2021SC@SDUSC
目录
一、前情回顾
1.1 PP-OCR文字识别策略
策略的选用主要是用来增强模型能力和减少模型大小。下面是PP-OCR文字识别器所采用的九种策略:
- 轻主干,选用采用 MobileNetV3 large x0.5 来权衡精度和效率;
- 数据增强,BDA (Base Dataaugmented)和TIA (Luo et al. 2020);
- 余弦学习率衰减,有效提高模型的文本识别能力;
- 特征图辨析,适应多语言识别,进行向下采样 feature map的步幅修改;
- 正则化参数,权值衰减避免过拟合;
- 学习率预热,同样有效;
- 轻头部,采用全连接层将序列特征编码为预测字符,减小模型大小;
- 预训练模型,是在 ImageNet 这样的大数据集上训练的,可以达到更快的收敛和更好的精度;
- PACT量化,略过 LSTM 层;
1.2 本文介绍策略
本篇文章继续介绍OCR的轻量化策略。根据前两篇文章的描述,paddleOCR采用了CRNN结合CTC的baseline。但是同时paddle OCR也提供了除此之外的其他算法实现,并经过了测试实验(结果如下图)。包含Rosetta、STAR-Net、RARE和SRN等算法,并同时完成了在Resnet34-vd骨干和MobileNetV3骨干上的实现。

下图是paddle OCR识别算法分类:

下图是实际上paddle OCR识别算法的实现原理:

通过前面的文章介绍了SRN算法和CRNN算法的实现原理,从本篇文章开始,将会介绍paddle OCR实现的Rosetta、STAR-Net、RARE算法。
本篇文章首先介绍基于Attention的RARE文字识别算法。
二、RARE算法介绍
2.1 什么是RARE算法
RARE(Robust text recognizer with Automatic Rectification,具有自动校正功能的鲁棒性文本识别器)是由空间变形网络(STN)和序列识别网络组成,即TPS-VGG-LSTM-Attn(Seq2seq+Attention)
首先通过predicted Thin-Plate-Spline(TPS)对图像进行校正,为后续的序列识别网络(通过序列识别方法识别文本)生成更“可读”的图像。
2.2 RARE算法在文字识别模型中的实现
算法实现流程
基于Attention的OCR解码算法,把OCR文字识别当成文字翻译任务,即通过Attention Decoder出文字序列。
RNN -> Seq2Seq

左图是RNN结构,右图是Seq2Seq结构。
RNN的输入序列和输出序列必须有相同的时间长度,而机器翻译以及文字识别任务都是输入输出不对齐的,不能直接使用RNN结构进行解码。于是在Seq2Seq结构中,将输入序列进行Encoder编码成一个统一的语义向量Context,然后送入Decoder中一个一个解码出输出序列。在Decoder解码过程中,第一个输入字符为<start>,然后不断将前一个时刻的输出作为下一个时刻的输入,循环解码,直到输出<stop>字符为止 。
Seq2Seq -> Attention Decoder
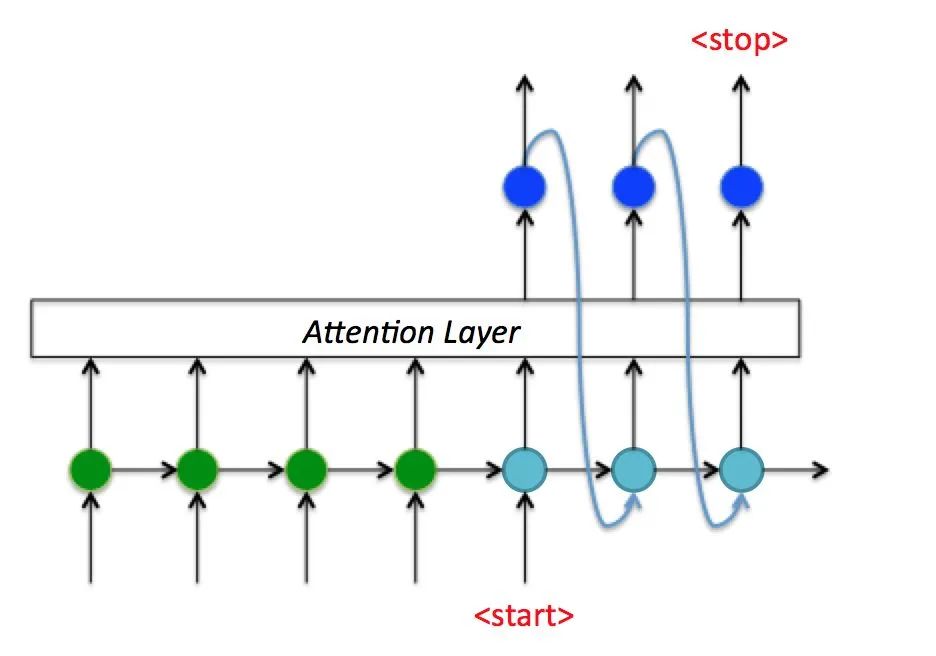
如上图所示,利用Encoder所有隐藏层状态解决Context长度限制问题。于是Attention Decoder在Seq2Seq的基础上,增加了一个Attention Layer。
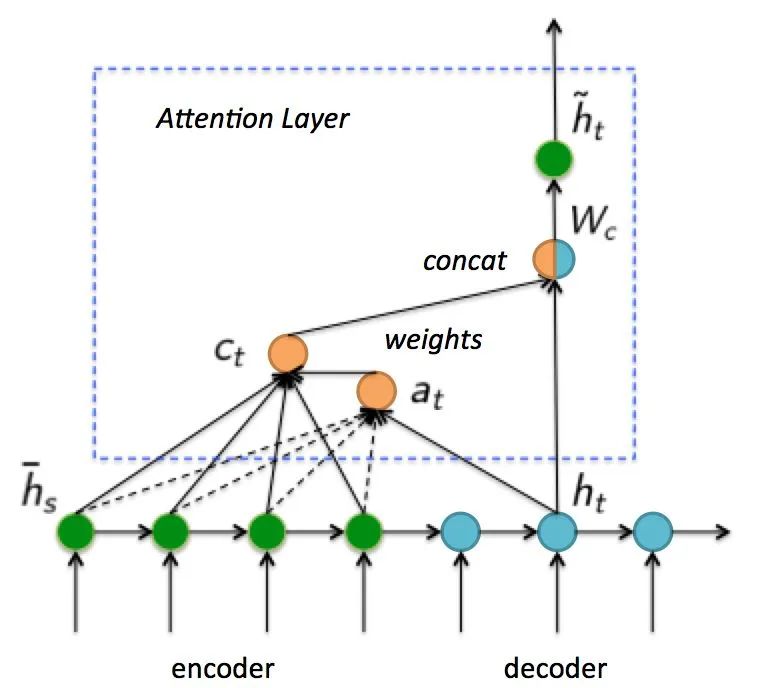
如上图所示,在Attention Layer中,Decoder时,每个时刻的解码状态跟Encoder的所有隐藏层状态进行cross-attention计算,cross-attention将当前解码的隐藏层状态和encoder的所有隐藏层状态做相关性计算,然后对encoder的所有隐藏层加权求和,最后和当前解码的隐藏层状态concat得到最终的状态。
三、RARE算法在文字识别模型中的代码实现
3.1 代码位置
![]()
3.2 关键代码
class AttentionHead(nn.Layer):
def __init__(self, in_channels, out_channels, hidden_size, **kwargs):
super(AttentionHead, self).__init__()
self.input_size = in_channels
self.hidden_size = hidden_size
self.num_classes = out_channels
self.attention_cell = AttentionGRUCell(
in_channels, hidden_size, out_channels, use_gru=False)
self.generator = nn.Linear(hidden_size, out_channels)
def _char_to_onehot(self, input_char, onehot_dim):
input_ont_hot = F.one_hot(input_char, onehot_dim)
return input_ont_hot
def forward(self, inputs, targets=None, batch_max_length=25):
batch_size = paddle.shape(inputs)[0]
num_steps = batch_max_length
