混合精度是如何加速大模型训练的?
基础知识回顾
float-32
在深度学习中,通常使用float-32 精度的数值训练模型,其中pytorch默认的也是float-32。
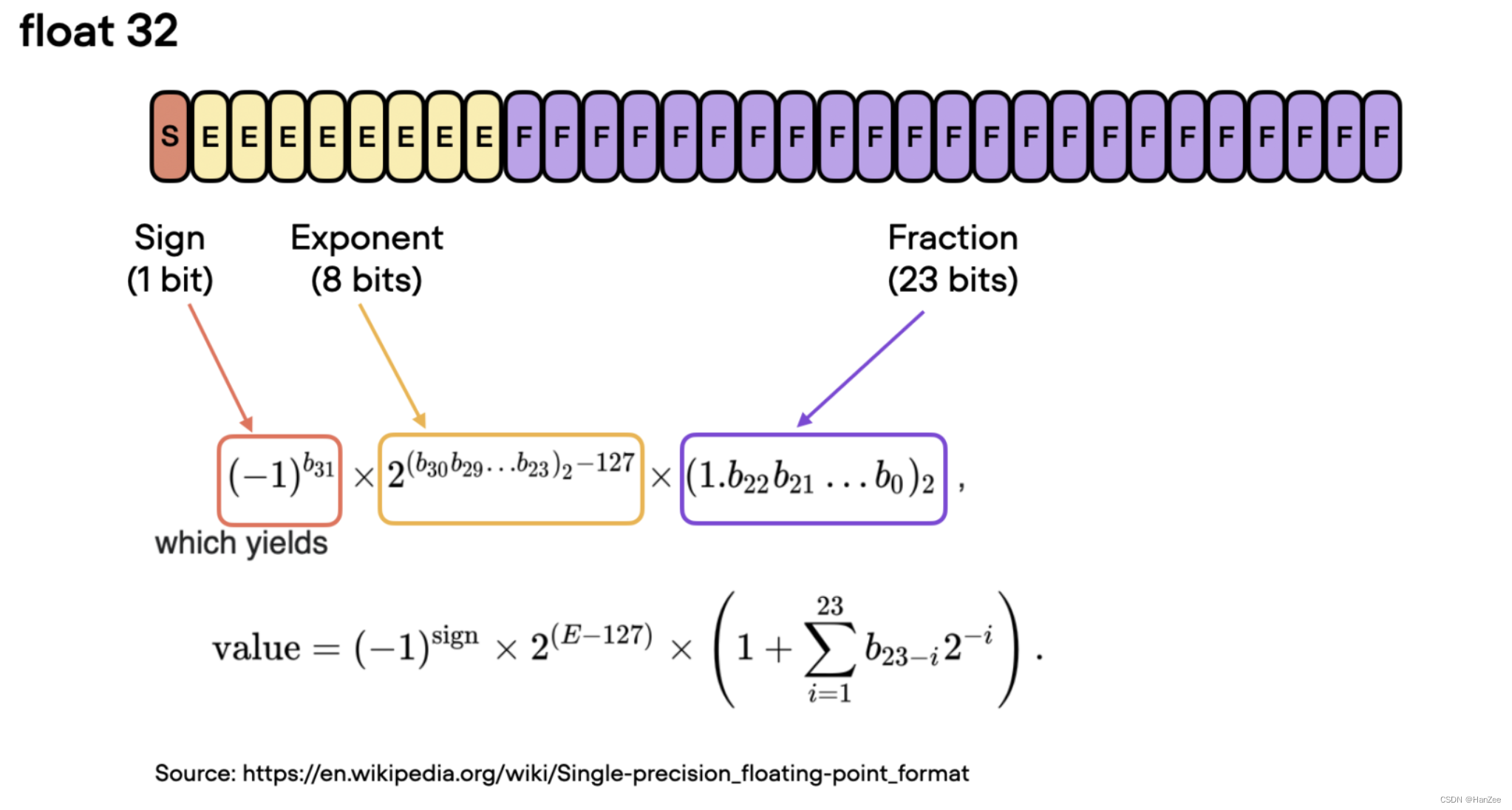
float32,也就是32位单精度浮点数,表示一个浮点数需要使用32位二进制数来表示。其中,这32位按照特定的规则分为了不同的部分,用于表示符号、指数和尾数,具体如下:
- 符号位(sign bit):占用1个二进制位(bit),用于表示该浮点数的正负性,0表示正数,1表示负数。
- 指数位(exponent bit):占用8个二进制位(bit),用于表示指数部分,包括指数的符号和大小。
- 尾数位(mantissa bit):占用23个二进制位(bit),用于表示尾数部分,即小数部分。
根据IEEE 754标准,32位单精度浮点数的格式为S EEEEEEEE MMMMMMMMMMMMMMMMMMMMM,其中S表示符号位,EEEEEEEE表示指数位,MMMMMMMMMMMMMMMMMMMMMM表示尾数位。这种格式的表示范围是从约-3.4×1038到约3.4×1038之间的浮点数,并且精度达到6-7位有效数字。
计算方式如下:
在通常的科学计算中,都是以float-64精度(也就是double)计算的,它用来表示数值的位数更多,精度更大,损失更小,在深度学习中为什么我们很少用float-64而是去采用?
