文章目录
Google 在 2012 年的 I/O 大会上宣布了 Project Butter 黄油计划,曾经严重影响 Android 口碑的 UI 流畅性问题在这得到有效的控制,并且在 Android 4.1 中正式开启了这个机制。Project Butter 对 Android Display 系统进行了重构,引入了三个核心元素:VSync、Triple Buffer 和 Choreographer。
VSync
帧率和刷新频率
在了解 UI 刷新机制之前,有必要先说明经常提及的两个概念:
- 刷新频率(Refresh Rate):屏幕在1秒内刷新屏幕的次数,这取决于硬件的固定参数,例如60Hz
- 帧率(Frame Rate):GPU 在1秒内绘制操作的帧数,例如 60fps
60fps 和 16.6ms
在 Android 开发中经常能听到要求应用的性能 UI 刷新要达到 60 帧每秒(Frame Per Second)和 16.6ms,但有考虑过为什么要 60fps?为什么是 16.6ms?作为一名开发人员这是一个值得研究的技术细节。
人的眼睛和相机不同,眼睛并不会向大脑发送这个世界的截图,相反,你的大脑会持续的处理你的眼睛传送的可视图像。但是这里并没有帧和截图的概念,我们这种动作是由帧组合的概念,如果能足够快速的显示图像,我们就可以欺骗人类大脑,让它们以为眼前的帧就是动作。
需要注意的是,图像的显示速度快慢很大地影响了动作地流畅性,最少你会需要 10-12fps 的速度才能让人类大脑相信这些图像是一个动作。
当达到 24fps 时,人眼会看到流畅的画面,24fps 在电影行业非常普遍,因为它对展现动作来说已经足够,同时制作成本也足够低能满足电影制作的预算,但还要多亏运动模糊这些视觉效果才能让我们在看电影时仍能有流畅的画面。
当达到 60fps 时效果才是最棒的,不需要那些视觉效果仍能做到流畅。针对图片的非连续性,人眼的辨识力还是非常高的,例如,如果以 60fps 的速度运动,然后时不时突然降至 20fps,人眼就会察觉到这里面的不流畅性。
作为应用开发人员,我们需要保证我们的应用能够在 60fps 即 16.6ms每帧(1000ms / 60fps = 16.666ms/frame)完成 UI 的流畅更新,完成包括输入、计算、网络传输和渲染等,只有这样我们的应用才会有流畅的用户体验。
使用 60fps 帧率除了该帧率足够”欺骗“人类大脑感受到流畅的体验外,还有就是刷新频率即和硬件有关,现在大部分手机屏幕的刷新频率都维持在 60Hz,移动设备一般使用 60Hz,是因为移动设备对于功耗的要求更高,提高手机屏幕的刷新频率功耗会随着频率的增大而线性增大,同时更高的刷新频率也意味着更短的TFT数据写入时间,对于屏幕设计来说难度更大。
那更高的刷新频率是否就能有更流畅的用户体验?如果要提升,需要软件和硬件一起提升,只提升其中一个是基本没有效果的,比如屏幕刷新频率是 75Hz,软件是 60fps,除了重复刷新帧增加耗电外没啥效果。
相信未来会是高刷新频率屏幕的天下,但需要突破几点:电池续航能力、软件技术、硬件能力。
回过头来回答开头提出的问题:为什么是 60fps?
