更好的阅读体验:PySpark基础入门(2):RDD及其常用算子 - 掘金 (juejin.cn)
目录
RDD简介
RDD(Resilient Distributed Dataset),是一个弹性分布式数据集,是Spark中最基本的数据抽象,代表一个不可变、可分区、里面的元素可并行计算的集合
Dataset:一个数据集合,用于存放数据的。
Distributed:RDD中的数据是分布式存储的,可用于分布式计算。
Resilient:RDD中的数据可以存储在内存中或者磁盘中
RDD的特点
- RDD是有分区的;RDD的分区是数据存储的最小单位
- RDD的方法会作用在其所有的分区上
- RDD之间是有依赖关系的(血缘关系)
- Key-Value型的RDD可以有分区器(Key-Value型,指的是RDD中存储的数据是二元组)
- RDD的分区规划会尽量靠近数据所在的分区器(也就是说,Exector和存储数据的block尽量在一台服务器上,这样只需磁盘读取,无需网络IO;但需要在确保并行计算能力的前提下,实现本地读取)
RDD Coding
SparkContext
SparkContext对象是RDD编程的程序入口对象
扫描二维码关注公众号,回复: 16284900 查看本文章
本质上, SparkContext对编程来说, 主要功能就是创建第一个RDD出来
conf = SparkConf().setAppName("test").setMaster("local[*]") # 构建SparkContext对象 sc = SparkContext(conf=conf)有关conf的配置:
1、
setMaster(),如果是本地运行,就填local,如果提交到yarn,则填"yarn"2、设置依赖文件:
conf.set("spark.submit.pyFiles", 文件)文件的格式可以是.py,也可以是.zip
在linux中提交时,通过
--py-files .zip/.py来将依赖文件提交
RDD的创建方式
并行化创建(parallelize)
方法:
sc.parallelize(集合对象,分区数)rdd = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9]) print("默认分区数: ", rdd.getNumPartitions()) rdd = sc.parallelize([1, 2, 3], 3) print("分区数: ", rdd.getNumPartitions())
getNumPartitions:获取当前rdd的分区数
读取文件创建(textFile)
方法:
sc.textFile(文件路径,最小分区数)这里的文件路径可以时相对路径也可以是绝对路径;可以读取本地数据,也可以读取hdfs数据;
注意,从Windows本地读取文件和SSH连接到linux上读取文件路径不同
Windows本地直接写文件路径就行,Linux上路径为
file://+/home/wuhaoyi/......# 读取本地文件 sc.textFile("../data/input/words.txt") # 设置最小分区数 sc.textFile("../data/input/words.txt", 3) # 注意,设置的最小分区数太大时会失效 sc.textFile("../data/input/words.txt", 100) # 设置100分区不会生效 # 读取hdfs文件 sc.textFile("hdfs://10.245.150.47:8020/user/wuhaoyi/input/words.txt")最小分区数不设置的话则采用默认值,默认分区数与CPU无关,如果是本地文件,则与文件大小有关;如果是HDFS上的文件,则与块的多少有关
方法:
sc.wholeTextFiles(文件路径,最小分区数)作用:读取一堆小文件
rdd= sc.wholeTextFiles("../data/input/tiny_files")其使用与
textFile方法基本相同,需要注意的是,该API用于读取小文件,也能以文件夹作为参数,读取文件夹中的所有小文件;因此分区太多的话会导致很多不必要的shuffle,所以应当尽量少分区读取数据;分区数最大能设置到与文件数量相同;rdd= sc.wholeTextFiles("../data/input/tiny_files/",6) print("当前分区数为",rdd.getNumPartitions())由于读取的文件有5个,因此将分区设置为6是无效的:
通过该API创建的rdd格式如下:


RDD算子
算子:分布式集合对象上的API
RDD的算子分为Transformation(转换算子)和Action(动作算子)两种;
Transformation算子:
返回值依旧是一个RDD对象;
特点:该算子是懒加载的,如果没有action算子,transformation算子是不工作的
Action算子:
返回值不再是RDD对象
transformation算子相当于是构建一个执行计划,而action算子让这个执行计划开始工作
