一、多进程 的 共享内存——Value 和 Array
一般的变量在进程之间是没法进行通讯的,multiprocessing提供了Value和Array模块,他们可以在不通的进程中共同使用。
主进程的内存空间中创建共享的内存,也就是Value和Array两个对象。对象Value被设置成为双精度数(d), 并初始化为0.0。而Array则类似于C语言中的数组,有固定的类型(i, 也就是整数)。
from multiprocessing import Process,Value,Array
def f(n, a,m):
n.value = 3.1415927
m = 5
for i in range(4):
a[i] = -a[i] #定义数组,取反
print(m)
if __name__ == '__main__':
num = Value('d', 0.0) #共享内存 双精度
arr = Array('i', range(4)) #共享内存 相当于数组 整形
m = 10 #全局变量
p = Process(target=f, args=(num, arr, m)) #定义进程
p.start()
p.join()
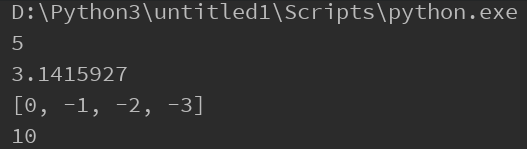
print(num.value)
print(arr[:])
print(m)
运行结果:
二、Python多进程中提供了强大的 Manage 专门用于数据共享。其支持的类型非常多,包括,Value, Array,list,dict, Queue, Lock等。
from multiprocessing import Process, Manager
def func(dt, lt):
for i in range(5):
key = 'arg' + str(i)
dt[key] = i * i
lt += range(11, 16)
if __name__ == "__main__":
manager = Manager()
dt = manager.dict()
lt = manager.list()
p = Process(target=func, args=(dt, lt))
p.start()
p.join(timeout=3)
print(dt)
print(lt)
运行结果

三、进程池
Pool可以提供指定数量的进程,供用户调用,当有新的请求提交到pool中时,如果池还没有满,那么就会创建一个新的进程用来执行该请求;但如果池中的进程数已经达到规定最大值,那么该请求就会等待,直到池中有进程结束,才会创建新的进程。
1、进程池非阻塞
import time
import multiprocessing
def fun(msg):
print("#########start#### {0}".format(msg))
time.sleep(3)
print("#########end###### {0}".format(msg))
if __name__ == '__main__':
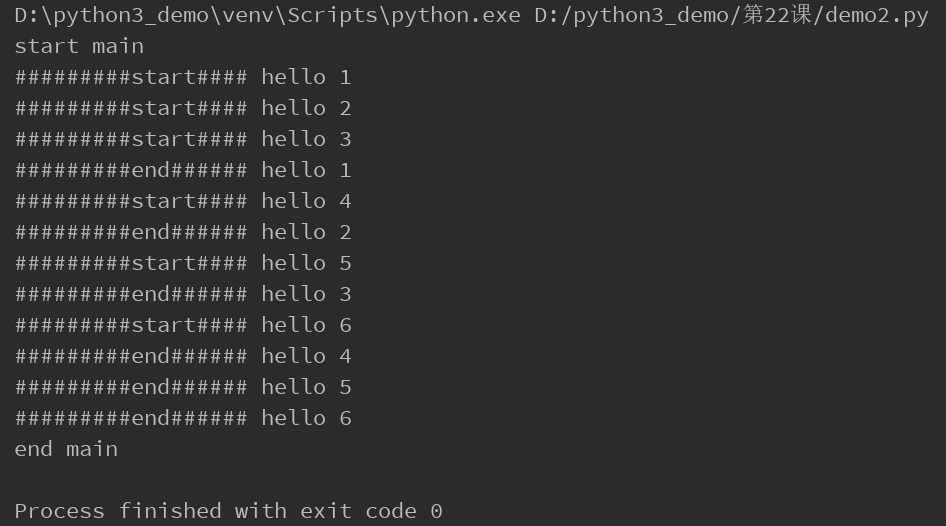
print("start main")
pool = multiprocessing.Pool(processes=3) #定义进程池,定义最大连接数为3
for i in range(1, 7):
msg = "hello {0}".format(i)
pool.apply_async(fun, (msg,)) # 执行时间6s+
# pool.apply(fun, (msg,)) 6*3=18+#执行时间
pool.close() #在调用join之前,要先调用close,否则会报错,close执行完不会有新的进程加入到pool
pool.join() #join 是等待所有的子进程结束
print("end main")
运行结果
2、阻塞 与 非阻塞 的区别:
pool.apply_async 非阻塞,定义的进程池最大数的同时执行
pool.apply 一个进程结束,释放回进程池,开始下一个进程
—————————————————第二部分——多线程——————————————————
一、多线程
1、Python中提供了 threading模块 来进行多线程的操作。
2、实现多线程的两种方式:
① 将要执行的方法作为参数传给Thread的构造方法 (和多进程类似)
t = threading.Thread(target=action, args=(i,))
示例:
class MyThread(threading.Thread):
def __init__(self, arg):
super(MyThread, self).__init__()#注意:一定要显式的调用父类的初始化函数。
self.arg = arg
def run(self):#定义每个线程要运行的函数
time.sleep(5)
with open('{0}.txt'.format(self.arg), 'wb') as f:
f.write(str(self.arg))
print 'the arg is:%s\r' % self.arg
运行结果
②通过继承的方式
从Thread继承,并重写run()
import threading
import time
class Hello(threading.Thread):
def __init__(self, args):
super(Hello, self).__init__()
self.args = args
def run(self):
print("开始子进程 {0}".format(self.args))
time.sleep(1)
print("结束子进程 {0}".format(self.args))
if __name__ == '__main__':
a = 1
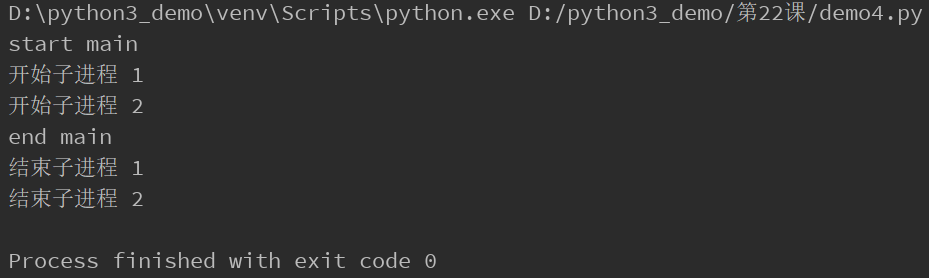
print("start main")
t1 = Hello(1)
t2 = Hello(2)
t1.start()
t2.start()
print("end main")
运行结果
3、线程是应用程序中工作的最小单元。