- 60fps 即 16.6ms 一帧的 UI 刷新足够 ”欺骗“ 人类大脑感受应用流畅和很好的用户体验
- 设备刷新频率硬件固定参数是 60Hz,主要考量功耗、屏幕设计、电池续航能力、成本等因素,目前 60Hz 是能兼顾流畅体验和硬件要求成本的数值,帧率需要和刷新频率同步
屏幕撕裂和 Double Buffer(双重缓存)
tearing 屏幕撕裂
刷新出一帧数据显示到屏幕上会经过三个步骤:
- CPU 将控件解析计算为 polygons 多边形和 textures 纹理
- polygons(多边形) 和 textures(纹理) 交由 GPU 将这些数据进行栅格化
- 硬件负责把栅格化后的内容呈现到屏幕上,显示出一帧
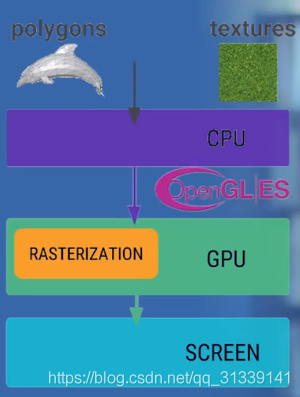
CPU/GPU 生成图像数据写入到 Buffer,屏幕从 Buffer 中读取数据,两者使用的同一个 Buffer 不停的进行协作:
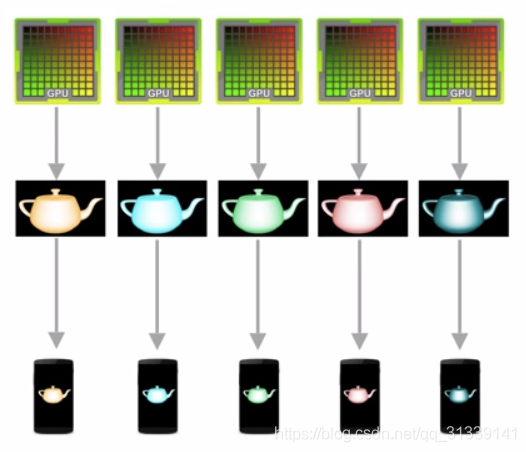
理想情况下帧率和刷新频率保持一致,即每绘制完一帧显示一帧。
不幸的是,帧率和刷新频率并不总是保持相对同步:GPU 写入数据的 Buffer 和屏幕读取数据的 Buffer 是同一个,当帧率比刷新频率快时(即读取速度比写入速度慢),比如帧率 120fps,刷新频率 60Hz,当 GPU 已经写入一帧数据到 Buffer,新一帧部分内容也写到了 Buffer,当屏幕刷新时,它并不知道 Buffer 的状态并读取了 Buffer 中并不完整的一帧画面:

此时屏幕显示的图像会出现上半部分和下半部分明显偏差的现象,这种情况被称为 tearing 屏幕撕裂。
Double Buffer(双重缓冲)和 VSync
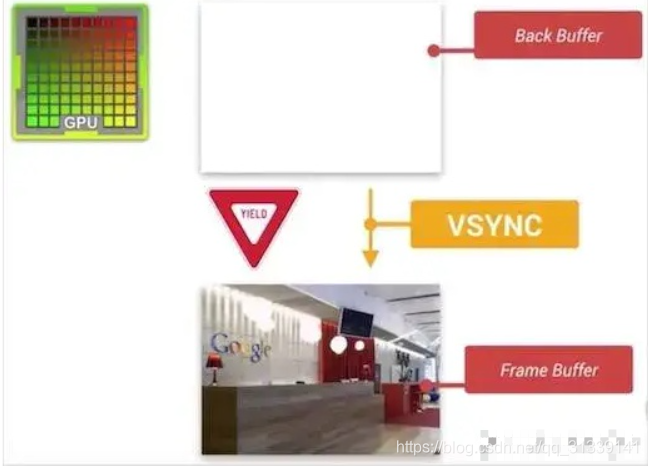
帧率和刷新频率不一致并且是操作同一个 Buffer 导致的屏幕撕裂现象,解决这个问题的办法就是使用 Double Buffer 双重缓冲,让 GPU 和显示器各自拥有 Buffer 缓冲区。GPU 始终将完成的一帧图像数据写入到 Back Buffer,而显示器使用 Frame Buffer 读取显示。
但也出现了一个问题:什么时候将 Back Buffer 的数据交换显示到 Frame Buffer?假如 Back Buffer 准备完成帧数据后就进行交换,如果此时屏幕还没有完整显示上一帧的内容,还是会出现屏幕撕裂问题。只能是等到屏幕处理完一帧数据后,才可以执行这一操作。
显示器显示一帧时,设备需要重新回到第一行以进行下一次循环,此时有一段时间空隙称为 Vertical Blacking Interval(VBI),在这个时间点就是进行缓冲区交换的最佳时间,因为屏幕此时没有在刷新,也就避免了交换过程中出现屏幕撕裂的情况。Vsync (Vertical Synchronization)垂直同步,它利用 VBI 保证双缓冲在最佳时间点进行交换。
