混合精度量化模型指标模拟计算(BitOps与参数规模)
模型的量化是将模型参数的存储位数降低,从而压缩模型或使模型更易于部署到特定硬件。例如不经量化的模型每个参数需要32个bit位存储,量化后的模型的参数可以仅使用8个bit位。而混合精度的量化不将模型参数量化到相同的bit位数(位宽),而是网络的不同层的参数采用不同的位宽。 这导致了混合精度量化模型的指标难以像全精度模型易于计算,而即使是支持TensorCore的GPU设备也无法保证能够使模型在随意的bit位数上推理。
1. 前言
本文提取了LIMPQ算法源码,实现了混合精度量化模型的BitOps和参数规模的计算。 请注意:
- 两个指标通过模拟混合精度模型所得,并非是以硬件感知的方法计算;
- 本文代码提取了LIMPQ的部分代码,使指标计算易于理解;
- 在使用与LIMPQ相同的量化策略情况下,本文代码获得了与原文相同的BitOps、参数规模;
- 感谢LIMPQ的开源工作。
LIMPQ源码: https://github.com/1hunters/LIMPQ
LIMPQ源论文:https://arxiv.org/abs/2203.08368
2. 核心代码
首先是本文的整个demo,demo_get_indicators.py代码:
import torch
import argparse
from models.model import get_model
parser = argparse.ArgumentParser()
parser.add_argument('--model', type=str, default='resnet50', help='模型名称')
parser.add_argument('--weight_bits', type=list, help='权重量化策略')
parser.add_argument('--act_bits', type=list, help='激活量化策略')
args = parser.parse_args()
# --------------- model and bit-width settings ---------------
'''手动设定权重量化策略和激活量化策略'''
weight_bits=[6, 3, 4, 5, 4, 4, 5, 4, 4, 5, 4, 3, 4, 3, 3, 3, 4, 4, \
3, 4, 4, 3, 4, 3, 2, 3, 2, 3, 2, 3, 3, 2, 2, 3, 2, 2, 2, 2, 2, \
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2]
act_bits=[6, 4, 6, 6, 6, 3, 4, 6, 3, 4, 5, 3, 5, 5, 6, 3, 4, 5, \
3, 4, 5, 3, 4, 4, 4, 6, 5, 5, 4, 5, 5, 4, 6, 5, 3, 5, 6, 3, 5, \
6, 3, 6, 4, 4, 6, 2, 6, 4, 6, 6, 4, 6]
'''读取参数设定权重量化策略和激活量化策略'''
# weight_bits=args.weight_bits
# act_bits=args.act_bits
model_name = args.model
model = get_model(model_name)
# --------------- units ---------------
MB = 1024*1024*8
GBITOPS = 1e9
# --------------- calculate the complexity ---------------
def compute_ops_hook(self, input):
x = input[0]
w_h = int(((x.shape[2]+2*self.padding[0]-self.dilation[0]*(self.kernel_size[0]-1)-1)/self.stride[0] + 1)
* ((x.shape[3]+2*self.padding[1]-self.dilation[1]*(self.kernel_size[1]-1)-1)/self.stride[1] + 1))
lw_bitops = (self.in_channels*self.out_channels*w_h *
(self.kernel_size[0]**2))//self.groups
bit_ops.append(lw_bitops)
bit_ops = []
number_of_tensor = []
extra_bitops = 0
for name, module in model.named_modules():
if isinstance(module, torch.nn.Conv2d):
module.register_forward_pre_hook(compute_ops_hook)
number_of_tensor.append(
(module.in_channels*module.out_channels*module.kernel_size[0]*module.kernel_size[1])//module.groups)
elif isinstance(module, torch.nn.Linear):
linear_number = module.in_features * module.out_features
model(torch.randn((1, 3, 224, 224)))
extra_bitops += bit_ops[0] + linear_number
bit_ops = bit_ops[1:]
first_layer_size = number_of_tensor[0]
number_of_tensor = number_of_tensor[1:]
layer_name_list = []
if model_name=='resnet50':
model_deepth=52
elif model_name=='resnet18':
model_deepth=20
for i in range(model_deepth):
layer_name_list.append('paras module '+str(i))
# compress radio cons
extra_model_size = (linear_number + first_layer_size) * 8
total_params = sum([32*i for i in number_of_tensor]) + \
32 * (linear_number + first_layer_size)#全精度模型的参数规模
total_bitops = 0
avg_bitops = 0
weight_sum = 0
w_sum=sum(weight_bits)
a_sum=sum(act_bits)
weight_sum = sum([weight_bits[i] * number_of_tensor[i]
for i in range(len(weight_bits))])
linear_weight_bits = 8
first_conv_layer_weight_bits = 8
#量化后模型的参数规模
quantized_model_size = weight_sum + linear_number * linear_weight_bits + first_layer_size * first_conv_layer_weight_bits
print("*"*80)
