零、写在前面
服务器:centos7.6 jdk1.8 hadoop2.7
这个其实没有什么影响,都可以参照这个教程进行搭建
一、防火墙设置
停止防火墙
systemctl stop firewalld.service
禁止防火墙开机自启动
systemctl disable firewalld.service
二、修改主机名
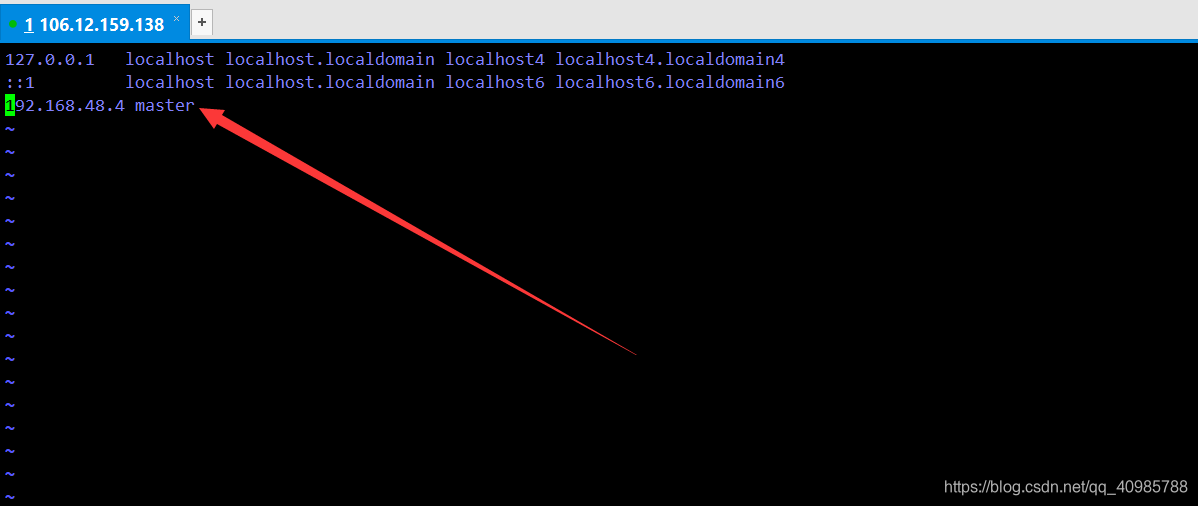
我将我的主机名修改为master

reboot重启服务器生效
三、修改hosts配置文件
vim /etc/hostname
四、安装ssh
(1)询问时输入y
yum install openssh-clients openssh-server
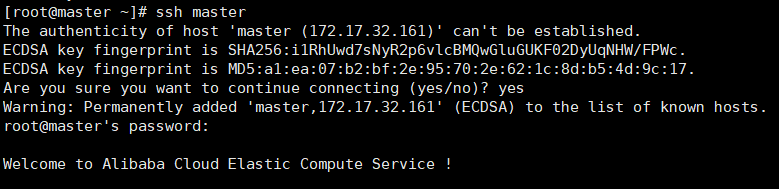
(2)测试ssh是否安装完成
ssh master
(3) 配置SSH免key登陆**(必须要配置)**
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
(4) 用ssh连接主机,此时不需要密码

五、安装jdk并配置java环境
最好使用安装包的形式安装,在线下载的速度很慢,不建议使用。
我这里安装的是jdk1.8
这里具体的流程就直接跳过了

