前期文章的分享,我们介绍了YOLOv7人体姿态估计的文章以及MediaPipe人体姿态估计方面的文章。由于YOLOv7与MediaPipe都可以进行人体姿态估计,我们本期就对比一下2个算法的不同点。
利用机器学习,进行人体33个2D姿态检测与评估
人工智能领域也卷了吗——YOLO系列又被刷新了,YOLOv7横空出世
基于深度学习的人体姿态估计
自2014年Google首次发布DeepPose以来,基于深度学习的姿态估计算法已经取得了较大的进步。这些算法通常分两个阶段工作。
人员检测
关键点定位根据设备[CPU/GPU/TPU]的不同,不同框架的性能有所不同。有许多两阶段姿态估计模型在基准测试中表现良好,例如:Alpha Pose、OpenPose、Deep Pose等等。然而,由于两阶模型相对复杂,获得的实时性能非常昂贵。这些模型在GPU上运行得很快,但在CPU上运行的较慢。就效率和准确性而言,MediaPipe是一个很好的姿态估计框架。它在CPU上生成实时检测,且速度很快。
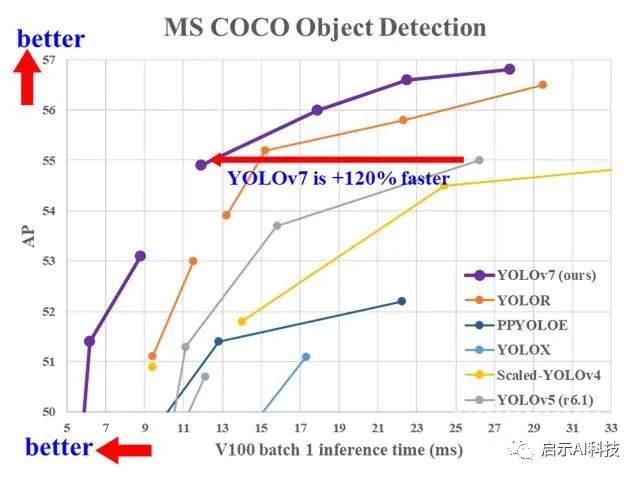
YOLOv7
与传统的姿态估计算法不同,YOLOv7姿态是一个单级多人关键点检测器。它具有自顶向下和自底向上两种方法中的优点。YOLOv7姿态是在COCO数据集上训练的,前期的文章我们也分享过YOLOv7人体姿态检测的代码。