print('avg weight', w_sum/len(layer_name_list),
'avg act', a_sum/len(layer_name_list))
print('compress radio', (total_params)/(quantized_model_size))
print("FP model size (MB)", round(total_params/MB, 3))
print('quantized model size (MB)', round((quantized_model_size)/MB, 3))
print("*"*80)
linear_act_bits = 8
fp_bitops = sum(
[bit_ops[i] * 32 * 32 for i in range(len(layer_name_list))]) + extra_bitops * 32
extra_bitops *= (linear_act_bits * linear_weight_bits)
total_bitops += extra_bitops
total_bitops = sum([bit_ops[i] * weight_bits[i] * act_bits[i]
for i in range(len(weight_bits))]) + extra_bitops
print('FP model BitOps (GB)',round(fp_bitops/GBITOPS, 3))
print('quantized model BitOps (GB)',round(total_bitops/GBITOPS, 3))
print('bitops radio (fp_bitops/target_bitops)', round(fp_bitops/total_bitops, 3))
print("*"*80)
3. 目录结构与其他代码
目录结构:
model.py:
import torchvision.models as models
import torch.nn as nn
from collections import OrderedDict
class MobileNetV1(nn.Module):
def __init__(self):
super(MobileNetV1, self).__init__()
def conv_bn(inp, oup, stride):
return nn.Sequential(
nn.Conv2d(inp, oup, 3, stride, 1, bias=False),
nn.BatchNorm2d(oup),
nn.ReLU(inplace=True)
)
def conv_dw(inp, oup, stride):
dw_conv = nn.Sequential(
OrderedDict([
('conv', nn.Conv2d(inp, inp, 3, stride, 1, groups=inp, bias=False)),
('bn', nn.BatchNorm2d(inp)),
('relu', nn.ReLU(inplace=True))
]))
pw_conv = nn.Sequential(
OrderedDict([
('conv', nn.Conv2d(inp, oup, 1, 1, 0, bias=False)),
('bn', nn.BatchNorm2d(oup)),
('relu', nn.ReLU(inplace=True))
]))
return nn.Sequential(OrderedDict(
[('dw_conv', dw_conv),
('pw_conv', pw_conv),
]
))
self.first_conv = conv_bn(3, 32, 2)
channels = [64, 128, 256, 512, 1024]
depths = [1, 2, 2, 6, 2]
strides = [1, 2, 2, 2, 2]
in_channel = 32
features = []
for stage_id, (depth, channel, stride) in enumerate(zip(depths, channels, strides)):
ops = []
first_layer = conv_dw(inp=in_channel, oup=channel, stride=stride)
ops.append(('unit1', first_layer))
print(in_channel, channel)
in_channel = channel
for layer_id in range(1, depth):
ops.append((f'unit{
layer_id+1}', conv_dw(inp=in_channel, oup=channel, stride=stride)))
print(in_channel, channel)
features.append((f'stage{
stage_id+1}', nn.Sequential(OrderedDict(ops))))
self.features = nn.Sequential(OrderedDict(features))
self.fc = nn.Linear(1024, 1000)
def forward(self, x):
x = self.first_conv(x)
x = self.features(x)
x = x.view(-1, 1024)
x = self.fc(x)
return x
def get_model(name):
if name == 'resnet50':
return models.resnet50()
elif name == 'resnet18':
return models.resnet18()
elif name == 'mobilenetv1':
return MobileNetV1()
else:
raise NotImplementedError
4. 量化策略
量化策略为网络每一层分配权重位宽和激活位宽,例如本文:
weight_bits=[6, 3, 4, 5, 4, 4, 5, 4, 4, 5, 4, 3, 4, 3, 3, 3, 4, 4,3, 4, 4, 3, 4, 3, 2, 3, 2, 3, 2, 3, 3, 2, 2, 3, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2]
act_bits=[6, 4, 6, 6, 6, 3, 4, 6, 3, 4, 5, 3, 5, 5, 6, 3, 4, 5, 3, 4, 5, 3, 4, 4, 4, 6, 5, 5, 4, 5, 5, 4, 6, 5, 3, 5, 6, 3, 5, 6, 3, 6, 4, 4, 6, 2, 6, 4, 6, 6, 4, 6]
weight_bits共包含52个元素,对应ResNet50的52个参数层。weight_bits[0]表示第1个参数层的权重位宽,act_bits[0]表示第1个参数层的激活位宽。
结束
-
本文实现了仅输入模型名称与量化策略,输出BitOps与模型参数规模;
-
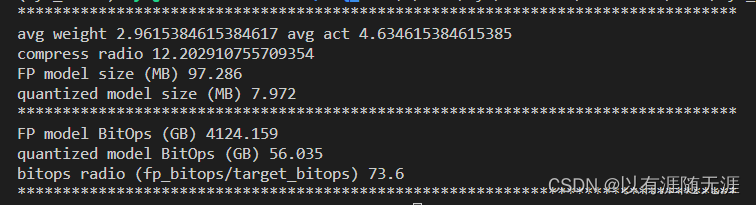
输出样例:
-
下一步将更新混合精度量化模型的推理。
本人目前希望提升自己的博客撰写水平,如读者在实现过程中遇到困难,或在阅读本文时感到困惑,欢迎留言或添加我的QQ:1106295085。我将在周日下午回复,并积极修改本文。