六、安装hadoop并配置环境
(1)、下载安装包
同样的不要选择在线安装。下载安装包再上传到服务器上进行安装。
下面是hsdoop的镜像地址,我下载的是hsdoop2.7版本。
http://apache.claz.org/hadoop/common/
然后进入到相应的目录进行解压
(2)、查看是否安装成功

(3)、修改配置文件,设置环境变量
vim ~/.bashrc
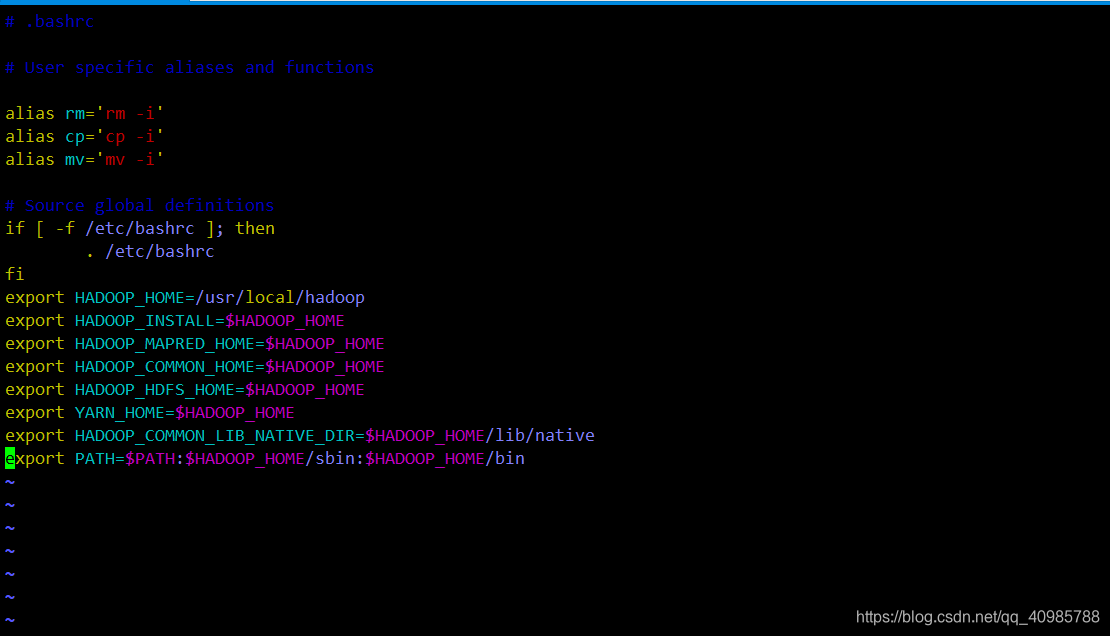
然后在添加下面,注意修改HADOOP_HOME
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
使配置文件生效 source ~/.bashrc
(4)、然后 vim /etc/profile

结尾添加 (同样的要注意hadoop的路径)
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_COMMON_LIB_NATIVE_DIR"
(5)、修改hadoop-env.sh
vim /usr/local/hadoop/etc/hadoop/hadoop-env.sh
修改 export JAVA_HOME的路径
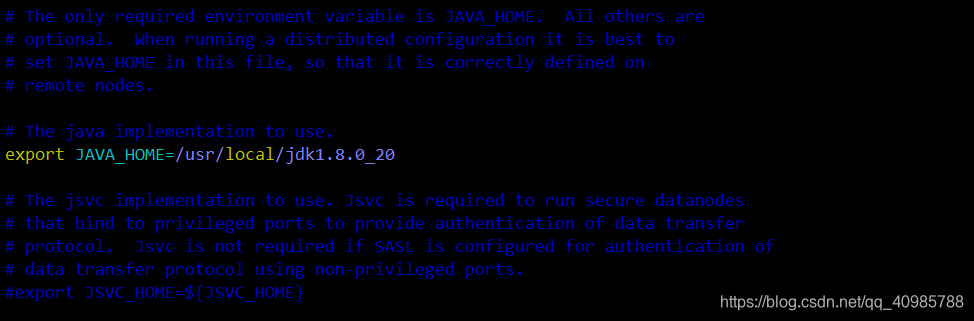
