文章目录
Transformer PE - sin-cos 1d
正余弦不可学习PE,之前的博客里面提到过了,这里引用一下就好
PE矩阵可以看作是两个矩阵相乘,一个矩阵是pos(/左边),另一个矩阵是i(/右边),奇数列和偶数列再分别乘sin和cos
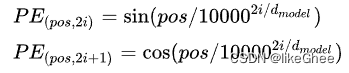
通过这样的PE,可以实现任意位置通过已有的位置编码线性组合表示,不要求偶数列是sin,奇数列是cos,也可以前一半是sin,后一半是cos
之前的代码是hard code的,写的不好,重新实现代码:
import torch
# 1d绝对sin_cos编码
def create_1d_absolute_sin_cos_embedding(pos_len, dim):
assert dim % 2 == 0, "wrong dimension!"
position_emb = torch.zeros(pos_len, dim, dtype=torch.float)
# i矩阵
i_matrix = torch.arange(dim//2, dtype=torch.float)
i_matrix /= dim / 2
i_matrix = torch.pow(10000, i_matrix)
i_matrix = 1 / i_matrix
i_matrix = i_matrix.to(torch.long)
# pos矩阵
pos_vec = torch.arange(pos_len).to(torch.long)
# 矩阵相乘,pos变成列向量,i_matrix变成行向量
out = pos_vec[:, None] @ i_matrix[None, :]
# 奇/偶数列
emb_cos = torch.cos(out)
emb_sin = torch.sin(out)
# 赋值
position_emb[:, 0::2] = emb_sin
position_emb[:, 1::2] = emb_cos
return position_emb
if __name__ == '__main__':
print(create_1d_absolute_sin_cos_embedding(4, 4))
VIT PE - trainable 1d
这里之前博客也写过了,直接引用一下
这里的position embedding的思想类似word embedding,用一个table做embbeding
这里的table是随机初始化的,在模型中是可学习的
实现就比较简单了,使用nn.Embedding即可
import torch
import torch.nn as nn
def create_1d_learnable_embedding(pos_len, dim):
pos_emb = nn.Embedding(pos_len, dim)
# 初始化成全0
nn.init.constant_(pos_emb.weight, 0)
return pos_emb
Sw PE - trainable relative bias 2d
使用的是可学习的二维的相对位置编码, bias是两两patch的相对位置偏差,相对位置偏置bias加到每个head上计算相似度
bias当作索引从bias_emb_table里面查找出一个可学习向量B, B加到Q乘K的结果上,Q乘K shape是[seqL, seqL],因此B的shape是[num_head, seqL, seqL]

我们先初始化一个Embedding,它的行数反应的是bias的值域
假设width等于5,有5个patch,0,1,2,3,4,第一个patch[0]和最后边的patch距离是-4,最 后一个patch和最左边的距离是4,综上距离值域是[-4, 4],个数是2 * 4 + 1,即w_num_b= 2 * (width - 1) + 1 = 2width - 1,同理h_num_b = 2 * (height - 1) + 1 = 2height - 1,所以emb_table有(2w-1)(2*h-1)行, n_head列,每个head都一个bias
relative_bias作为索引去emb_table查
定义子函数,获得每个window中两两patch之间二维的位置偏差,使用torch.meshgrid函数,根据x轴和y轴范围得到网格每个点的x坐标和y坐标,将其堆叠,获取任何两个点之间的横轴与纵轴坐标的差值,扩维做差即可
方向差距变为正数,加上一个(h/w - 1)
将两个方向转换一个方向坐标,即二维数组转换为一维数组,[i, j] -> [i × cols + j] ,cols为列数大小
import torch
import torch.nn as nn
def create_2d_relative_bias_trainable_embedding(n_head, h, w, dim):
pos_emb = nn.Embedding((2*w-1)*(2*h-1), n_head)
nn.init.constant_(pos_emb.weight, 0.)
def get_2d_relative_position_index(height, width):
# m1/m2.shape = [h, w],m1所有行值相同,m2所有列数相同
m1, m2 = torch.meshgrid(torch.arange(height), torch.arange(width))
# [2, h, 2]
coords = torch.stack([m1, m2], dim=0)
# 将h和w维度拉直,[2, h*w]
coords_flatten = torch.flatten(coords, start_dim=1)
# 变成3维列向量[2, h*w, 1] 减去 3维行向量,得到坐标差值
# relative_coords_bias.shape = [2, h*w, h*w],反应两个方向任何两个点之间的差值
relative_coords_bias = coords_flatten[:, :, None] - coords_flatten[:, None, :]
# 方向差距变为正数,bias ∈ [0, 2(h - 1)]/[0, 2(w - 1)]
relative_coords_bias[0, :, :] += height - 1
relative_coords_bias[1, :, :] += width - 1
# 将两个方向转换一个方向坐标, [i, j] -> [i*cols + j]
relative_coords_bias[0, :, :] *= relative_coords_bias[1, :, :].max()+1
return relative_coords_bias.sum(0) # [h*w, h*w]
relative_pos_bias = get_2d_relative_position_index(h, w)
# 基于相对bias去Embedding中去查
bias_emb = pos_emb(relative_pos_bias.flatten()).reshape([h*w, h*w, n_head])
# 转置一下n_head,放到第0维
bias_emb = bias_emb.permute(2, 0, 1).unsqueeze(0) # [1, n_head, h*w, h*w]
return bias_emb
emb = create_2d_relative_bias_trainable_embedding(1, 2, 2, 4)
print(emb.shape)
MAE PE - sin cos 2d
使用的2维的fixed的sine-cosine PE,没有用相对位置和layer scaling
import torch
import trainable_1d_pe
def create_2d_absolute_sin_cos_embedding(h, w, dim):
# 奇数列和偶数列sin_cos,还有h和w方向,因此维度是4的倍数
assert dim % 4 == 0, "wrong dimension"
pos_emb = torch.zeros([h*w, dim])
m1, m2 = torch.meshgrid(torch.arange(h), torch.arange(w))
# [2, h, 2]
coords = torch.stack([m1, m2], dim=0)
# 高度方向的emb
h_emb = trainable_1d_pe.create_1d_learnable_embedding(torch.flatten(coords[0]).numel(), dim // 2)
# 宽度方向的emb
w_emb = trainable_1d_pe.create_1d_learnable_embedding(torch.flatten(coords[1]).numel(), dim // 2)
# 拼接起来
pos_emb[:, :dim//2] = h_emb.weight
pos_emb[:, dim//2:] = w_emb.weight
return pos_emb
create_2d_absolute_sin_cos_embedding(2, 2, 4)