当 GPU 将一帧数据写入到 Back Buffer 时,VSync 信号调度 Back Buffer 将图形数据 copy 到 Frame Buffer(copy 并不是真正的数据 copy,实际是交换各自的内存地址,可以认为是瞬时完成的)。
Jank 和 Triple Buffer(三重缓冲)
Jank 重复刷新帧
从上面我们了解到,一帧数据绘制最终显示到屏幕是需要经过 CPU 对控件计算转换为 polygons 多边形和 textures 纹理,然后交由 GPU 栅格化,最终才把一帧显示到屏幕,三步操作在帧率为 60fps 和刷新频率为 60Hz 的情况下,要求我们在 16.6ms 内完成这些工作。
在没有 VSync 同步时,当 CPU/GPU 绘制过慢时会出现如下情况:
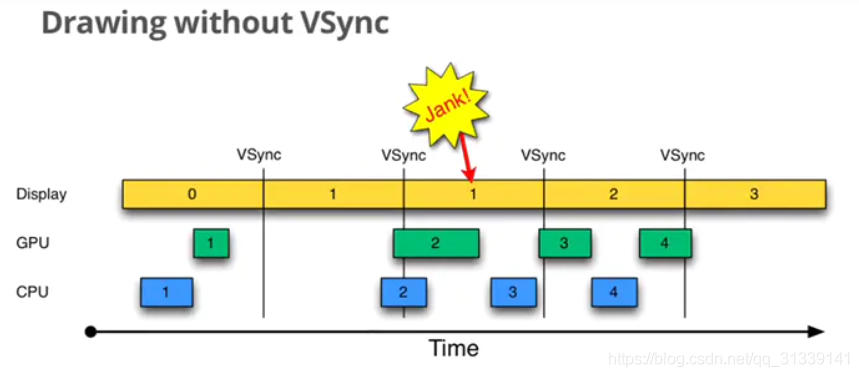
图中有三个元素,Display 是显示屏幕,CPU 和 GPU 负责渲染帧数据,每个帧以方框表示,并以数据编号,VSync 用于指导双缓冲区的交换。以时间顺序看下发生的异常:
- Step1:Display 显示第 0 帧数据,此时 CPU 和 GPU 渲染第 1 帧画面,而且赶在 Display 显示下一帧前完成
- Step2:因为渲染及时,Display 在第 0 帧显示完成后,也就是第 1 个 VSync 后正常显示第 1 帧
- Step3:由于某些原因,比如 CPU 资源被占用,系统没有及时地开始处理第 2 帧,直到第 2 个 VSync 快来之前才开始处理
- Step4:第 2 个 Vsync 来时,由于第 2 帧数据还没有准备就绪,显示的还是第 1 帧
第 2 帧数据准备完成后,它并不会马上被显示,而是要等待下一个 VSync。所以总的来说,就是屏幕平白无故地多显示了一次第 1 帧。原因是 CPU 没有及时地开始着手第 2 帧地渲染工作导致,这种情况被命名为 Jank。
如何让第 2 帧被及时绘制呢?这就是我们在 Graphic 系统中引入 Vsync 的原因:
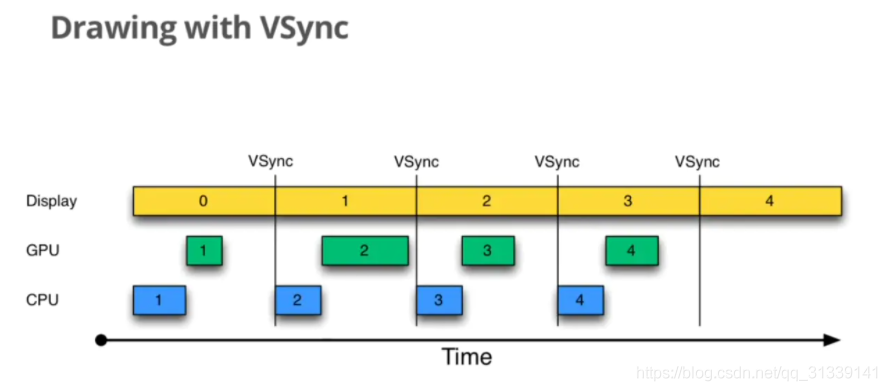
如上图所示,一旦 VSync 出现后,立刻就开始执行下一帧的绘制工作。这样就可以大大降低 Jank 出现的概率。
另外,VSync 引入后,要求绘制也只能在收到 VSync 信号之后才能进行,因此,也就杜绝了另外一种极端情况的出现—-CPU(GPU)一直不停的进行绘制,帧的生成速度高于屏幕的刷新速度,导致生成的帧不能被显示,只能丢弃,这样就出现了丢帧的情况—-引入 VSync 后,绘制的速度就和屏幕刷新的速度保持一致了。
Triple Buffer(三重缓冲)
在正常情况下,采用双缓冲区和 VSync 的运行情况如下:
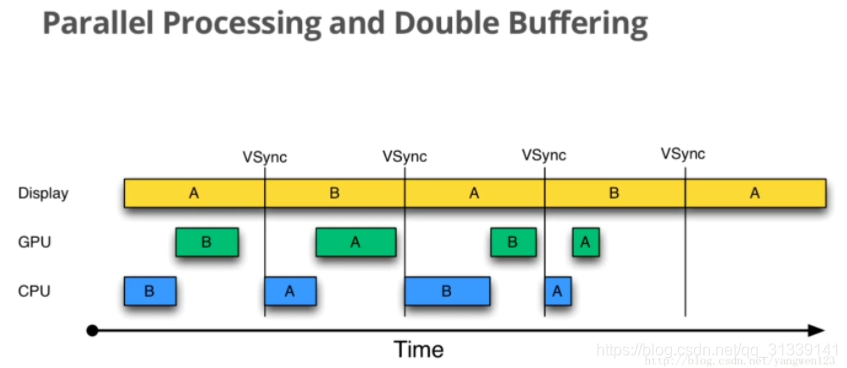
虽然上图 CPU 和 GPU 处理所用的时间有时长有时短,但总的来说都是在 16.6ms 以内,因此不影响效果,A 和 B 两个缓冲区不断交换来正确显示画面。
大部分的 Android 显示设备刷新频率是 60Hz,意味着每一帧最多只能有 16.6ms 左右的准备时间,但我们没有办法保证所有设备的硬件配置都能达到这个要求,假如 CPU/GPU 性能无法满足,将会发生如下情况:
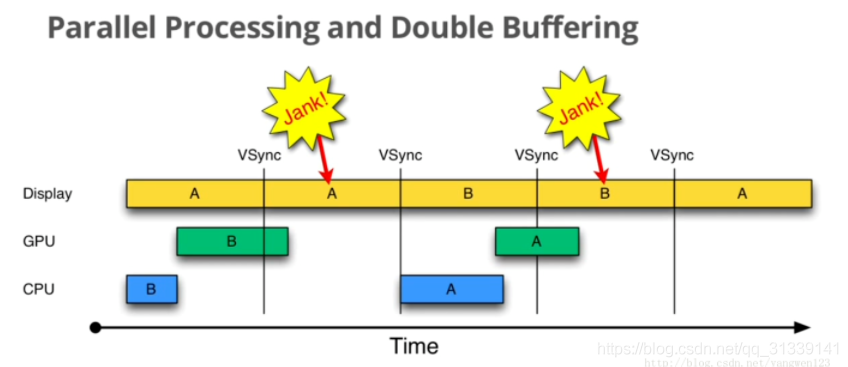
由上图可知:
- 在第二个 16.6ms 时间段内,Display 本应该显示 B 帧,但却因为 GPU 还在处理 B 帧导致 A 帧被重复显示
- 同理,在第二个 16.6ms 时间段内,CPU 无所事事,因为 A Buffer 被 Display 使用,B Buffer 被 GPU 使用,一旦过了 VSync 信号周期,CPU 就不能被触发处理绘制工作了
解决上述问题的方式就是使用 Triple Buffer 三重缓冲,其实就是在双重缓冲的基础上再增加一个 Graphic Buffer 缓冲区提供给 CPU,这样可以最大限度地利用空闲时间,带来的坏处是多使用了一个 Graphic Buffer 所占用的内存。
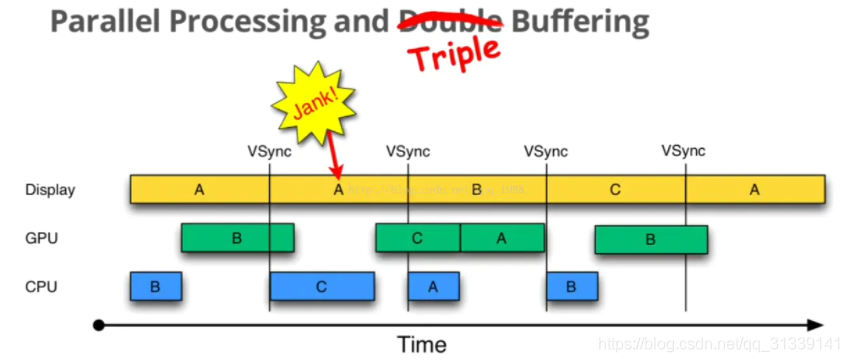
在第二个 16.6ms 时间段,CPU 使用 C Buffer 完成绘图工作,虽然还是会多显示一次 A 帧,但后续显示就比较顺畅了,有效避免 Jank 的进一步加剧。
小结
上面详细讲解了为什么会有 Vsync 以及 Double Buffer 和 Triple Buffer 缓冲区的由来,这些处理都是为了让刷新速率和帧率保持同步达到每帧能在 16.6ms 能处理完并显示,有一个流畅的用户体验。
我们再重新将相关知识点梳理一下:
- Vsync:可以认为是一次信号中断,每次 Vsync 到来(即 16.6ms 到来)时,告知 CPU/GPU 开始处理一帧数据。这里还涉及到 Choreographer,在下面会讲;
- Jank:CPU/GPU 没能在 16.6ms 内将一帧数据处理好给到屏幕刷新显示,导致屏幕在下一个 16.6ms 内还显示上一帧,Jank 即重复刷帧;
- 丢帧:CPU/GPU 处理帧的速度过快高于屏幕刷新显示,导致生成的帧不能被显示,只能丢弃即丢帧。
无论是 CPU 将控件计算转换为多边形和纹理,还是 GPU 栅格化,甚至 CPU 将数据传到 GPU,这些都是耗时的操作,如果实际项目中 View 层级太多或者过度绘制严重,将会导致这些处理有更大的耗时。
在实际的项目开发中,导致 Jank 和丢帧的原因其实有多种,例如锁阻塞、系统资源分配导致 CPU 时间片资源没分配给到 UI 线程、控件层级嵌套过多等,从 UI 层面我们应该时刻关注 View 的层级和过度绘制问题,否则即使在有 Vsync、Triple Buffer 等加持,CPU 和 GPU 处理耗时过长还是会导致 Jank 和丢帧问题。