然后再在结尾添加
export HADOOP_HOME=/usr/local/hadoop/
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_COMMON_LIB_NATIVE_DIR"

(6)、修改core-site.xml
vim /usr/local/hadoop/etc/hadoop/core-site.xml
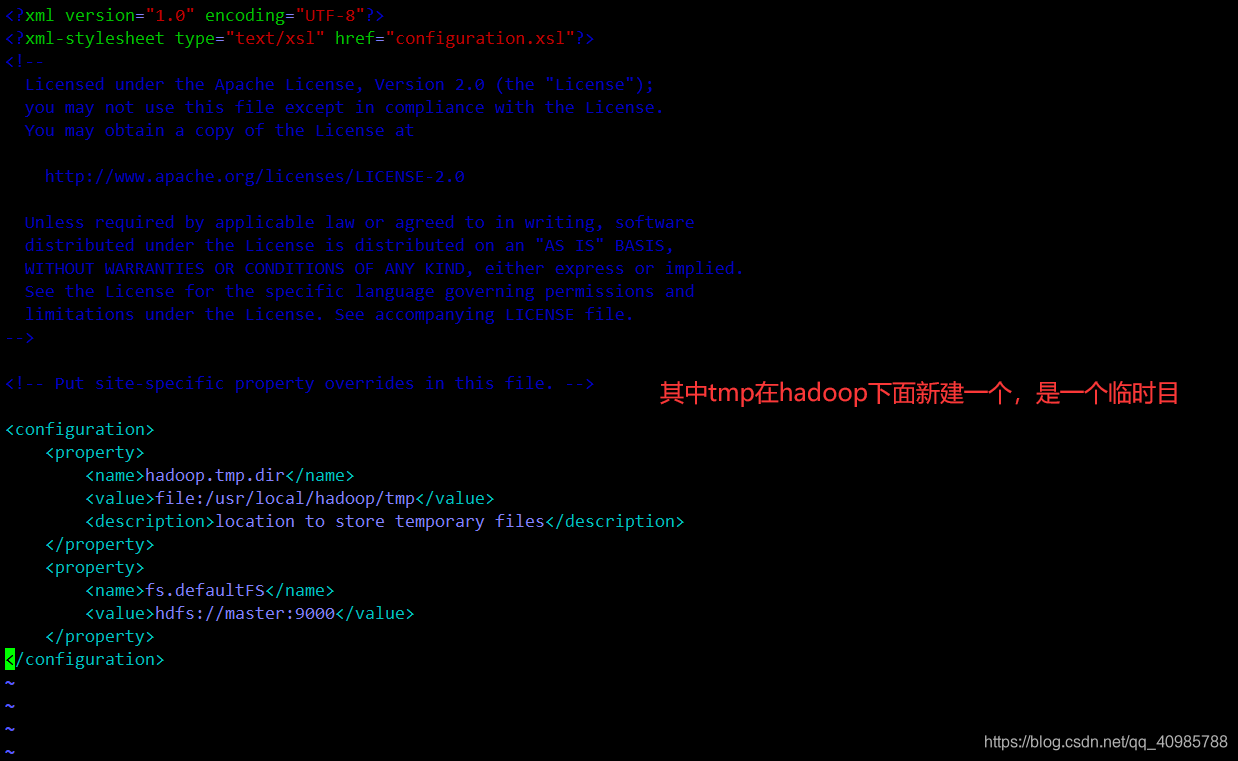
修改为如下内容:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>location to store temporary files</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
(7)、修改hdfs-site.xml
vim /usr/local/hadoop/etc/hadoop/hdfs-site.xml
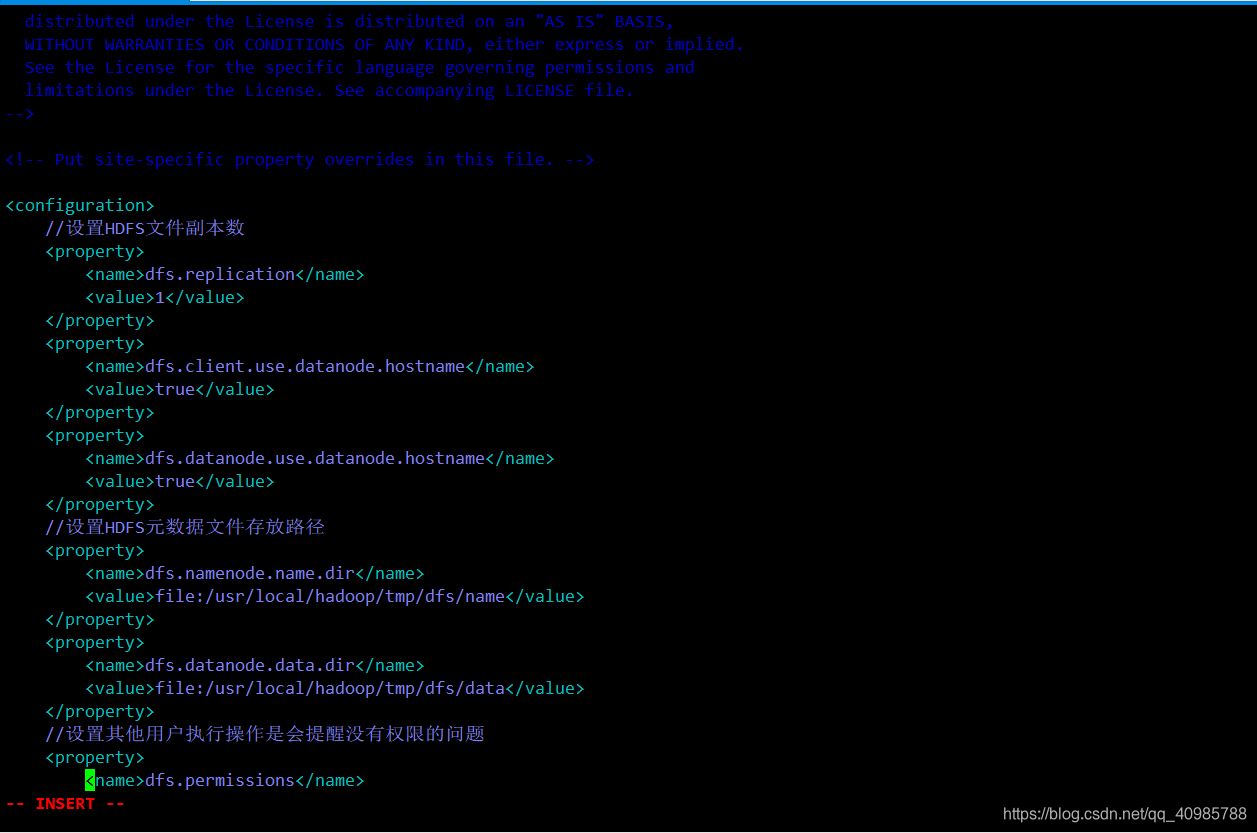
修改为如下内容
<configuration>
//设置HDFS文件副本数
