一、理论学习
1、完成慕课第十章的相关学习
2、学习“设计和开发”
在需求分析阶段就应该对程序开发的框架有一个设计,这周在实践中明显感觉代码修改的地方比较多,扩展性非常不好,归根揭底就是最开始的设计没弄好,代码的框架搭的不够好,可见设计的重要性。
3、进一步熟悉UML建模
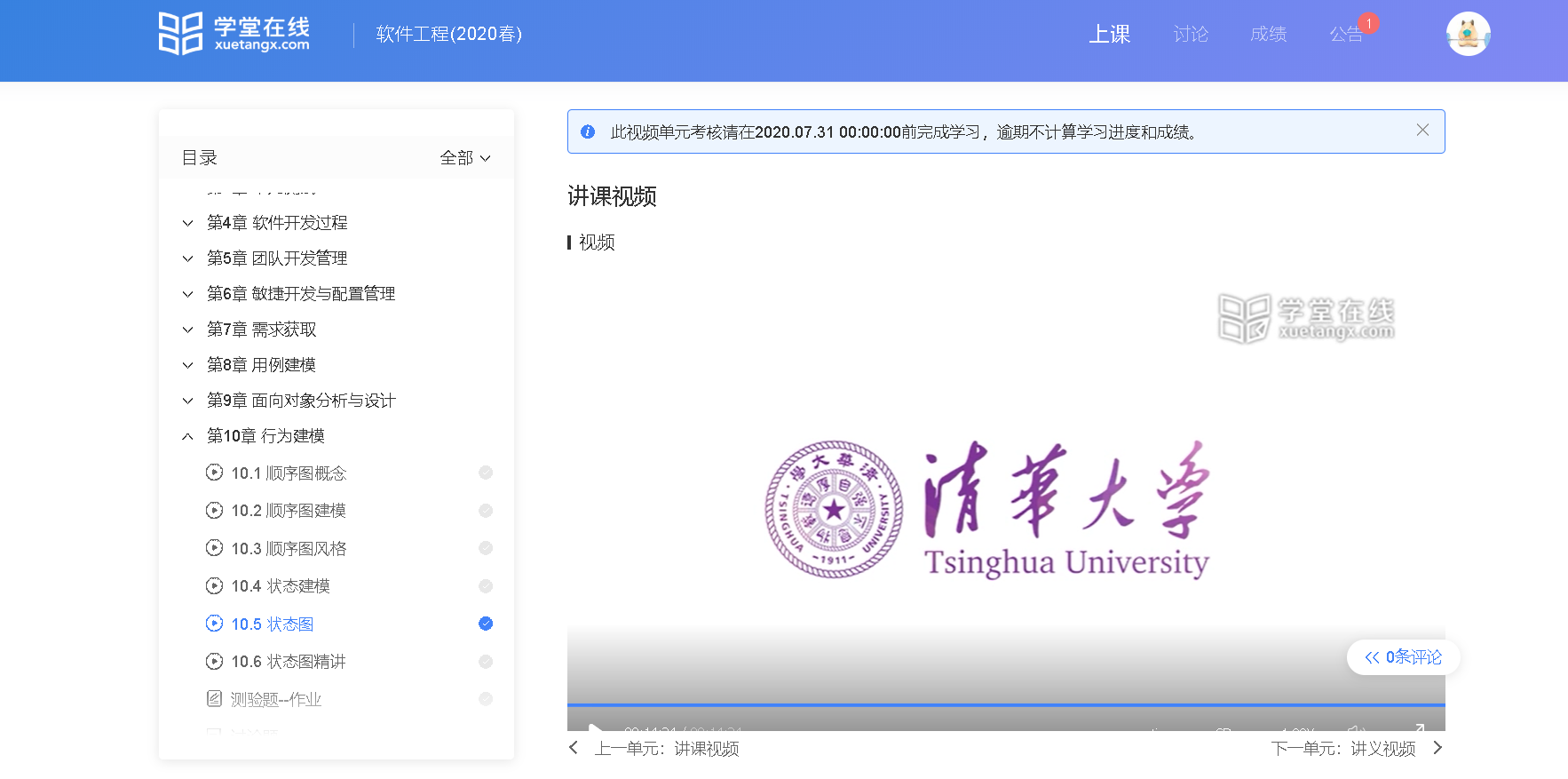
出口成诗顺序图
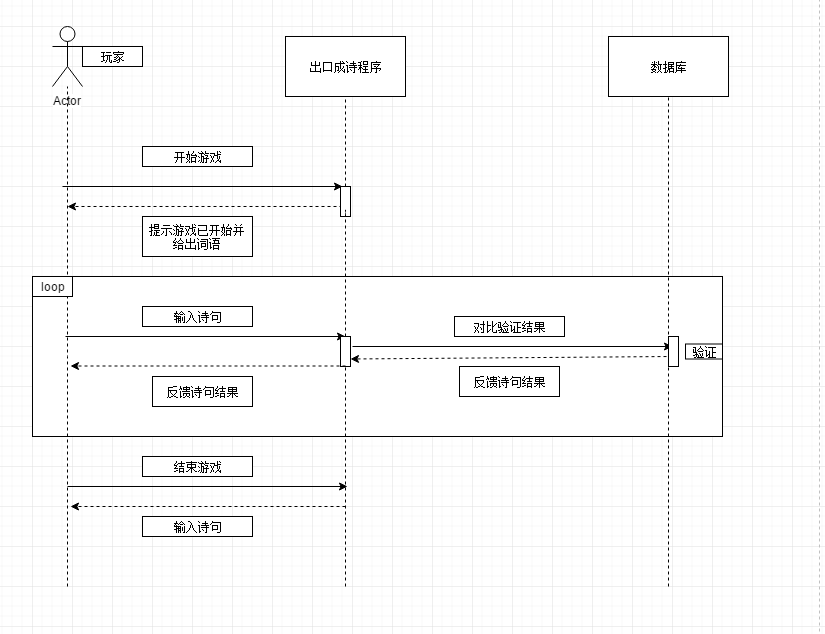
飞花令顺序图
二、实践学习
1、扩充诗词库
本周在上次129首的古诗基础上扩充了320首广为熟知的唐诗三百首,和之前采用一样的方式对网站的数据进行爬取存到本地txt文件再处理后导入数据库中。
1 from urllib import request,error 2 from bs4 import BeautifulSoup 3 4 if __name__ == '__main__': 5 6 url = "https://so.gushiwen.org/gushi/tangshi.aspx" 7 8 try: 9 10 req = request.Request(url) 11 12 rsp = request.urlopen(req) 13 14 html = rsp.read().decode() 15 soup=BeautifulSoup(html,'lxml') 16 html=soup.prettify() 17 div = soup.find_all('a',{'target':'_blank'}) 18 div = div[1:-1] 19 name = div[0].string 20 f = open('D:\桌面\诗词库2.txt','w+',encoding='utf-8') 21 num = 1 22 for i in div: 23 # print(i.string) 24 # print(i.get('href')) 25 name = i.string 26 url = i.get('href') 27 req = request.Request('https://so.gushiwen.org'+url) 28 rsp = request.urlopen(req) 29 html = rsp.read().decode() 30 31 soup=BeautifulSoup(html,'lxml') 32 html=soup.prettify() 33 div2 = soup.find('div',{'class':'contson'}) 34 # print(div2.get('content')) 35 print(div2.get_text()) 36 f.writelines([str(num),name,'\n',div2.get_text(),'\n']) 37 f.close 38 num+=1 39 40 except error.URLError as e: 41 print("URLError:{0}".format(e.reason)) 42 print("URLError:{0}".format(e)) 43 44 45 except Exception as e: 46 print(e)
然后从把txt文件处理后导入数据库
