Pyspark
注:大家觉得博客好的话,别忘了点赞收藏呀,本人每周都会更新关于人工智能和大数据相关的内容,内容多为原创,Python Java Scala SQL 代码,CV NLP 推荐系统等,Spark Flink Kafka Hbase Hive Flume等等~写的都是纯干货,各种顶会的论文解读,一起进步。
今天继续和大家分享一下Pyspark_SQL1
#博学谷IT学习技术支持
`
文章目录
前言
比起Spark RDD,工作中更常用的是Spark SQL。我平时自己离线任务写的最多的也是Spark SQL,重要程度不言而喻。
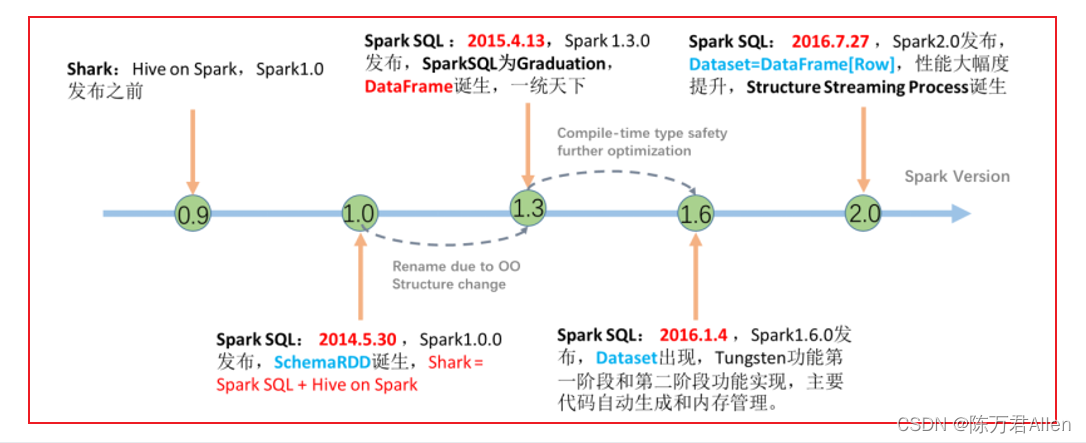
虽然Spark SQL底层也是Spark RDD,但是进行自动优化。效率会较高。官方主推的也是Spark SQL。
一、Spark SQL的数据结构对比

说明:
pandas的df: 二维表, 处理单机化数据
Spark Core:处理任何的数据结构, 处理大规模的分布式数据
Spark SQL: 二维表, 处理大规模的分布式数据
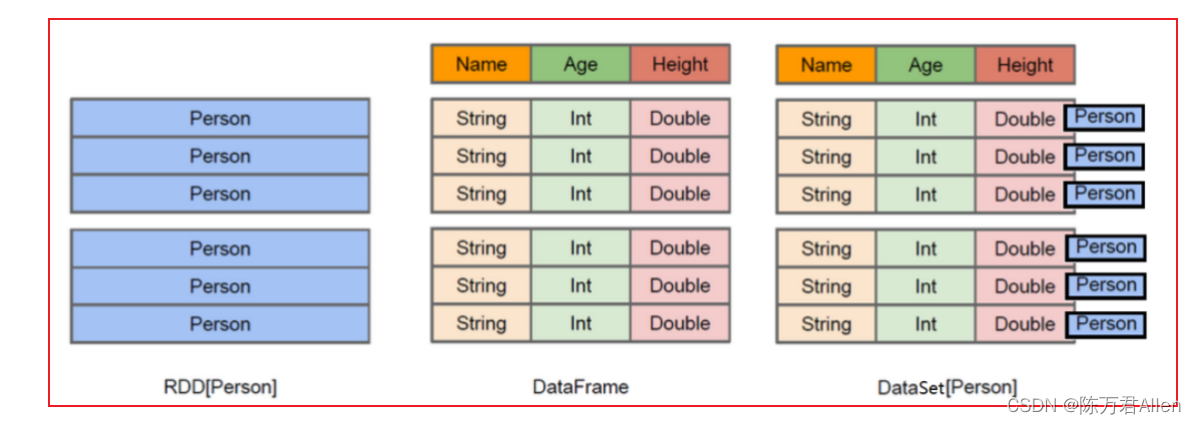
RDD: 存储直接就是对象, 比如在图中, 存储就是一个Person的对象, 但是里面有什么数据靠内心, 不太清楚
DataFrame: 将Person中各个字段的数据, 进行格式化存储,形成一个dataFrame,可以直接看到数据
dataSet: 将Person对象中数据都按照结构化的方式存储好, 同时保留对象的类型,从而知道来源于一个Person的对象
由于Python不支持泛型,所以无法使用DataSet类型, 客户端仅支持dataFrame类型
二、Spark SQL的入门案例
数据集:
1,张三,男,北京
2,李四,女,上海
3,王五,女,北京
4,赵六,男,广州
5,田七,男,北京
6,周八,女,杭州
需求: 有如下结构化数据, 要求查询在北京地区的学员有那些?
from pyspark import SparkContext, SparkConf
import os
from pyspark.sql import SparkSession
if __name__ == '__main__':
print("Spark init")
spark = SparkSession.builder.appName("Spark Sql init").master("local[*]").getOrCreate()
df = spark.read.csv(
path="file:///export/data/workspace/ky06_pyspark/_03_SparkSql/data/a.txt",
header=True,
inferSchema=True,
sep=",",
encoding="UTF-8"
)
df.printSchema()
df.show()
# 方法一
df.createOrReplaceTempView("df_temp")
df_res = spark.sql("""
select * from df_temp where address = '北京'
""")
# 方法二
df_res = df.where("address = '北京'")
df_res.show()
spark.stop()
三、DataFrame详解
3.1 DataFrame基本介绍