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.client.use.datanode.hostname</name>
<value>true</value>
</property>
<property>
<name>dfs.datanode.use.datanode.hostname</name>
<value>true</value>
</property>
//设置HDFS元数据文件存放路径
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/hadoop-2.7.5/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/hadoop-2.7.5/tmp/dfs/data</value>
</property>
//设置其他用户执行操作是会提醒没有权限的问题
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
(8)、修改mapred-site.xml
将/usr/local/hadoop/etc/hadoop/mapred-site.xml.template的后缀.template去掉。然后
vim /usr/local/hadoop/etc/hadoop/mapred-site.xml
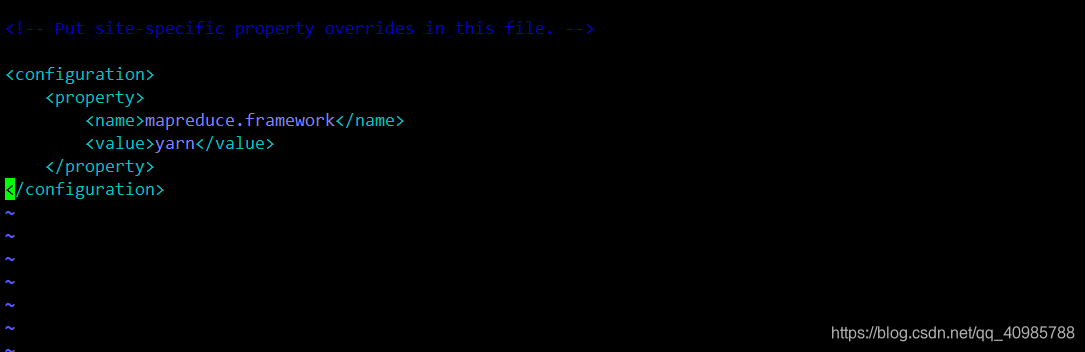
添加如下内容:
<configuration>
<property>
<name>mapreduce.framework</name>
<value>yarn</value>
</property>
</configuration>
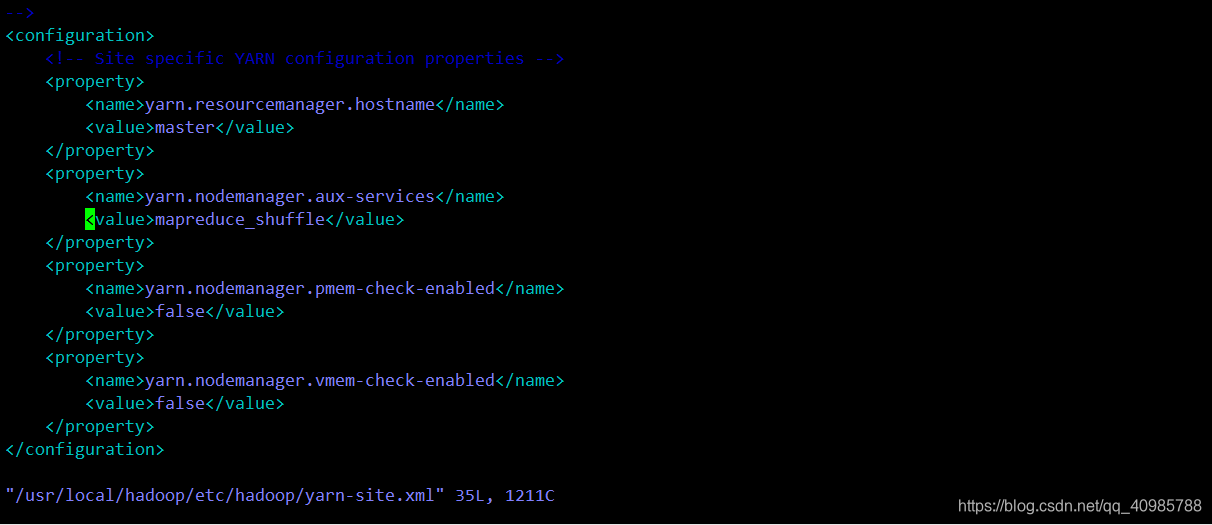
(9)、修改yarn-site.xml
vim /usr/local/hadoop/etc/hadoop/yarn-site.xml
修改为如下内容:
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
(10)、修改slaves文件
将localhost直接改成主机名(这里为master),如果有多个结点就每行一个。
 (11)、格式化NameNode
(11)、格式化NameNode
注意:
只能格式化一次,如果之后想格式化就必须先清除/usr/local/hadoop/tmp
然后进入到bin目录下面执行格式化操作
/usr/local/hadoop/bin/hdfs namenode -format
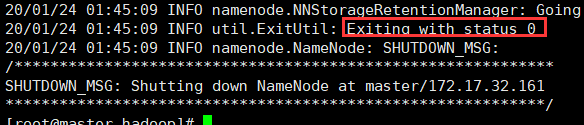
返回0即表示成功!