import sys import re import os,time import pymysql conn = pymysql.connect(host='localhost', port=3306, user='root', passwd='newbegin',db='lsj',charset='utf8') cur = conn.cursor(cursor=pymysql.cursors.DictCursor) class WordCreate(): def __init__(self,path): ''' 导入文件进行解析 ''' with open(path,encoding="utf-8") as file: content = file.read() x = re.findall(r'[(|(](.*?)[)|)]', content) print(x) for i in x: zifu = '('+i+')' content = content.replace(zifu,'') content = re.split(r'\d', content) content = [i for i in content if i != ''] self.sc_list = [] for i in content: weak_list = re.split(r'[、。;!?\n\s*]',i) weak_list = [i for i in weak_list if i != ''] self.sc_list.append(weak_list) # print(self.sc_list) def OperationSql(self): num=130 for i in self.sc_list: for _ in range(62-len(i)): #导入诗词为62 导入赏析为61 i.append('NULL') # print(len(i)) num2 = 1 for _ in range(61): sql = "UPDATE poetry SET yiwen_{}='{}' WHERE id ={}".format(num2, i[num2-1], num) print(sql) cur.execute(sql) num2 += 1 # for _ in range(61): # sql = "UPDATE poetry SET sentense_{}='{}' WHERE id ={}".format(num2, i[num2], num) # print(sql) # cur.execute(sql) # num2 += 1 conn.commit() num+=1 def main(): generator = WordCreate('D:\桌面\诗词库-2-赏析.txt') #选择合适的路径 generator.OperationSql() if __name__ == '__main__': main()
后续准备继续扩充数据库,尽量选用比较常见且朗朗上口的古诗词。
2、编写新的功能“你说我猜”
这个游戏在中国诗词大会中是评委嘉宾对一句古诗进行描绘,描绘过程中不能出现诗句中的字或词,想实现这个功能比较难,我就简化了一下,给玩家直接提供古诗句的白话赏析,难度比较低,玩家根据这句赏析进行古诗的预测。
首先还是在网站上爬取了400多首诗对应的赏析

这样对应存好后也同样存到数据库中,对应每一句诗一句赏析。
相应的修改了调用数据库、GUI界面等文件,初步做成的界面:




这个游戏功能还有挺多bug还需要调试,整个程序框架编写有时候也有一些问题需要调整。
这周修改过的文件都上传github中,第二次扩充数据库,获取第一批诗词数据的赏析,获取第二批诗词数据的赏析,导入数据库,调用数据库,游戏界面。