Choreographer
Choreographer 主要是配合 Vsync,给上层 App 的渲染提供一个稳定的绘制处理时机,即 Vsync 即 16.6ms 到来时,Choreographer 可以接收 VSync 信号,统一管理应用的输入、动画、绘制等任务的执行时机。Android 的 UI 绘制任务将在他的同一指挥下完成,这是引入 Choreographer 的作用。
因为 Choreographer 可以接收 Vsync 信号,所以也可以用它监控帧率。接下来我们通过源码看下它是怎么做到的绘制管理,这需要从 View 的绘制流程 中 ViewRootImp 的源码开始:
//ViewRootImpl.java
void scheduleTraversals() {
if (!mTraversalScheduled) {
mTraversalScheduled = true;
mTraversalBarrier = mHandler.getLooper().getQueue().postSyncBarrier();
// Choreographer 提供一个 mTraversalRunnable 回调,收到回调时触发 UI 绘制
mChoreographer.postCallback(
Choreographer.CALLBACK_TRAVERSAL, mTraversalRunnable, null);
...
}
}
//Choreographer.java
public final class Choreographer {
private final FrameDisplayEventReceiver mDisplayEventReceiver;
public void postCallback(int callbackType, Runnable action, Object token) {
postCallbackDelayed(callbackType, action, token, 0);
}
public void postCallbackDelayed(int callbackType,
Runnable action, Object token, long delayMillis) {
...
postCallbackDelayedInternal(callbackType, action, token, delayMillis);
}
private void postCallbackDelayedInternal(int callbackType,
Object action, Object token, long delayMillis) {
...
