Spark:https://spark.apache.org/
PySpark官方文档:http://spark.apache.org/docs/latest/api/python/pyspark.html
1.PySpark简介
1.1 Spark - 概述
Apache Spark是一个闪电般快速的实时处理框架。它可以使用内存计算以实时分析数据。由于Apache Hadoop MapReduce仅执行批处理并且缺乏实时处理功能,所以才有了Apache Spark,因为它可以实时执行流处理,也可以处理批处理。除了实时和批处理之外,Apache Spark还支持交互式查询和迭代算法。Apache Spark有自己的集群管理器,可以托管其应用程序。它利用Apache Hadoop进行存储和处理。它使用HDFS(Hadoop分布式文件系统)进行存储,也可以在YARN上运行Spark应用程序。
1.2 PySpark - 概述
Apache Spark是用Scala编写的。 Apache Spark社区发布了一个工具PySpark,可以使用用Spark支持Python。 PySpark可以使用Python语言操作RDD。 正是由于一个名为Py4j的库,他们才能实现这一目标。PySpark提供了PySpark Shell,它将Python API链接到spark核心并初始化SparkContext。
2.PySpark SparkContext
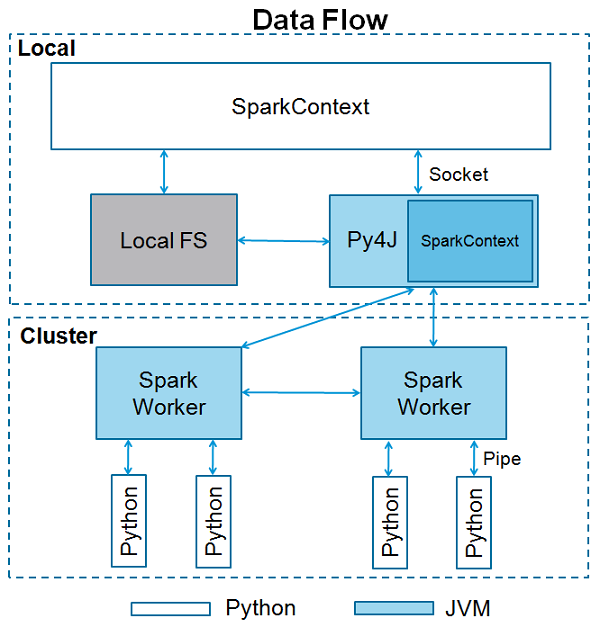
SparkContext是任何spark功能的入口点。当我们运行任何Spark应用程序时,启动一个具有main函数的驱动程序,并在此处初始化SparkContext。然后,驱动程序在工作节点上的执行程序内运行操作。
SparkContext使用Py4J启动JVM并创建JavaSparkContext。默认情况下,PySpark将SparkContext写作'sc'。
以下代码块包含PySpark类的详细信息以及SparkContext的参数。
class pyspark.SparkContext (
master = None,
appName = None,
sparkHome = None,
pyFiles = None,
environment = None,
batchSize = 0,
serializer = PickleSerializer(),
conf = None,
gateway = None,
jsc = None,
profiler_cls = <class 'pyspark.profiler.BasicProfiler'>
)
参数
以下是SparkContext的参数。
-
Master - 它是连接到的集群的URL。
-
appName - 工作名称。
-
sparkHome - Spark安装目录。
-
pyFiles - 要发送到集群并添加到PYTHONPATH的.zip或.py文件。
-
environment - 工作节点环境变量。
-
batchSize - 表示为单个Java对象的Python对象的数量。设置1以禁用批处理,设置0以根据对象大小自动选择批处理大小,或设置为-1以使用无限批处理大小。
-
serializer - RDD序列化器。
-
conf - L {SparkConf}的一个对象,用于设置所有Spark属性。
-
gateway- 使用现有网关和JVM,否则初始化新JVM。
-
JSC - JavaSparkContext实例。
-
profiler_cls - 用于进行性能分析的一类自定义Profiler(默认为pyspark.profiler.BasicProfiler)。
在上述参数中,主要使用master和appname。PySpark程序的前两行如下所示 -
from pyspark import SparkContext
sc = SparkContext("local", "First App")
2.1 SparkContext示例 - PySpark Shell
在此示例中,我们将计算README.md文件中带有字符“a”或“b”的行数。比如一个文件中有5行,3行有'a'字符,那么输出将是→ Line with a:3。字符'b'也是如此。
注 - 我们不会在以下示例中创建任何SparkContext对象,因为默认情况下,当PySpark shell启动时,Spark会自动创建名为sc的SparkContext对象。如果尝试创建另一个SparkContext对象,将收到以下错误 - “ValueError:无法一次运行多个SparkContexts”。
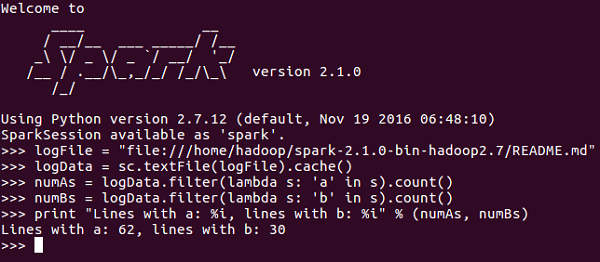
<<< logFile = "file:///home/hadoop/spark-2.1.0-bin-hadoop2.7/README.md"
<<< logData = sc.textFile(logFile).cache()
<<< numAs = logData.filter(lambda s: 'a' in s).count()
<<< numBs = logData.filter(lambda s: 'b' in s).count()
<<< print("Lines with a: %i, lines with b: %i" % (numAs, numBs))
Lines with a: 62, lines with b: 30
2.2SparkContext示例 - Python程序
让我们使用Python程序运行相同的示例。创建一个名为firstapp.py的Python文件,并在该文件中输入以下代码。
----------------------------------------firstapp.py---------------------------------------
from pyspark import SparkContext
logFile = "file:///home/hadoop/spark-2.1.0-bin-hadoop2.7/README.md"
sc = SparkContext("local", "first app")
logData = sc.textFile(logFile).cache()
numAs = logData.filter(lambda s: 'a' in s).count()
numBs = logData.filter(lambda s: 'b' in s).count()
print("Lines with a: %i, lines with b: %i" % (numAs, numBs))
----------------------------------------firstapp.py---------------------------------------
然后我们将在终端中执行以下命令来运行此Python文件。我们将得到与上面相同的输出。
$SPARK_HOME/bin/spark-submit firstapp.py
Output: Lines with a: 62, lines with b: 30