DDPM回顾
2020年论文《denosing diffusion probabilistic models》
https://arxiv.org/pdf/2006.11239v2.pdf

DDPM分为扩散过程和逆扩散过程
扩散过程
扩散过程是确定性的,x0到xt逐步添加噪声是没有需要训练的参数,是不可训练的固定的马尔科夫链过程,这和VAE是不同的,VAE是通过网络学习而来的
从x0到xt的条件概率写成每一步条件概率的连乘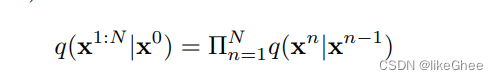
高斯分布q服从定义:
均值为根号下1-βn×xn-1,方差为βnI,I是单位矩阵
给定xn-1情况下,用xn的样本,可以使用重参数技巧,从标准分布中生成一个噪声ε,ε×标准差(根号下βn) + 均值(根号下1-βn×xn-1)获得xn的样本,不断的递推最终获得xt时刻的采样样本
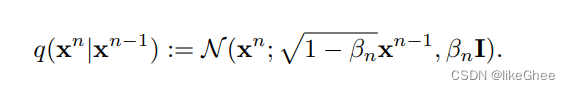
扩散过程使用的是逐渐递增的方差的方案,βn大于βn-1 ∈ (0,1)
逆扩散过程
从xt到x0用了一个假设,假设服从一个条件的高斯分布,pθ(xt-1|xt)是一个高斯分布,基于马尔科夫链假设过程
转移概率xt到xt-1是可学习的高斯分布的基于马尔科夫链的函数拟合出来的
扩散过程最终目标是把原始的数据分布变成标准的高斯分布,因此逆过程的起点我们将xt看作服从N(0,I)均值为0,方差为1的标准高斯分布
因此公式我们写成初始的p(xt)乘上之后每一个马尔可夫链转移过程的条件概率
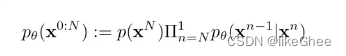
这里的高斯分布是拟合的,可学习的,我们假设每步的分布是服从均值为μθ,方差为∑θ的高斯分布,其中μ和∑是以xt和当前时刻t为参数的可学习的函数
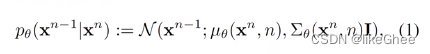
这么做是因为在扩散过程中每步加的噪声是很小的,在逆过程我们也可以用高斯分布去拟合这个过程
最终的目的是要去恢复x0,逐步去消除在扩散过程加的高斯噪声,优化网络的目的似然达到最大,负似然达到最小,负对数似然的上界由公式推导可以得出
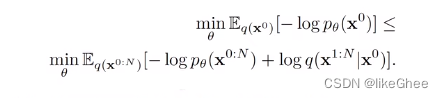
负对数似然
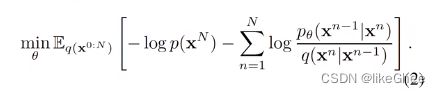
还可以改写成KL散度形式,前两项都是常数,只有第三项是q分布和pθ之间的KL散度和优化有关
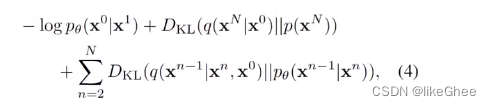
此外还有性质,在给定x0的xt的情况下,就能采样出1到t-1任意时刻的xn,不需要逐步去递推
通过分布组合,两个高斯分布合并成一个高斯分布,那么三个及三个以上的高斯分布也能合并成一个高斯分布,那么由整理公式可以得到,在给定x0的情况下,可以直接推出xn
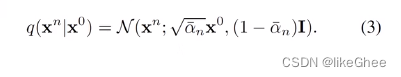
其中an=1-βn,an-bar = ai从1到n的连乘
这样我们就能从x0得到任意时刻的加噪后的图像
根据这个性质,带入负对数似然中,新的负对数似然可以写成
基于公式3可以推出公式5,我们已经知道xn,x0条件下,推出xn-1,给了x0所以是一个后验的概率分布,可以写出均值和方差,均值是x0和xn分别带上两个系数所构成,方差β~完全由βn构成
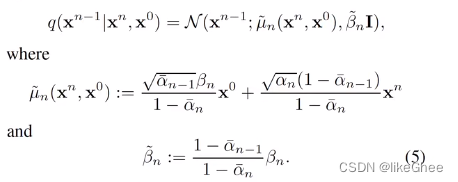
q分布写成了高斯分布,那么q分布和pθKL散度可以写成公式6

此时我们有几种方案,构建一个网络xn和n作为输入去预测均值μ~,但是论文作者说不是很好,而改为去预测噪声
根据公式3,xn可以写成x0的形式,为了让采样过程可导,从标准分布中采用出ε,重参数方式shift和scale得到原始分布采样的效果,反过来x0就可写成xn和ε的形式
x0(xn,ε)带入到公式5中,就可以得到μθ的简化形式 ,其中ε写成含参的形式,原本是去预测μ~ 的,变成了在给定x0的情况下,得到xn所增加的噪声,转移成去预测εθ,

μ~ 减去 μθ得到公式7,构建神经网络,以xn和n作为输入计算出输出,和刚刚加的噪声越近越好,省略系数,loss simple
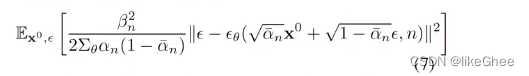
从xn恢复xn-1,通过参数重整,有公式如下,随机噪声z乘以标准差,再加上均值
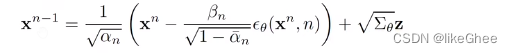
Autoregressive DM概述
https://arxiv.org/pdf/2101.12072.pdf
《Autoregressive Denoising Diffusion Models for Multivariate Probabilistic Time Series Forecasting》
扩散模型和自回归模型结合做多变量的序列预测的任务,基于过去一段时间的数据去预测未来一段时间的数据,并且是由一种自回归的方式去预测
通过DDPM的回顾,我们得到了目标函数
将其运用到自回归模型,我们可以用RNN或者Transformer构建时间依赖性的网络
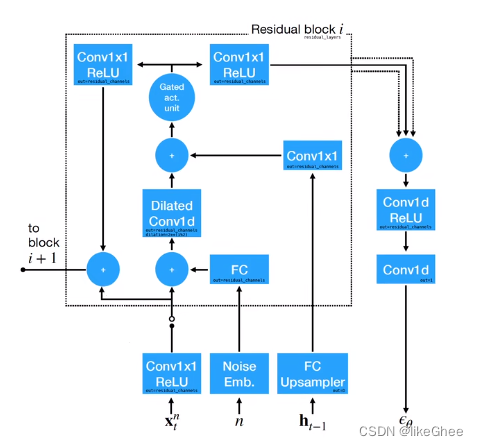
xt-1和ct-1输入到RNN中,生成ht-1,使用条件的扩散模型得到xt,ht-1作为模型的条件,现在有一个条件概率模型能够基于ht-1预测当前时刻的所想要的xt,前向过程还是从x0到xN,只不过在逆扩散过程构建噪声网络的时候加入一个ht-1

算法及目标函数,从数据中的到x0,和当前rnn输出的隐藏状态ht-1,优化εθ,训练网络rnn也随着优化

逆扩散的采样过程,输入xn噪声和隐藏状态ht-1
从n到2迭代,z从标准正态分布采样的到高斯噪声,当t=1时z=0,xn-1用重参数技巧公式
最终得到x0

εθ带残差网络模型,多层的残差模型,xt,n,ht-1作为输入