synchronized (mLock) {
final long now = SystemClock.uptimeMillis();
final long dueTime = now + delayMillis;
mCallbackQueues[callbackType].addCallbackLocked(dueTime, action, token);
if (dueTime <= now) {
scheduleFrameLocked(now);
} else {
// 调用 doScheduleCallback(),实际还是调用的 scheduleFrameLocked()
Message msg = mHandler.obtainMessage(MSG_DO_SCHEDULE_CALLBACK, action);
msg.arg1 = callbackType;
msg.setAsynchronous(true);
mHandler.sendMessageAtTime(msg, dueTime);
}
}
}
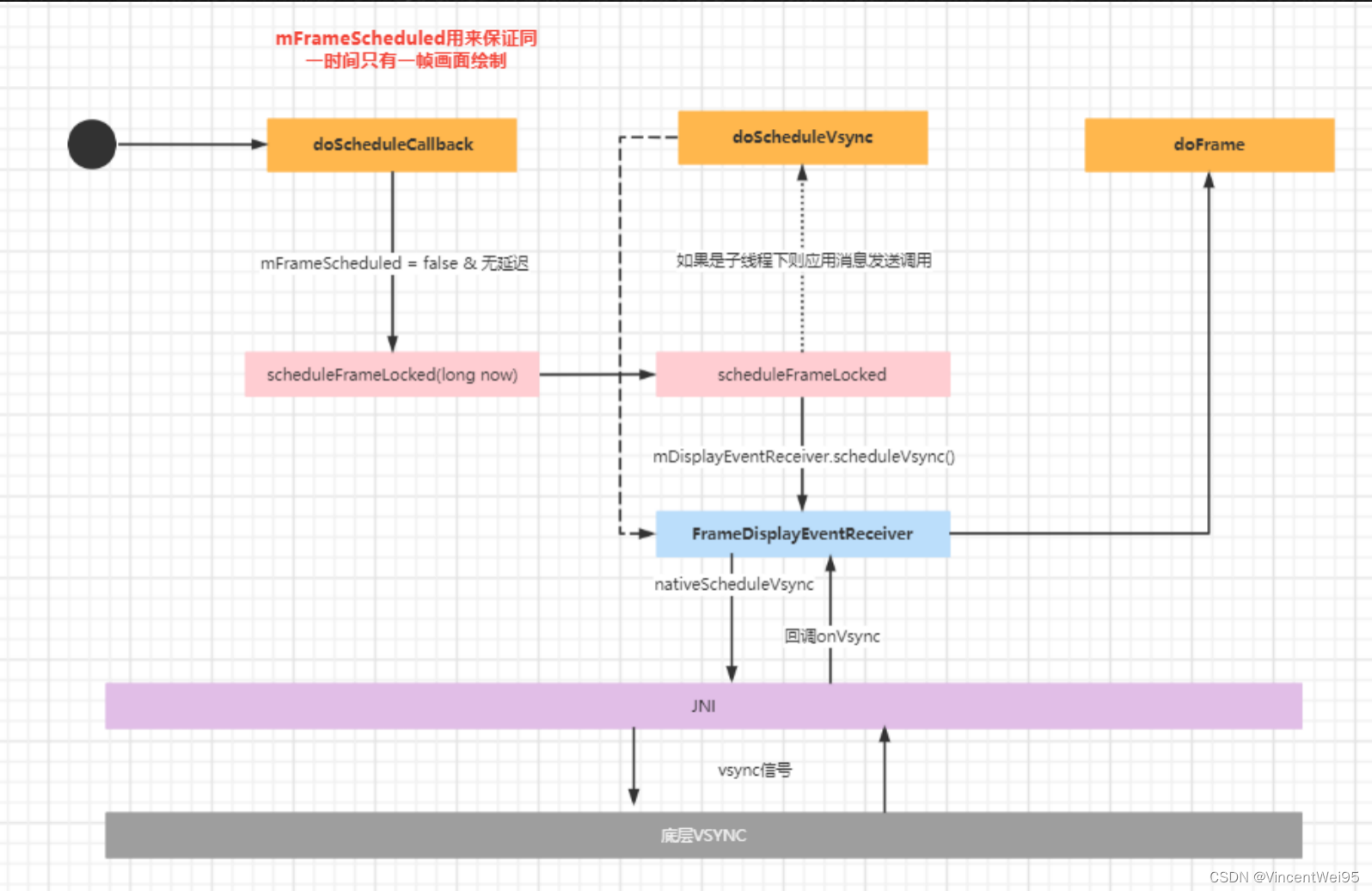
void doScheduleCallback(int callbackType) {
synchronized (mLock) {
// mFrameScheduled 保证同一时间只有一帧画面绘制
if (!mFrameScheduled) {
final long now = SystemClock.uptimeMillis();
if (mCallbackQueues[callbackType].hasDueCallbacksLocked(now)) {
scheduleFrameLocked(now);
}
}
}
}
private void scheduleFrameLocked(long now) {
if (!mFrameScheduled) {
mFrameScheduled = true;
if (USE_VSYNC) {
...