一个dataFrame表示是一个二维的表, 一个二维表, 必然存在 行 列 表结构描述信息
表结构描述信息(元数据): StructType
字段: StructField
定义: 字段的名称, 字段的类型, 字段是否可以为Null
认为: 在一个StructType对象下, 由多个StructField组成的, 构建了一个完整的元数据信息
行: Row对象
列: Column对象
注意: dataFrame本质上就是一个RDD, 只是对RDD进行包装, 在其基础上添加schema元数据信息,从而处理结构化数据

3.2 DataFrame的构建方式
方式一: 通过RDD得到一个dataFrame
from pyspark import SparkContext, SparkConf
from pyspark.sql import SparkSession
from pyspark.sql.types import *
if __name__ == '__main__':
print("Spark Rdd Df")
spark = SparkSession.builder.appName("Spark Rdd Df").master("local[*]").getOrCreate()
sc = spark.sparkContext
rdd_init = sc.parallelize(['zhangsan 20', 'lisi 18', 'wangwu 23'])
rdd_map = rdd_init.map(lambda line: (line.split()[0], int(line.split()[1])))
schema = StructType().add("name", StringType(), True).add("age", IntegerType(), True)
# schema = StructType(
# fields=[
# StructField("name", StringType(), True),
# StructField("age", IntegerType(), True)
# ]
# )
df = spark.createDataFrame(data=rdd_map, schema=schema)
df.printSchema()
df.show()
spark.stop()
方式二: 如何将Pandas的DF转换为Spark SQL的DF对象
from pyspark import SparkContext, SparkConf
import os
import pandas as pd
from pyspark.sql import SparkSession
from pyspark.sql.types import *
if __name__ == '__main__':
print("pandas df to Spark df")
spark = SparkSession.builder.appName("pandas df to Spark df").master("local[*]").getOrCreate()
pd_df = pd.DataFrame({
"id": [1, 2, 3, 4],
"name": ["zhangsan", "lisi", "wangwu", "zhaoliu"],
"address": ["beijing", "shanghai", "shenzhen", "guangzhou"]
})
schema = StructType().add("id", IntegerType(), False).add("name", StringType(), False).add("address", StringType(),
False)
spark_df = spark.createDataFrame(data=pd_df, schema=schema)
spark_df.printSchema()
spark_df.show()
spark.stop()
方式三: 内部初始化数据的方式, 来直接得到一个DF对象
from pyspark import SparkContext, SparkConf
from pyspark.sql import SparkSession
from pyspark.sql.types import *
if __name__ == '__main__':
print("create spark df")
spark = SparkSession.builder.appName("create spark df").master("local[*]").getOrCreate()
schema = StructType().add("id", IntegerType(), False).add("name", StringType(), False).add("address", StringType(),
False)
df = spark.createDataFrame(
data=[(1, "zhangsan", "beijing"),
(2, "lisi", "shanghai"),
(3, "wangwu", "guangzhou")],
schema=schema
)
df.printSchema()
df.show()
spark.stop()
方式四: 通过读取外部txt文件的方式, 获取DF对象
from pyspark import SparkContext, SparkConf
from pyspark.sql import SparkSession
from pyspark.sql.types import *
if __name__ == '__main__':
print("read text")
spark = SparkSession.builder.appName("read text").master("local[*]").getOrCreate()
schema = StructType().add("dept", StringType(), False)
df = spark.read \
.format("text") \
.schema(schema=schema) \
.load("file:///export/data/workspace/ky06_pyspark/_03_SparkSql/data/dept.txt")
df.printSchema()
df.show()
spark.stop()
方式五: 通过读取外部csv文件的方式, 获取DF对象
from pyspark import SparkContext, SparkConf
from pyspark.sql import SparkSession
from pyspark.sql.types import *
if __name__ == '__main__':
print("read csv")
spark = SparkSession.builder.appName("read csv").master("local[*]").getOrCreate()
schema = StructType().add("id", IntegerType(), False).add("dept", StringType(), False)
df = spark.read \
.format("csv") \
.option("sep", " ") \
.option("header", True) \
.option("encoding", "utf-8") \
.schema(schema=schema) \
.load("file:///export/data/workspace/ky06_pyspark/_03_SparkSql/data/dept.txt")
df.printSchema()
df.show()
spark.stop()
方式六: 通过读取外部json文件的方式, 获取DF对象
from pyspark import SparkContext, SparkConf
from pyspark.sql import SparkSession
from pyspark.sql.types import *
if __name__ == '__main__':
print("read json")
spark = SparkSession.builder.appName("read json").master("local[*]").getOrCreate()
schema = StructType().add("id", IntegerType(), False).add("name", StringType(), False) \
.add("age", IntegerType(), False).add("address", StringType(), True)
df = spark.read \
.format("json") \
.schema(schema=schema) \
.load("file:///export/data/workspace/ky06_pyspark/_03_SparkSql/data/stu.json")
df.printSchema()
df.show()
spark.stop()
总结
今天主要和大家分享了Pyspark_SQL基础概念和入门案例。