hidden = paddle.zeros((batch_size, self.hidden_size))
output_hiddens = []
if targets is not None:
for i in range(num_steps):
char_onehots = self._char_to_onehot(
targets[:, i], onehot_dim=self.num_classes)
(outputs, hidden), alpha = self.attention_cell(hidden, inputs,
char_onehots)
output_hiddens.append(paddle.unsqueeze(outputs, axis=1))
output = paddle.concat(output_hiddens, axis=1)
probs = self.generator(output)
else:
targets = paddle.zeros(shape=[batch_size], dtype="int32")
probs = None
char_onehots = None
outputs = None
alpha = None
for i in range(num_steps):
char_onehots = self._char_to_onehot(
targets, onehot_dim=self.num_classes)
(outputs, hidden), alpha = self.attention_cell(hidden, inputs,
char_onehots)
probs_step = self.generator(outputs)
if probs is None:
probs = paddle.unsqueeze(probs_step, axis=1)
else:
probs = paddle.concat(
[probs, paddle.unsqueeze(
probs_step, axis=1)], axis=1)
next_input = probs_step.argmax(axis=1)
targets = next_input
return probs
class AttentionGRUCell(nn.Layer):
def __init__(self, input_size, hidden_size, num_embeddings, use_gru=False):
super(AttentionGRUCell, self).__init__()
self.i2h = nn.Linear(input_size, hidden_size, bias_attr=False)
self.h2h = nn.Linear(hidden_size, hidden_size)
self.score = nn.Linear(hidden_size, 1, bias_attr=False)
self.rnn = nn.GRUCell(
input_size=input_size + num_embeddings, hidden_size=hidden_size)
self.hidden_size = hidden_size
def forward(self, prev_hidden, batch_H, char_onehots):
batch_H_proj = self.i2h(batch_H)
prev_hidden_proj = paddle.unsqueeze(self.h2h(prev_hidden), axis=1)
res = paddle.add(batch_H_proj, prev_hidden_proj)
res = paddle.tanh(res)
e = self.score(res)
alpha = F.softmax(e, axis=1)
alpha = paddle.transpose(alpha, [0, 2, 1])
context = paddle.squeeze(paddle.mm(alpha, batch_H), axis=1)
concat_context = paddle.concat([context, char_onehots], 1)
cur_hidden = self.rnn(concat_context, prev_hidden)
return cur_hidden, alpha
class AttentionLSTM(nn.Layer):
def __init__(self, in_channels, out_channels, hidden_size, **kwargs):
super(AttentionLSTM, self).__init__()
self.input_size = in_channels
self.hidden_size = hidden_size
self.num_classes = out_channels
self.attention_cell = AttentionLSTMCell(
in_channels, hidden_size, out_channels, use_gru=False)
self.generator = nn.Linear(hidden_size, out_channels)
def _char_to_onehot(self, input_char, onehot_dim):
input_ont_hot = F.one_hot(input_char, onehot_dim)