(12)、启动hadoop
进去到sbin下面进行启动
/usr/local/hadoop/sbin/start-all.sh
第一次启动可能有错误,但是没有关系的,多启动几次就好了,然后输入yes,之后启动就不会有什么错误了。
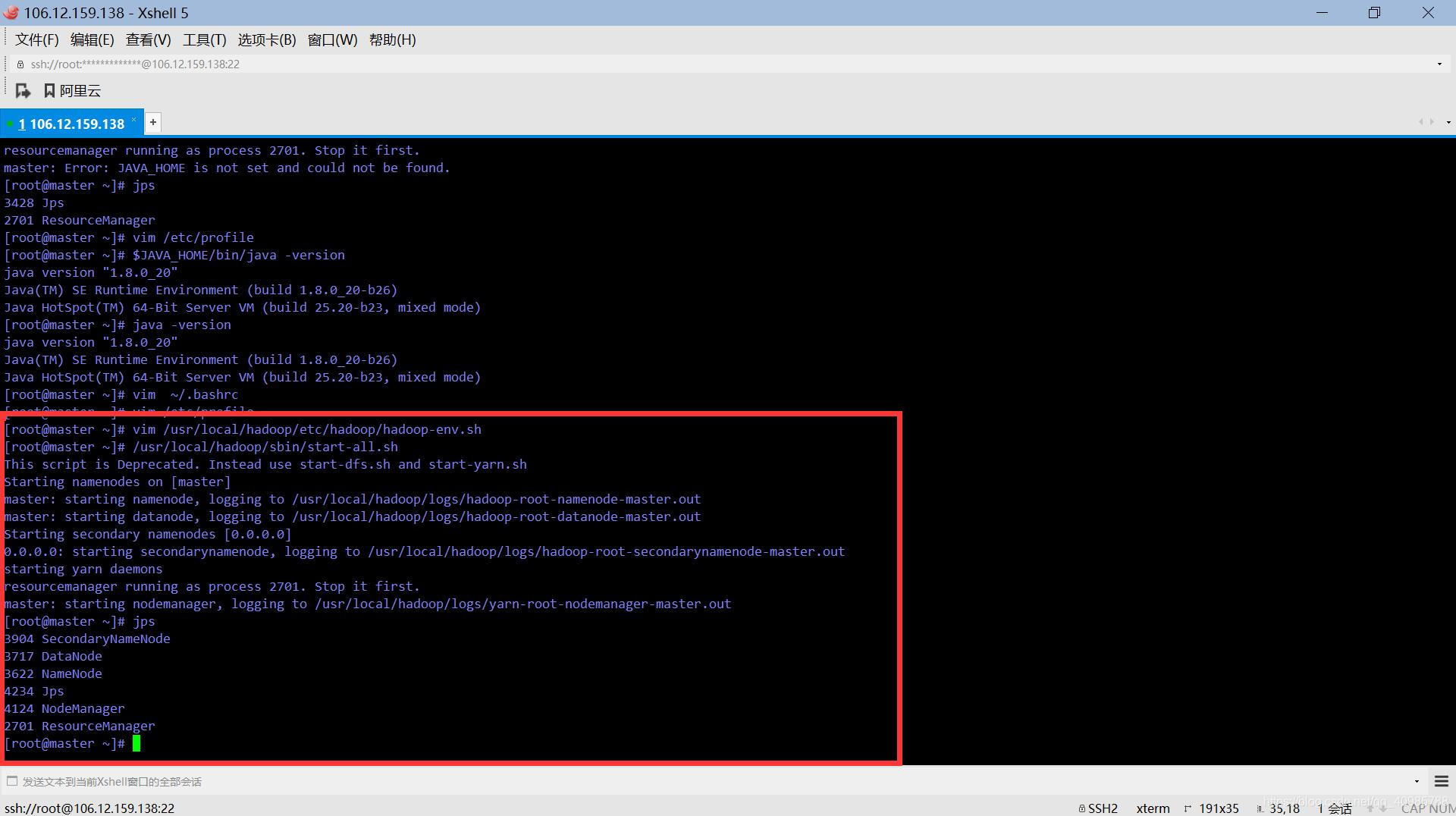