// 如果是主线程
if (isRunningOnLooperThreadLocked()) {
scheduleVsyncLocked();
} else {
// 调用 doScheduleVsync(),实际还是调用的 scheduleVsyncLocked()
Message msg = mHandler.obtainMessage(MSG_DO_SCHEDULE_VSYNC);
msg.setAsynchronous(true);
mHandler.sendMessageAtFrontOfQueue(msg);
}
}
...
}
}
void doScheduleVsync() {
synchronized (mLock) {
if (mFrameScheduled) {
scheduleVsyncLocked();
}
}
}
private void scheduleVsyncLocked() {
// mDisplayEventReceiver 是 FrameDisplayEventReceiver
// scheduleVsync() 是父类 DisplayEventReceiver 的方法
mDisplayEventReceiver.scheduleVsync();
}
private final class FrameDisplayEventReceiver extends DisplayEventReceiver
implements Runnable {
@Override
public void onVsync(long timestampNanos, int builtInDisplayId, int frame) {
...
}
}
}
public abstract class DisplayEventReceiver {
public void scheduleVsync() {
if (mReceiverPtr == 0) {
Log.w(TAG, "Attempted to schedule a vertical sync pulse but the display event "
+ "receiver has already been disposed.");
} else {
nativeScheduleVsync(mReceiverPtr);
}
}
private static native void nativeScheduleVsync(long receiverPtr);
// Called from native code.
// nativeScheuleVsync 最终会从 JNI 层回调 dispatchVsync
private void dispatchVsync(long timestampNanos, int builtInDisplayId, int frame) {
// 拿到上一帧的时间 timestampNanos
onVsync(timestampNanos, builtInDisplayId, frame);
}
public void onVsync(long timestampNanos, int builtInDisplayId, int frame) {
}
}
从上面的代码可以发现,Choreographer 调用 postCallback() 实际上是通过 DisplayEventReceiver 等 Vsync 信号回调一个时间,所以所谓的 Vsync 就是去底层找驱动要一个绘制上一帧的时间。
收到 Vsync 后就会开始通知 CPU/GPU 处理一帧数据,接着往下看代码:
public final class Choreographer {
private final class FrameDisplayEventReceiver extends DisplayEventReceiver
implements Runnable {
private boolean mHavePendingVsync;
private long mTimestampNanos;
private int mFrame;
public FrameDisplayEventReceiver(Looper looper, int vsyncSource) {
super(looper, vsyncSource);
}
@Override
public void onVsync(long timestampNanos, int builtInDisplayId, int frame) {
mTimestampNanos = timestampNanos;
mFrame = frame;
Message msg = Message.obtain(mHandler, this);
msg.setAsynchronous(true);
mHandler.sendMessageAtTime(msg, timestampNanos / TimeUtils.NANOS_PER_MS);
}
@Override
public void run() {
mHavePendingVsync = false;
doFrame(mTimestampNanos, mFrame);
}
}
// frameTimeNanos:从底层拿到的上一帧的时间
void doFrame(long frameTimeNanos, int frame) {
final long startNanos;
synchronized (mLock) {
if (!mFrameScheduled) {
return; // no work to do
}
...
// 上一帧的时间
long intendedFrameTimeNanos = frameTimeNanos;
// 当前时间(包括了底层消息通信和回调的时间)
startNanos = System.nanoTime();
// 当前时间戳 - vsync 来的时间,也就是主线程耗时的时间
final long jitterNanos = startNanos - frameTimeNanos;
// 如果大于一帧的时间,说明掉帧了(跳帧 16.6ms)
if (jitterNanos >= mFrameIntervalNanos) {
// 掉帧的数量
final long skippedFrames = jitterNanos / mFrameIntervalNanos;
// SKIPPED_FRAME_WARNING_LIMIT = 30
if (skippedFrames >= SKIPPED_FRAME_WARNING_LIMIT) {
// 常见的掉帧打印就是在这里输出的
Log.i(TAG, "Skipped " + skippedFrames + " frames! "
+ "The application may be doing too much work on its main thread.");
}
final long lastFrameOffset = jitterNanos % mFrameIntervalNanos;
frameTimeNanos = startNanos - lastFrameOffset;
}
...
