Pyspark
注:大家觉得博客好的话,别忘了点赞收藏呀,本人每周都会更新关于人工智能和大数据相关的内容,内容多为原创,Python Java Scala SQL 代码,CV NLP 推荐系统等,Spark Flink Kafka Hbase Hive Flume等等~写的都是纯干货,各种顶会的论文解读,一起进步。
今天继续和大家分享一下Pyspark_SQL2
#博学谷IT学习技术支持
前言
今天继续分享Pyspark_SQL2。
一、Spark SQL的shuffle分区设置
Spark SQL底层本质上还是Spark的RDD程序, 认为Spark Sql组件就是一款翻译软件,用于将SQL/DSL翻译为Spark RDD程序, 执行运行
Spark SQL中同样也是存在shuffle分区的, 在执行shuffle分区后, shuffle分区数量默认为200个, 但是实际中, 一般都是需要调整这个分区的,因为当数据量比较少的时候, 200个分区相对比较大, 但是当数据量比较大的时候, 200个分区显得比较小。
如何调整shuffle分区数量呢? spark.sql.shuffle.partitions
方案一: 直接修改spark-defaults.conf 配置文件 全局设置 默认值为200 不建议修改
设置为 :
spark.sql.shuffle.partition 100
方案二: 在客户端通过spark-submit 命令提交的时候, 动态设置shuffle的分区数量: 比较常用(部署 上线,基于spark-submit提交运行的时候)
设置为:
–conf ‘spark.sql.shuffle.partitions=100’
方案三: 直接在代码中设置 : 主要在测试 开发环境中使用, 直接右键运行 但是一般在上线部署的时候, 会将其删除, 统一在spark-submit中配置 优先级最高
设置为:
sparkSession.conf.set(‘spark.sql.shuffle.partitions’,100)
或者:
sparkSession.builder.appName().master()
.config(‘spark.sql.shuffle.partitions’,4).getOrCreate()
二、Spark SQL的数据写出操作
演示1: 输出到文件中 json csv orc text ….
from pyspark import SparkContext, SparkConf
from pyspark.sql import SparkSession
from pyspark.sql.types import *
if __name__ == '__main__':
print("write data")
spark = SparkSession.builder.appName("write data").master("local[*]") \
.config('spark.sql.shuffle.partitions', 100) \
.getOrCreate()
schema = StructType().add("id", IntegerType()).add("name", StringType()) \
.add("age", IntegerType())
df = spark.createDataFrame(data=[
(1, "zhangsan", 20),
(2, "lisi", 21),
(3, "wangwu", 22),
(4, "zhaoliu", 23),
(5, "tianqi", 19)
], schema=schema)
df = df.where("age > 20")
# append overwrite ignore error
df.write.mode("overwrite").format("csv") \
.option("header", True) \
.save("file:///export/data/workspace/ky06_pyspark/_03_SparkSql/data/output1.csv")
spark.stop()
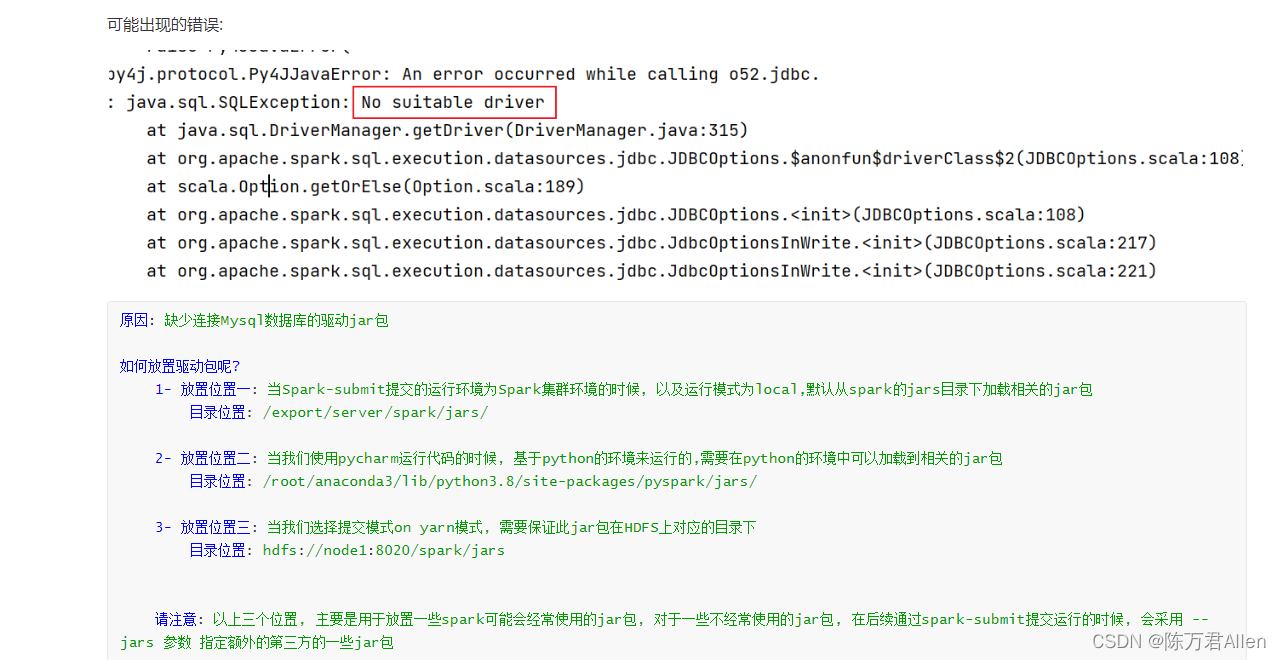
将结果数据基于JDBC方案, 输出到关系型数据库, 例如说: MySQL
from pyspark import SparkContext, SparkConf
from pyspark.sql import SparkSession
from pyspark.sql.types import *
import pyspark.sql.functions as F
if __name__ == '__main__':
print("write data jdbc")
spark = SparkSession.builder.appName("write data jdbc").master("local[*]") \
.config('spark.sql.shuffle.partitions', 100) \
.getOrCreate()
schema = StructType().add("id", IntegerType()).add("name", StringType()) \