输入jps就可以查看进程状态

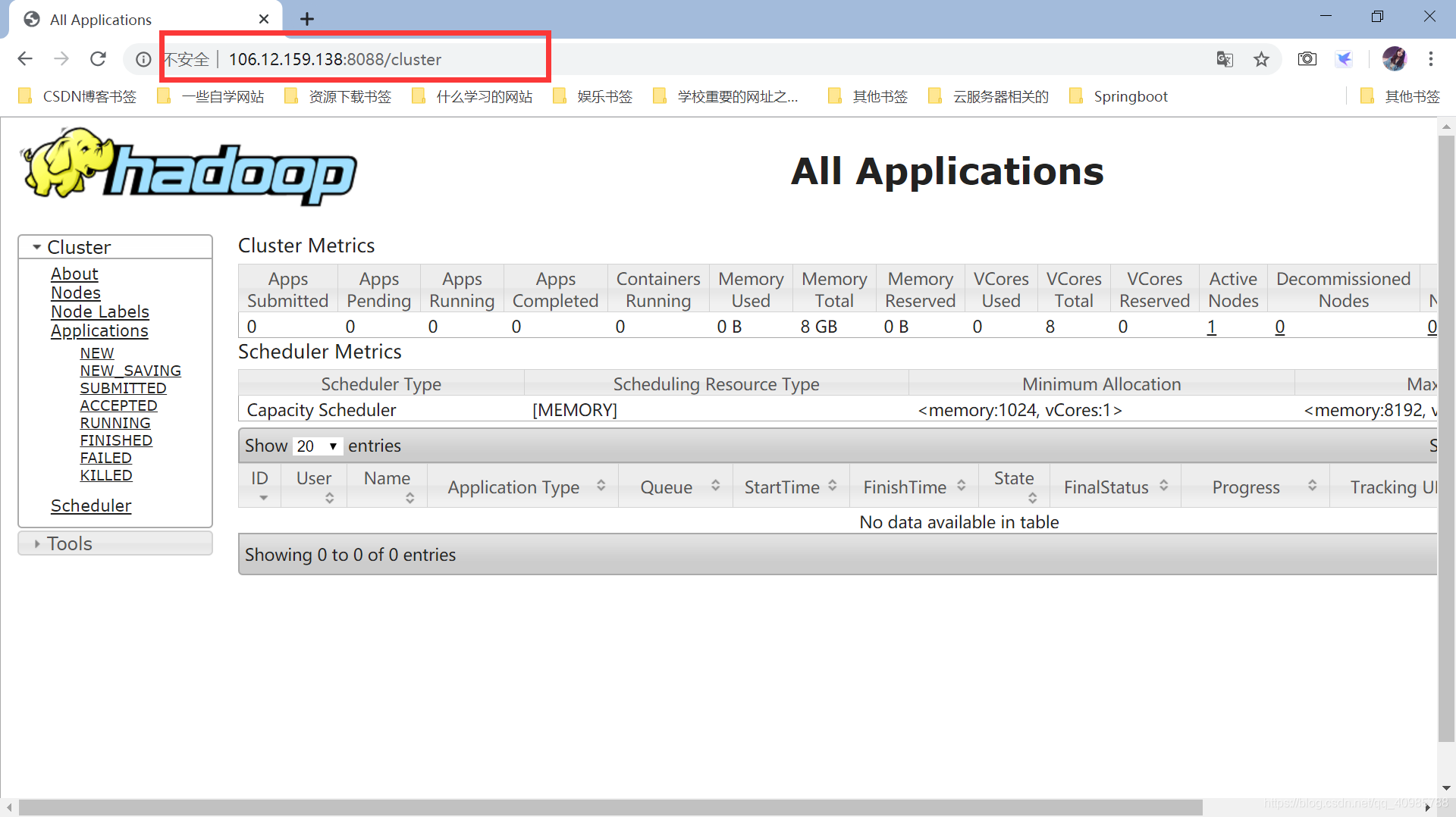
七、开放相应的端口并进行测试
(1)、开放端口
需要开放:
50070:为查看hdfs状态
50010:如果不打开这个端口,在browse directory里就查看不了文件
50075:如果不打开这个端口,可能不能在50070里下载文件