常用transformation算子
map
功能:将RDD中的数据一条条地按照定义地函数逻辑进行处理
示例:
rdd.map(lambda x:x*10)flatMap
功能:对RDD对对象执行map操作,并解除嵌套
解除嵌套的含义:
示例:
rdd = sc.parallelize(["hadoop spark hadoop", "spark hadoop hadoop", "hadoop flink spark"]) rdd2 = rdd.flatMap(lambda line: line.split(" ")) print(rdd2.collect())运行结果:
reduceByKey
功能:针对KV型的RDD,自动按照key进行分组,然后按照聚合逻辑完成组内数据(value)的聚合
示例:
rdd = sc.parallelize([('a', 1), ('a', 1), ('b', 1), ('b', 1), ('a', 1)]) # 以key为单位进行计数 print(rdd.reduceByKey(lambda a, b: a + b).collect())结果:
需要注意的是,reduceByKey只负责聚合操作,不针对分组,分组是根据key来自动完成的;
groupBy
功能:将RDD的数据进行分组
语法:
rdd.groupBy(func);其中func是分组逻辑函数示例:
rdd = sc.parallelize([('a', 1), ('a', 1), ('b', 1), ('b', 2), ('b', 3)]) # 根据key进行分组 # t代表的是每一个元组,t[0]代表的就是key result = rdd.groupBy(lambda t: t[0]) print(result.collect())结果:
filter
功能:对RDD中的数据进行过滤
语法:
rdd.filter(func);func的返回值必须是true或false示例:
rdd = sc.parallelize([1, 2, 3, 4, 5, 6]) # 通过Filter算子, 过滤奇数 result = rdd.filter(lambda x: x % 2 == 1) print(result.collect())结果:
distinct
功能:对RDD中的数据进行去重
语法:
rdd.distinct(去重分区数量)(参数一般不填)示例:
rdd = sc.parallelize([1, 1, 1, 2, 2, 2, 3, 3, 3]) print(rdd.distinct().collect())结果:
union
功能:将两个rdd合并为1个rdd
语法:
rdd.union(other_rdd)示例:
rdd1 = sc.parallelize([1, 1, 3, 3]) rdd2 = sc.parallelize(["a", "b", "a",(1,23),[1,2]]) rdd3 = rdd1.union(rdd2) print(rdd3.collect())结果:
由此也可以看出,不同类型的rdd也是可以混合的;
join
功能:对两个rdd实现JOIN操作(类似与SQL的连接,也能实现左外/右外连接)
join操作只能作用与二元组
语法:
rdd.join(other_rdd);rdd.leftOuterJoin(other_rdd);rdd.rightOuterJoin(other_rdd)示例:
rdd1 = sc.parallelize([ (1001, "zhangsan"), (1002, "lisi"), (1003, "wangwu"), (1004, "zhaoliu") ]) rdd2 = sc.parallelize([ (1001, "销售部"), (1002, "科技部")]) # 连接 print(rdd1.join(rdd2).collect()) # 左外连接 print(rdd1.leftOuterJoin(rdd2).collect())结果:
intersection
功能:求两个rdd的交集
语法:
rdd.intersection(other_rdd)示例:
rdd1 = sc.parallelize([('a', 1), ('a', 3)]) rdd2 = sc.parallelize([('a', 1), ('b', 3)]) # 求交集 rdd3 = rdd1.intersection(rdd2) print(rdd3.collect())结果:
glom
功能:对rdd的数据进行嵌套;嵌套按照分区来进行
语法:
rdd.glom()示例:
rdd = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9], 2) print(rdd.glom().collect())结果:
如果想解嵌套的话,只需使用
flatMap即可:rdd = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9], 2) print(rdd.glom().flatMap(lambda x:x).collect())结果:
groupByKey
功能:针对KV型rdd,按照key进行分组
与reduceByKey相比,没有聚合的操作
语法:
rdd.groupByKey(func)示例:
rdd = sc.parallelize([('a', 1), ('a', 1), ('b', 1), ('b', 1), ('b', 1)]) rdd2 = rdd.groupByKey() print(rdd2.map(lambda x: (x[0], list(x[1]))).collect())结果:
sortBy
功能:对rdd中的数据进行排序
语法:
rdd.sortBy(func,ascending=False,numPartitions=1)ascending:True为升序,False为降序
numPartitions:用多少分区来进行排序;如果要全局有序,排序分区数应设置为1
示例:
rdd = sc.parallelize([('c', 3), ('f', 1), ('b', 11), ('c', 3), ('a', 1), ('c', 5), ('e', 1), ('n', 9), ('a', 1)], 3) # 按照key来进行全局降序排序 print(rdd.sortBy(lambda x: x[0], ascending=False, numPartitions=1).collect())结果:
sortByKey
功能:针对KV型rdd,根据key进行排序
语法:
rdd.sortByKey(ascending=False,numPartitions=1,keyfunc=<function RDD.lambda>)keyfunc是在排序前对key进行的预处理操作,其余参数和sortBy一样
示例:
rdd = sc.parallelize([('a', 1), ('E', 1), ('C', 1), ('D', 1), ('b', 1), ('g', 1), ('f', 1), ('y', 1), ('u', 1), ('i', 1), ('o', 1), ('p', 1), ('m', 1), ('n', 1), ('j', 1), ('k', 1), ('l', 1)], 3) # 先将key全部转化为小写字母,然后根据key值进行全局升序排序 print(rdd.sortByKey(ascending=True, numPartitions=1, keyfunc=lambda key: str(key).lower()).collect())结果:
这里需要注意,排序后的rdd中,key的值并不会因为预处理而发生改变
mapValues
功能:针对二元组RDD,对其values进行map操作;
语法:
rdd.mapValues(func)示例:
当然,也可以用map来实现;





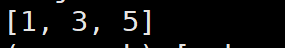
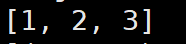









常用action算子
countByKey
功能:统计key出现的次数,一般用于KV型rdd
语法:
rdd.countByKey()collect
功能:将rdd各个分区的数据统一收集到Driver中,形成一个List对象
语法:
rdd.collect()reduce
功能:对rdd中的数据按照输入的逻辑进行聚合
语法:
rdd.reduce(func)fold
功能:和reduce类似,对rdd中的数据进行聚合,但聚合是有初始值的
语法:
rdd.fold(value,func)注意:各个分区聚合时需要带上初始值;分区之间聚合时,也需带上初始值;
示例:
rdd = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9], 3) print(rdd.fold(10, lambda a, b: a + b))结果:85
初始值为10,三个分区内聚合都需+10,分区间的聚合再+10
first
功能:取出rdd的第一个元素
语法:
rdd.first()take
作用:取出rdd的前N个元素,组成list返回
语法:
rdd.take(N)top
功能:对rdd中的数据进行降序排序,取出前N个组成list返回
语法:
rdd.top(N)注意:top的排序不受分区的影响;
示例:
sc.parallelize([1,2,3,4,5,6,7],2).top(5)结果:
count
功能:统计rdd中有多少条数据
语法:
rdd.count()takeSample
功能:随机抽样rdd的数据
语法:
rdd.takeSample(是否重复,采样数,随机数种子)是否重复:True允许重复,False不允许重复;这里的重复指的是取同一位置上的数据,与数据的内容无关
采样数:一共取多少数据
随机数种子:随便一个数字即可;这个参数一般不填,如果两次采样填写同一个数字,则两次采样的结果相同
示例:
rdd = sc.parallelize([1, 3, 5, 3, 1, 3, 2, 6, 7, 8, 6], 1) print(rdd.takeSample(False, 5, 1))结果:
运行两次,发现样本完全相同
takeOrdered
功能:对RDD进行排序,取前N个
语法:
rdd.takeOrdered(N,func)通过func中的lambda表达式,可以实现升序/降序的操作;与top相比,不止可以进行升序排序
默认是升序排序
示例:
rdd = sc.parallelize([1, 3, 2, 4, 7, 9, 6], 1) # 升序 print(rdd.takeOrdered(3)) # 降序 print(rdd.takeOrdered(3, lambda x: -x))结果:
可以看到,lambda表达式中的函数在排序前对数据进行了处理,但不会对原始的数据造成影响
foreach
功能:对rdd中的数据进行输入逻辑的操作(与map类似,只不过没有返回值)
语法:
rdd.foreach(func)示例:
rdd = sc.parallelize([1, 3, 2, 4, 7, 9, 6], 1) result = rdd.foreach(lambda x: print(x * 10))结果:
不经过driver,由executors直接进行打印输出
saveAsTextFile
功能:将rdd的数据写入文本文件中(本地或hdfs)
语法:
rdd.saveAsTextFile(filePath)示例:
rdd = sc.parallelize([1, 3, 2, 4, 7, 9, 6], 3) rdd.saveAsTextFile("hdfs://10.245.150.47:8020/user/wuhaoyi/output/out1")结果:
保存文件时分布式执行的,不经过driver,所以每一个分区都会产生一个保存文件;
注意一点,保存的文件及其校验文件都保存在一个文件夹内,而这个文件夹不能提前创建好;






分区操作算子
mapPartitions(transformation)
功能:以分区为单位进行map操作
语法:
rdd.mapPartitions(func)示例:
rdd = sc.parallelize([1, 3, 2, 4, 7, 9, 6], 3) def process(iter): result = [] for it in iter: result.append(it * 10) return result print(rdd.mapPartitions(process).collect())结果:
foreachPartition(action)
功能:和foreach类似,一次处理一整个分区的数据;
语法:
rdd.foreachPartition(func)示例:
注意:该方法没有固定的输出顺序,哪一个分区先处理完就先输出
partitionBy(transformation)
功能:对RDD进行自定义分区操作
语法:
rdd.partitionBy(partitionNum,func)参数1:自定义分区个数;参数2:自定义分区规则
示例:
rdd = sc.parallelize([('hadoop', 1), ('spark', 1), ('hello', 1), ('flink', 1), ('hadoop', 1), ('spark', 1)]) # 使用partitionBy 自定义 分区 def process(k): if 'hadoop' == k or 'hello' == k: return 0 if 'spark' == k: return 1 return 2 print(rdd.partitionBy(3, process).glom().collect())结果:
reparation/coalesce
功能:对RDD中的数据进行重新分区
语法:
rdd.reparation(N)/rdd.coalesce(N,是否允许shuffle)在coalesce中,参数2表示是否允许分区,True为允许shuffle,也就可以增加分区,False为不允许shuffle,也就不能增加分区;
在spark中,除了全局排序需要设置为1个分区,其余情况下一般不理会分区相关API
因此不建议通过reparation进行重分区操作;会影响并行计算,如果分区增大还可能导致shuffle
示例:
rdd = sc.parallelize([1, 2, 3, 4, 5], 3) # repartition 修改分区 print(rdd.repartition(1).getNumPartitions()) print(rdd.repartition(5).getNumPartitions()) # coalesce 修改分区(这里因为shuffle为False,所以不能增加分区,但可以减少分区) print(rdd.coalesce(1).getNumPartitions()) print(rdd.coalesce(5, shuffle=True).getNumPartitions())结果:
相比于reparation,一般建议使用coalesce



