Pyspark
注:大家觉得博客好的话,别忘了点赞收藏呀,本人每周都会更新关于人工智能和大数据相关的内容,内容多为原创,Python Java Scala SQL 代码,CV NLP 推荐系统等,Spark Flink Kafka Hbase Hive Flume等等~写的都是纯干货,各种顶会的论文解读,一起进步。
今天继续和大家分享一下Pyspark_SQL4
#博学谷IT学习技术支持
文章目录
前言
今天继续分享Pyspark_SQL4。
一、使用窗口函数
窗口函数格式:
分析函数 over(partition by xxx order by xxx [asc|desc] [rows between xxx and xxx])
学习的相关分析函数有那些?
第一类: row_number() rank() dense_rank() ntile()
第二类: 和聚合函数组合使用 sum() avg() max() min() count()
第三类: lag() lead() first_value() last_value()
数据:
cookieid,datestr,pv
cookie1,2023-01-18,50
cookie1,2023-01-19,55
cookie1,2023-01-20,58
cookie1,2023-01-21,49
cookie1,2023-01-22,48
cookie2,2023-01-18,50
cookie2,2023-01-19,47
cookie2,2023-01-20,52
需求:统计每个cookie中,pv数量排名前3
from pyspark import SparkContext, SparkConf
from pyspark.sql import SparkSession
from pyspark.sql.types import *
import pyspark.sql.functions as F
from pyspark.sql import Window as win
if __name__ == '__main__':
print("window function")
spark = SparkSession.builder.appName("window function").master("local[*]") \
.config('spark.sql.shuffle.partitions', 200) \
.getOrCreate()
schema = StructType().add("cookieid", StringType()).add("datestr", StringType()) \
.add("pv", IntegerType())
df = spark.read \
.format("csv") \
.option("sep", ",") \
.option("header", True) \
.schema(schema=schema) \
.load("file:///export/data/workspace/ky06_pyspark/_03_SparkSql/data/pv.csv")
# df.printSchema()
# df.show()
# 需求:统计每个cookie中,pv数量排名前3
# df.createTempView("t1")
# spark.sql("""
# with t2 as(
# select *,
# row_number() over(partition by cookieid order by pv) as rank1
# from t1
# )select * from t2 where rank1<3
# """).show()
df.select(
"*",
F.row_number().over(win.partitionBy("cookieid").orderBy(F.desc("pv"))).alias("rank2")
).where("rank2<3").show()
spark.stop()
二、自定义UDF函数
需求:自定义一个函数, 完成对数据统一添加一个后缀名的操作
from pyspark import SparkContext, SparkConf
from pyspark.sql import SparkSession
from pyspark.sql.types import *
import pyspark.sql.functions as F
from pyspark.sql import Window as win
if __name__ == '__main__':
print("spark udf")
spark = SparkSession.builder.appName("spark udf").master("local[*]") \
.config('spark.sql.shuffle.partitions', 200) \
.getOrCreate()
schema = StructType().add("id", IntegerType()).add("name", StringType()) \
.add("address", StringType())
df = spark.createDataFrame([
(1, "zhangsan", "beijing"),
(2, "lisi", "shanghai"),
(3, "wangwu", "guangzhou"),
(4, "zhaoliu", "shenzhen"),
], schema=schema)
df.createTempView("t1")
@F.udf(returnType=StringType())
def add_post(data):
return data + "boxuegu"
spark.udf.register("add_post_sql", add_post)
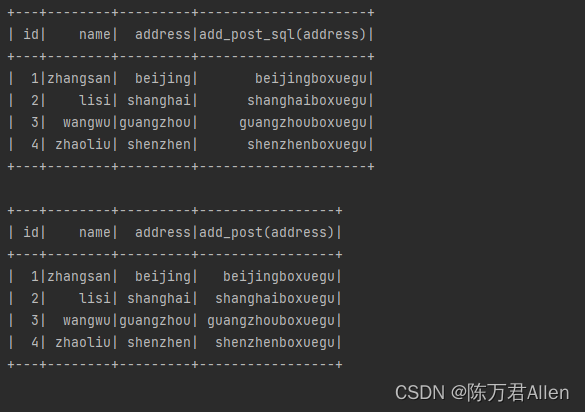
spark.sql("""
select
*,
add_post_sql(address)
from t1
""").show()
df.select(
"*",
add_post("address")
).show()
spark.stop()
需求2:自定义一个函数, 让其返回值的类型为字典 列表 元组
from pyspark import SparkContext, SparkConf
from pyspark.sql import SparkSession
from pyspark.sql.types import *
import pyspark.sql.functions as F
import os
# 锁定远端环境, 确保环境统一
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
if __name__ == '__main__':
print("演示原生的自定义函数:")
# 1- 创建SparkSession对象
spark = SparkSession.builder.appName('df_write').master('local[*]').getOrCreate()
# 2- 初始化一些数据
df = spark.createDataFrame(
data=[(1, '张三 北京'), (2, '李四 上海'), (3, '王五 广州'), (4, '赵六 深圳'), (5, '田七 杭州')],
schema='id int,name_address string'
)
df.show()
df.createTempView('t1')
# 3- 执行相关的操作:
# 需求: 自定义一个函数, 将姓名和地址拆分开
schema = StructType().add('name', StringType()).add('address', StringType())
@F.udf(returnType=schema)
def split_data(data):
res = data.split(' ')
# return [res[0],res[1]]
# return (res[0], res[1])
return {
'name': res[0], 'address': res[1]}
# 使用字典返回, key值 必须和schema中定义字段名称保持一致
# 注册函数
spark.udf.register('split_data', split_data)
# 使用函数
# SQL
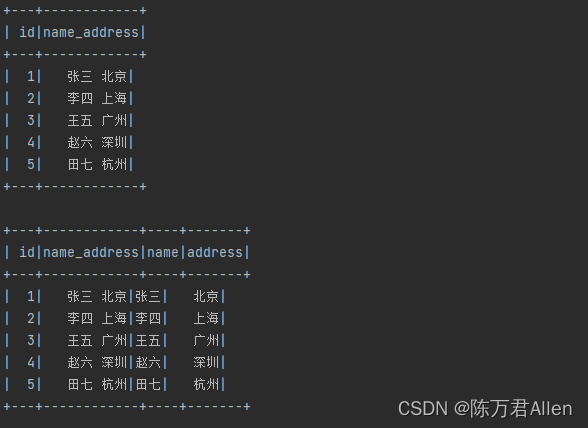
df1 = spark.sql("""
select
*,
split_data(name_address)['name'] as name,
split_data(name_address)['address'] as address
from t1
""")
df1.show()
# DSL
df.select(
'*',
split_data('name_address')['name'].alias('name'),
split_data('name_address')['address'].alias('address')
).show()
总结
今天主要和大家分享了Pyspark_SQL的窗口函数使用方式和自定义UDF函数。