return input_ont_hot
def forward(self, inputs, targets=None, batch_max_length=25):
batch_size = inputs.shape[0]
num_steps = batch_max_length
hidden = (paddle.zeros((batch_size, self.hidden_size)), paddle.zeros(
(batch_size, self.hidden_size)))
output_hiddens = []
if targets is not None:
for i in range(num_steps):
# one-hot vectors for a i-th char
char_onehots = self._char_to_onehot(
targets[:, i], onehot_dim=self.num_classes)
hidden, alpha = self.attention_cell(hidden, inputs,
char_onehots)
hidden = (hidden[1][0], hidden[1][1])
output_hiddens.append(paddle.unsqueeze(hidden[0], axis=1))
output = paddle.concat(output_hiddens, axis=1)
probs = self.generator(output)
else:
targets = paddle.zeros(shape=[batch_size], dtype="int32")
probs = None
for i in range(num_steps):
char_onehots = self._char_to_onehot(
targets, onehot_dim=self.num_classes)
hidden, alpha = self.attention_cell(hidden, inputs,
char_onehots)
probs_step = self.generator(hidden[0])
hidden = (hidden[1][0], hidden[1][1])
if probs is None:
probs = paddle.unsqueeze(probs_step, axis=1)
else:
probs = paddle.concat(
[probs, paddle.unsqueeze(
probs_step, axis=1)], axis=1)
next_input = probs_step.argmax(axis=1)
targets = next_input
return probs
class AttentionLSTMCell(nn.Layer):
def __init__(self, input_size, hidden_size, num_embeddings, use_gru=False):
super(AttentionLSTMCell, self).__init__()
self.i2h = nn.Linear(input_size, hidden_size, bias_attr=False)
self.h2h = nn.Linear(hidden_size, hidden_size)
self.score = nn.Linear(hidden_size, 1, bias_attr=False)
if not use_gru:
self.rnn = nn.LSTMCell(
input_size=input_size + num_embeddings, hidden_size=hidden_size)
else:
self.rnn = nn.GRUCell(
input_size=input_size + num_embeddings, hidden_size=hidden_size)
self.hidden_size = hidden_size
def forward(self, prev_hidden, batch_H, char_onehots):
batch_H_proj = self.i2h(batch_H)
prev_hidden_proj = paddle.unsqueeze(self.h2h(prev_hidden[0]), axis=1)
res = paddle.add(batch_H_proj, prev_hidden_proj)
res = paddle.tanh(res)
e = self.score(res)
alpha = F.softmax(e, axis=1)
alpha = paddle.transpose(alpha, [0, 2, 1])
context = paddle.squeeze(paddle.mm(alpha, batch_H), axis=1)
concat_context = paddle.concat([context, char_onehots], 1)
cur_hidden = self.rnn(concat_context, prev_hidden)
return cur_hidden, alpha
总结
以上简单介绍了基于attention的文字识别模型。本篇及之后陆续发布的文章,将会陆续对之前的策略介绍进行补充(与之前介绍策略的文章的发布顺序没有太大关系,在哪个部分有新的认识就会补充哪里)欢迎大家指正。