}
try {
Trace.traceBegin(Trace.TRACE_TAG_VIEW, "Choreographer#doFrame");
AnimationUtils.lockAnimationClock(frameTimeNanos / TimeUtils.NANOS_PER_MS);
// 处理输入事件
mFrameInfo.markInputHandlingStart();
doCallbacks(Choreographer.CALLBACK_INPUT, frameTimeNanos);
// 处理动画事件
mFrameInfo.markAnimationsStart();
doCallbacks(Choreographer.CALLBACK_ANIMATION, frameTimeNanos);
// 开始处理绘制过程,最终是回调到 ViewRootImpl 的 mTraversalRunnable
mFrameInfo.markPerformTraversalsStart();
doCallbacks(Choreographer.CALLBACK_TRAVERSAL, frameTimeNanos);
doCallbacks(Choreographer.CALLBACK_COMMIT, frameTimeNanos);
} finally {
AnimationUtils.unlockAnimationClock();
Trace.traceEnd(Trace.TRACE_TAG_VIEW);
}
...
}
}
当 Choreographer 收到 Vsync 信号拿到上一帧的时间后,开始计算是否有掉帧问题,然后开始下一帧如输入事件、动画、测量布局绘制流程。
Choreographer 总体流程如下:
RenderThread
经过 Project Butter 黄油计划之后,Android 的渲染性能有了很大的改善,但是不知道你有没有注意到一个问题,虽然我们利用了 GPU 的图形高性能运算,但是从计算 DisplayList,到通过 GPU 绘制到 Frame Buffer,整个计算和绘制都在 UI 主线程中完成。
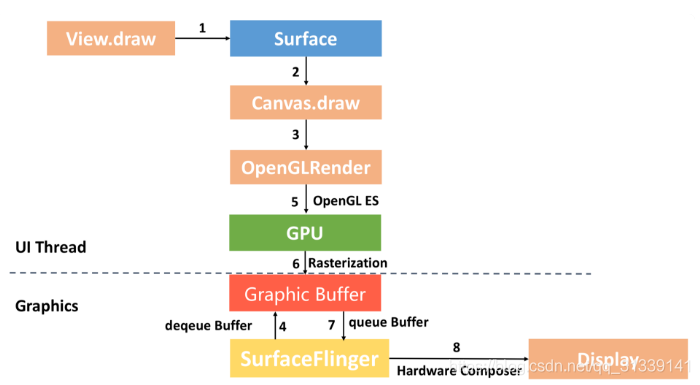
UI 主线程任务过于繁重,如果整个渲染过程比较耗时,可能造成无法响应用户的操作,进而出现卡顿。GPU 对图形的绘制渲染能力更胜一筹,如果使用 GPU 并在不同线程绘制渲染图形,那么整个流程会更加顺畅。
正因如此,在 Android 5.0 引入了两个比较大的改变。一个是引入了 RenderNode 的概念,它对 DisplayList 及一些 View 显示属性做了进一步封装;另一个是引入了 RenderThread,所有的 GL 命令执行都放到这个线程上,渲染线程在 RenderNode 中存有渲染帧的所有信息,可以做一些属性动画,这样即便主线程有耗时操作的时候也可以保证动画流畅。
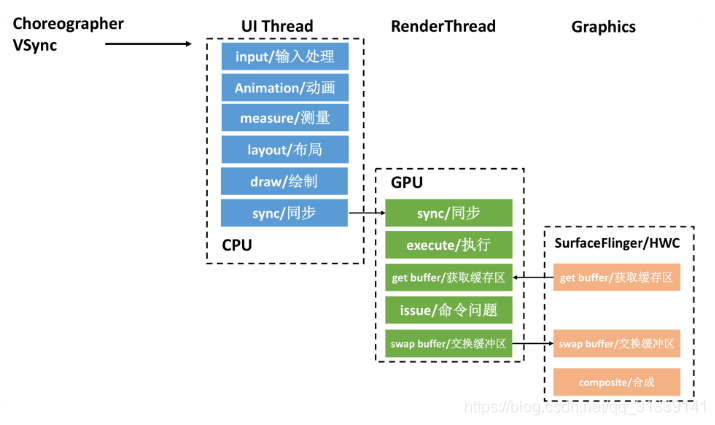
CPU 将数据同步给 GPU 之后,一般不会阻塞等待 GPU 渲染完毕,而是通知结束后就返回。而 RenderThread 承担了比较多的绘制工作,分担了主线程很多压力,提高了 UI 线程的响应速度。