.add("age", IntegerType())
df = spark.createDataFrame(data=[
(1, "zhangsan", 20),
(2, "lisi", 21),
(3, "wangwu", 22),
(4, "zhaoliu", 23),
(5, "tianqi", 19)
], schema=schema)
df = df.where("age > 20")
# append overwrite ignore error
df.write.jdbc(url="jdbc:mysql://node1:3306/day10_pyspark",
table="stu",
mode="append",
properties={
"user": "root", "password": "xxx"})
spark.stop()
三、WordCount案例实现
words.txt文件的内容:
hadoop hive hive hadoop sqoop
sqoop kafka hadoop sqoop hive hive
hadoop hadoop hive sqoop kafka kafka
kafka hue kafka hbase hue hadoop hadoop hive
sqoop sqoop kafka hue hue kafka
方法1:
from pyspark import SparkContext, SparkConf
from pyspark.sql import SparkSession
from pyspark.sql.types import *
import pyspark.sql.functions as F
if __name__ == '__main__':
print("word count")
spark = SparkSession.builder.appName("word count").master("local[*]").getOrCreate()
sc = spark.sparkContext
rdd_init = sc.textFile(name="file:///export/data/workspace/ky06_pyspark/_03_SparkSql/data/word.txt")
rdd_data = rdd_init.flatMap(lambda line: line.split()).map(lambda word: (word,))
schema = StructType().add("word", StringType(), True)
df = spark.createDataFrame(rdd_data, schema=schema)
# df.createTempView("word_table")
# df_res = spark.sql("""
# select *, count(word) as count_num
# from word_table
# group by word
# """)
#
df.printSchema()
df.show()
df_res = df.groupBy("word").count()
df_res.show()
spark.stop()
方法2:
from pyspark import SparkContext, SparkConf
from pyspark.sql import SparkSession
from pyspark.sql.types import *
import pyspark.sql.functions as F
if __name__ == '__main__':
print("word count")
spark = SparkSession.builder.appName("word count").master("local[*]").getOrCreate()
schema = StructType().add("line", StringType(), True)
df = spark.read \
.format("text") \
.schema(schema=schema) \
.load("file:///export/data/workspace/ky06_pyspark/_03_SparkSql/data/word.txt")
# df.createTempView("t1")
# spark.sql("""
# select
# words,
# count(1) as word_cnt
# from t1 lateral view explode(split(line," ")) as words
# group by words
# """).show()
df.select(F.explode(F.split("line", " ")).alias("words")).groupBy("words").agg(
F.count("words").alias("word_cnt")
).show()
spark.stop()
总结
今天主要和大家分享了Pyspark_SQL的shuffle分区设置,写出,和word count案例。