这段时间在用 scrapy 爬取大众点评美食店铺的信息,由于准备爬取该网站上全国各个城市的信息,单机跑效率肯定是跟不上的,所以只能借助于分布式。scrapy 学习自崔庆才老师的视频,受益颇多,代码简练易懂,风格清新。这里梳理一遍从刚申请的服务器环境配置,python 安装,到搭建能运行分布式爬虫的整个流程。
服务器我是申请的阿里云的学生机,腾讯云和美团云也申请了,相比起来还是阿里云用起来舒服,腾讯云使用体验最差。我装的是 centos 系统,以下也是 centos 下遇到的问题及解决问题的找过的链接。另外阿里云需要添加安全组规则,将后面会用到的端口放行,例如27017,6800等。
从机配置
1.python 的安装
在装过好几台服务器后总结出了最短且有效的装 python 的方法,参考了这篇文章这里简要总结一下
yum -y install zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-develreadline-devel tk-devel gdbm-devel db4-devel libpcap-devel xz-develwget https://www.python.org/ftp/python/3.6.3/Python-3.6.3.tgzmkdir /usr/local/python3tar -zxvf Python-3.6.3.tgzcd Python-3.6.3./configure --prefix=/usr/local/python3make && make installln -s /usr/local/python3/bin/python3 /usr/bin/python3创建 python3 的软链接ln -s /usr/local/python3/bin/pip3 /usr/bin/pip3创建 pip3 的软链接- 最后命令行下输入
pip3和python3 -V验证一下是否都成功
2.mongodb的安装
在从机上都装上 mongodb,爬取的数据都存在各自的服务器上,之后再汇总。这里参考了这篇文章
vim /etc/yum.repos.d/mongodb-org-3.4.repo[mongodb-org-3.4]
name=MongoDB Repository
baseurl=https://repo.mongodb.org/yum/redhat/$releasever/mongodb-org/3.4/x86_64/
gpgcheck=1
enabled=1
gpgkey=https://www.mongodb.org/static/pgp/server-3.4.asc
将以上内容复制粘贴进去刚打开的窗口yum -y install mongodb-orgsystemctl enable mongod.service设置开机启动vim /etc/mongod.conf编辑配置文件,注释掉 bindIp,并重启 mongodbsystemctl restart mongod.service重启 mongodb,这条指令在 mongodb 挂掉时候可以使用systemctl stop mongod.service停止 mongodb
记录一下刚学习时命令行下的编辑操作,vim 打开文件后,insert 进行编辑,退出编辑 esc,shift+两下Z。查找关键词是:/+关键词
3.利用 pip3 安装 scrapy 等
一般正常顺序先pip3 install scrapy,接着肯定会报requirement Twisted>=13.1.0这种错误,一次偶然我先pip3 install scrapyd发现安装上了最新的 Twisted 组件,接着安装 scrapy也没再报错。所以为了省事,避开报错,建议先安装 scrapyd。
pip3 install scrapydpip3 install scrapypip3 install pymongopip3 install redispip3 install redis-client
安装完以上内容,基本能满足分布式从机的爬取。但是在命令行直接输入scrapy 和 scrapyd 发现会报错,提示command not found,这里可以通过创建软链接解决问题。
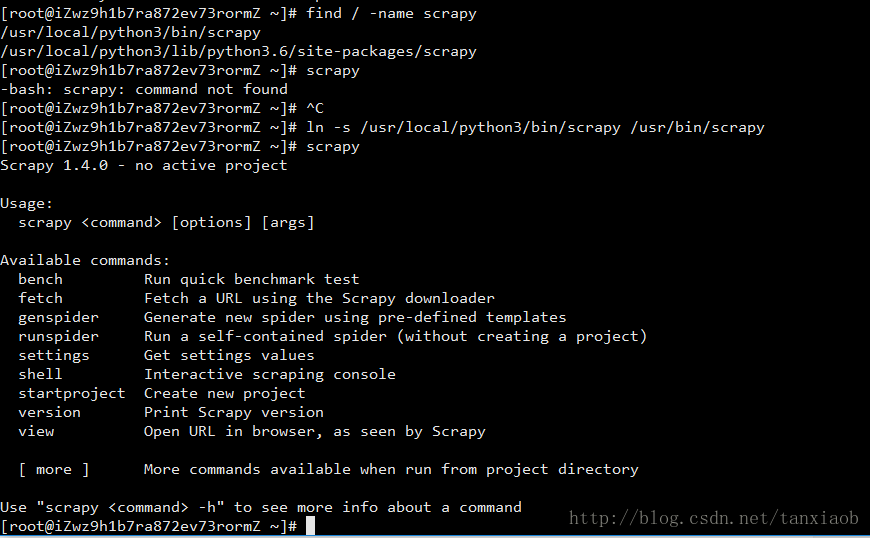
find / -name scrapy找到系统中scrapy所在的目录,选择在bin目录下的路径ln -s /usr/local/python3/bin/scrapy /usr/bin/scrapy这是在我的路径下创建的软链接scrapy命令行再输入scrapy发现已经可用