我们可以打开ip:50070对hdfs进行操作
这几个端口必须是要开放的,不开放否则就无法进行相应的操作:
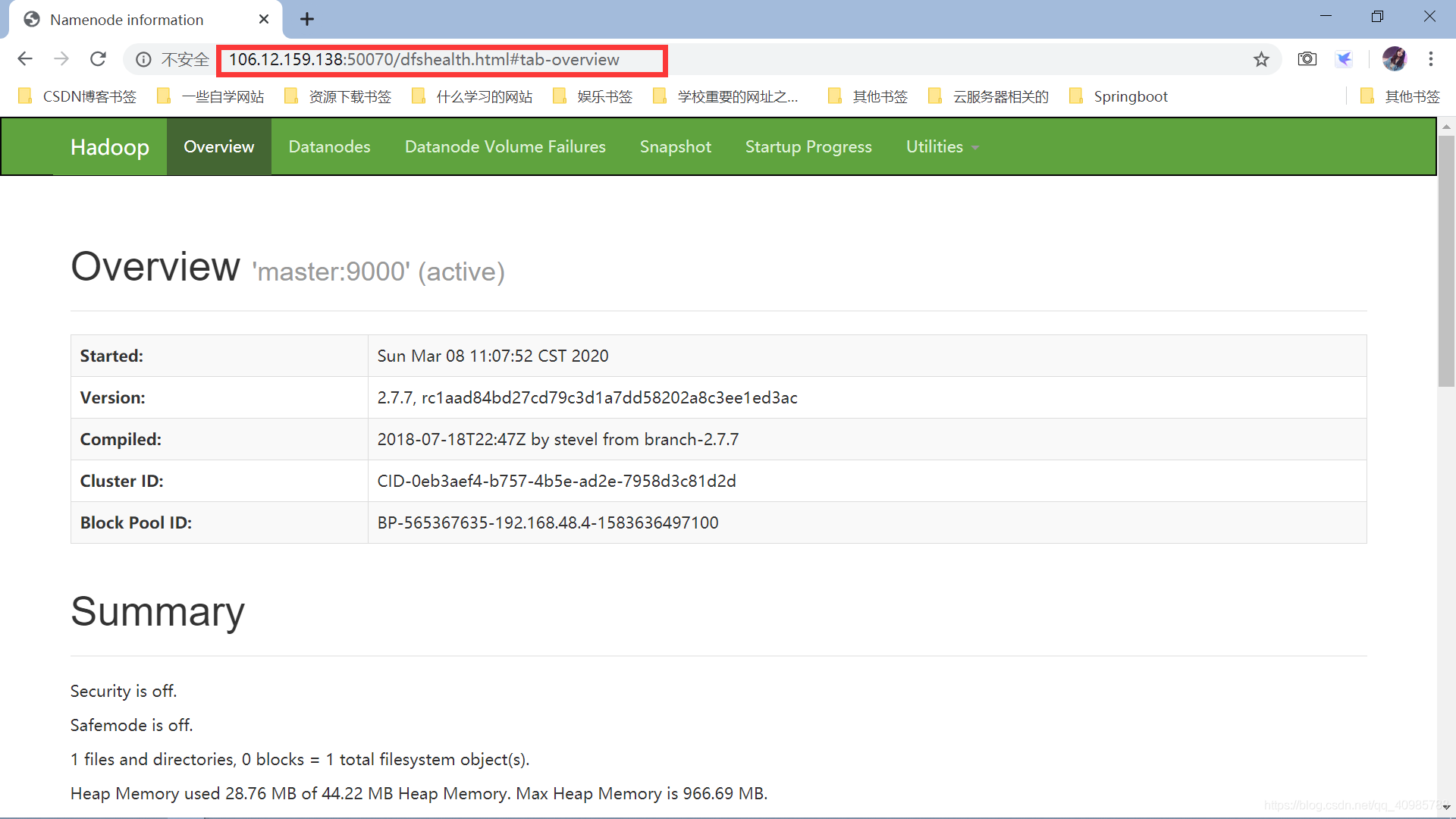
9000:配置中把默认端口改为9000了
8088:查看yarn状态
也可以打开ip:8088查看yarn状态