时间'%run_time)
三、多进程
多进程要引入multiprocessing模块,import multiprocessing
示例:
import multiprocessing,threading def my(): print('哈哈哈哈') def run(num): for i in range(num): t=threading.Thread(target=my) t.start() if __name__=='__main__':#多进程必须写这个 for p in range(5): p=multiprocessing.Process(target=run,args=(6,))#进程,args如果只有一个参数,必须加一个逗号 p.start()
四、线程锁
当多个线程需要修改同一个数据时,需要加上线程锁,防止数据被乱改。python2中需要加,python3中不需要。会自动给加
定义一个锁:lock=threading.Lock()
在操作的代码前加锁:lock.aquire()
在操作代码后解锁:lock.release()
示例:
import threading,time num=1 lock=threading.Lock() def run(): time.sleep(1) global num lock.acqurie()#加锁,python3中不加也可以,会默认加 num+=1 lock.release()#解锁 ts=[] for i in range(50): t=threading.Thread(target=run) t.start() ts.append(t) [t.join() for t in ts]#列表生成式,循环等待所有线程结束 print(num)
五、为什么python的多线程不能利用多核CPU,但是咱们在写代码的时候,多线程的确是在并发,而且还比单线程快
原因:因为GIL,python只有一个GIL,运行python时,就要拿到这个锁才能执行,在遇到I/O 操作时会释放这把锁。
如果是纯计算的程序,没有 I/O 操作,解释器会每隔100次操作就释放这把锁,让别的线程有机会 执行(这个次数可以通sys.setcheckinterval
来调整)同一时间只会有一个获得GIL线程在跑,其他线程都处于等待状态
1、如果是CPU密集型代码(循环、计算等),由于计算工作量多和大,计算很快就会达到100,然后触发GIL的释放与在竞争,多个线程来回切换损耗资源,
所以在多线程遇到CPU密集型代码时,单线程会比较快
2、如果是I\O密集型代码(文件处理、网络爬虫),开启多线程实际上是并发(不是并行),IO操作会进行IO等待,线程A等待时,自动切换到线程B,
这样就提升了效率
总结:cpu密集型,单线程快;i/o密集型,多线程快