scrapyd 创建软链接的方法与上面一样,其实在后面加个d就好了(笑)
scrapy 创建软链接如下
scrapyd 创建软链接如下
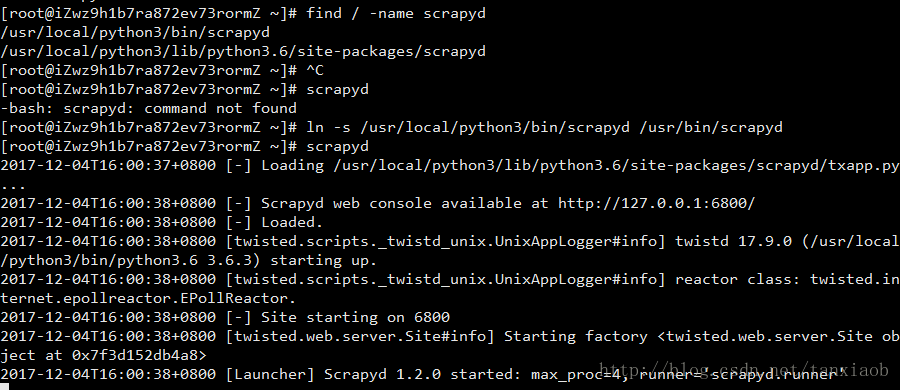
在开启了 scrapyd 服务后发现监听 ip 为本机,想要远程访问需要将配置修改一下。先 ctrl+c 退出 scrapyd,打开 scrapyd 配置文件所在的文件夹
cd /usr/local/python3/lib/python3.6/site-packages/scrapydls列出 scrapyd 文件夹下所有文件vim default_scrapyd.conf打开配置文件bind_address = 0.0.0.0将绑定 ip 修改为 0.0.0.0,保存退出,再在命令行输入scrapyd会发现监听 ip 发生了变化。
由于从机的scrapyd需要后台运行,这里我采用了setsid scrapyd命令来后台开启服务,这样关闭窗口后仍能进行连接。
需要结束scrapyd进程时,利用ps -ef | grep -i scrapyd查看PID号,再 kill -9 PID 结束进程。
主机配置
以上完成了从机的配置,接下里配置主机
主机和从机不同在于它需要提供 redis 服务来保存请求队列,所以主要是安装 redis 服务。参考了众多文章后,还是推荐这篇文章
这里梳理一下过程:
yum install gccwget http://download.redis.io/releases/redis-3.0.6.tar.gztar zxvf redis-3.0.6.tar.gzcd redis-3.0.6建议将文件夹名字修改为redis看着简洁一些vim redis.conf打开 redis 配置文件#bind 127.0.0.1将绑定 ip 注释掉,以便远程访问daemonize yes在 redis.conf 中修改该选项为 yes,即后台运行requirepass后加上登陆密码protected-mode no关闭保护模式,接着保存退出mkdir /etc/redis将 redis.conf 复制一份名为 6379.conf 到指定目录
cp redis.conf /etc/redis/6379.confcd utils在原redis目录下打开utils文件夹vim redis_init_script修改启动脚本,并在开头添加如下代码#!/bin/sh
#chkconfig: 2345 90 10
#description: Redis is a persistent key-value databasecp redis_init_script /etc/init.d/redisd将启动脚本复制为 redischkconfig redisd on设置开机启动service redisd start启动 redisservice redisd stop关闭 redis
遇到过的问题
以上内容完成了主机上 redis 服务的搭建,不过在使用过程中,遇到了以下报错, MISCONF Redis is configured to save RDB snapshots, but is currently not able to persist on disk.Commands that may modify the data set are disabled. Please check Redis logs for details about the error.
原因是强制关闭 Redis 快照导致不能持久化,我采取了下面解决方法
redis-cli -a 密码 进入 redis 客户端,-a 后接之前配置文件中修改的密码 127.0.0.1:6379> config set stop-writes-on-bgsave-error no 提示 ok 就可以了
通过主机与从机的搭建,分布式运行的条件有了,本地需要pip install scrapyd-client 安装 scrapyd 的客户端插件,另外由于我用的是 windows 系统,curl 命令需要再去下载,scrapyd-deploy 也是无法直接使用的,后来在 github 上找到了解决办法
- 打开本地
Python\Python36\Scripts目录 - 创建名为
scrapyd-deploy.bat的文件 - 写入
"Python\Python36\python.exe" "Python\Python36\Scripts\scrapyd-deploy" %1 %2 %3 %4 %5 %6 %7 %8
%9
这样就可以是使用 scrapyd-deploy 了,具体使用请阅读官方文档 scrapyd scrapyd-client

END