- 因为使用float32,可以节省更多的内存,可以设置更大的batchsize。
- 模型训练速度更快,更快的得到实验结果。
从float-32 到float-16
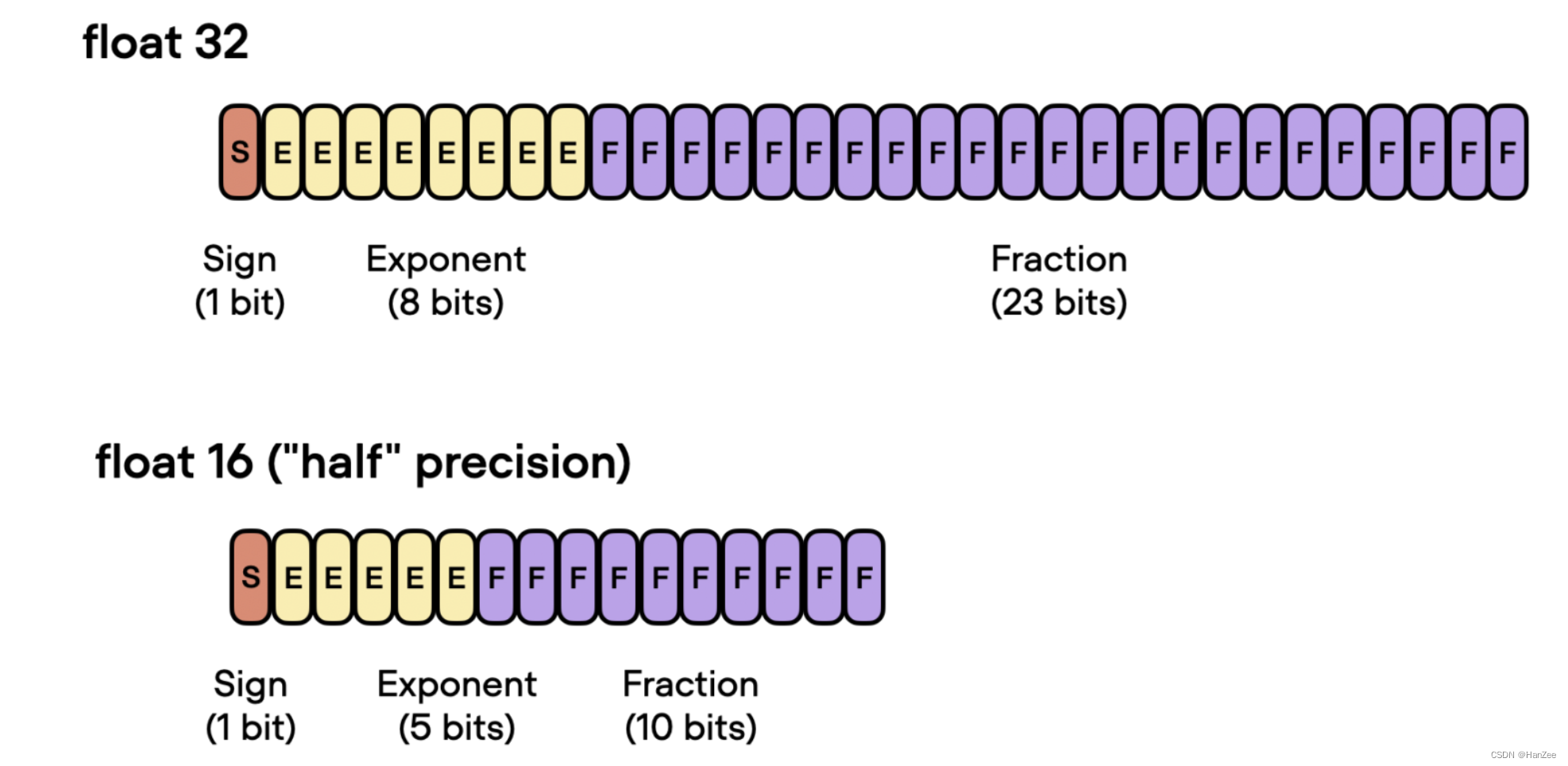
下面是各个精度的对比:
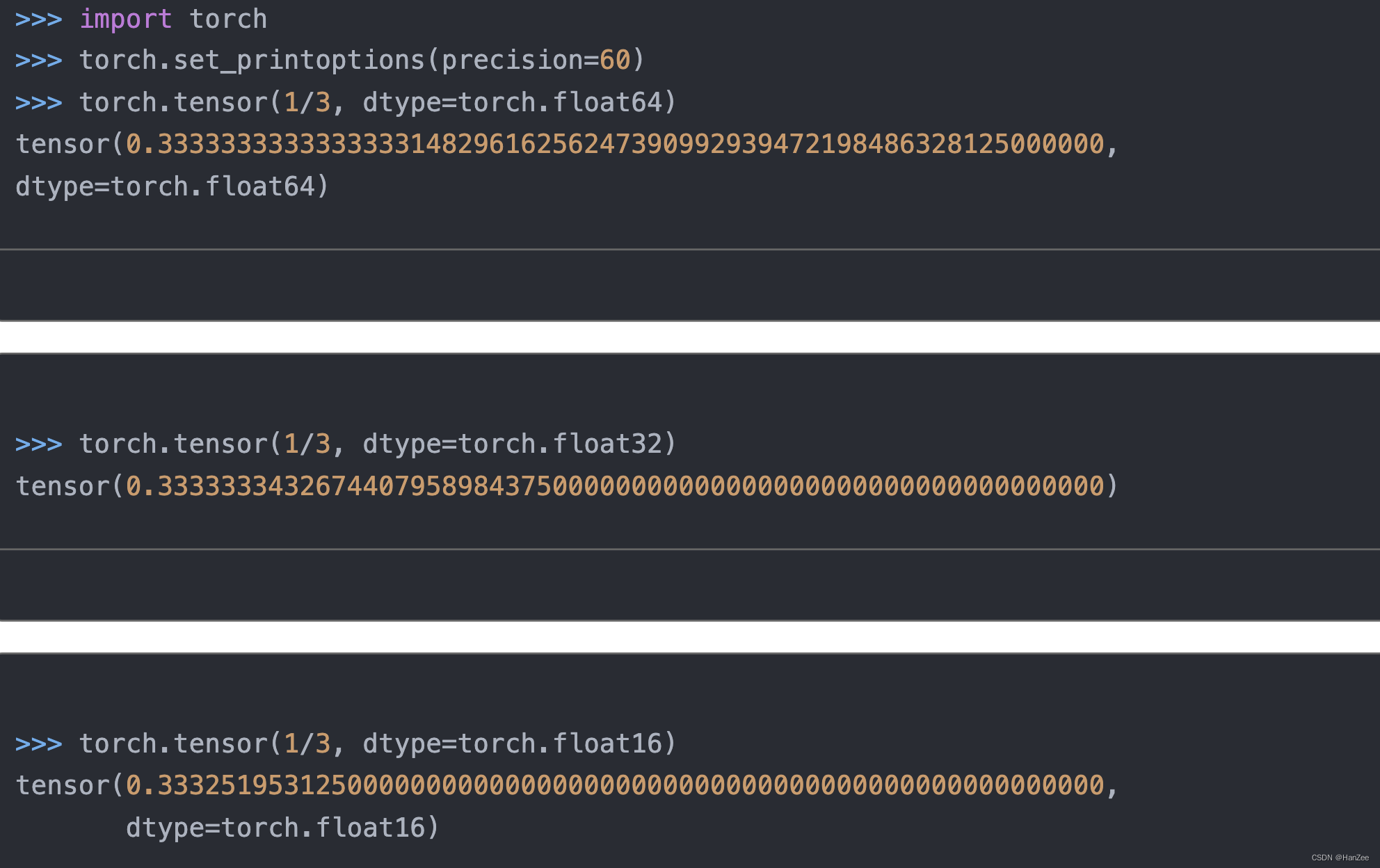
在训练中,我们从float-64到float32往往不会造成很大的损失,但是当我们从32转到16位,就会造成训练不稳定,无法收敛。主要是由于数值精度不够,造成了数值的上溢或者下溢。
具体如下所示:
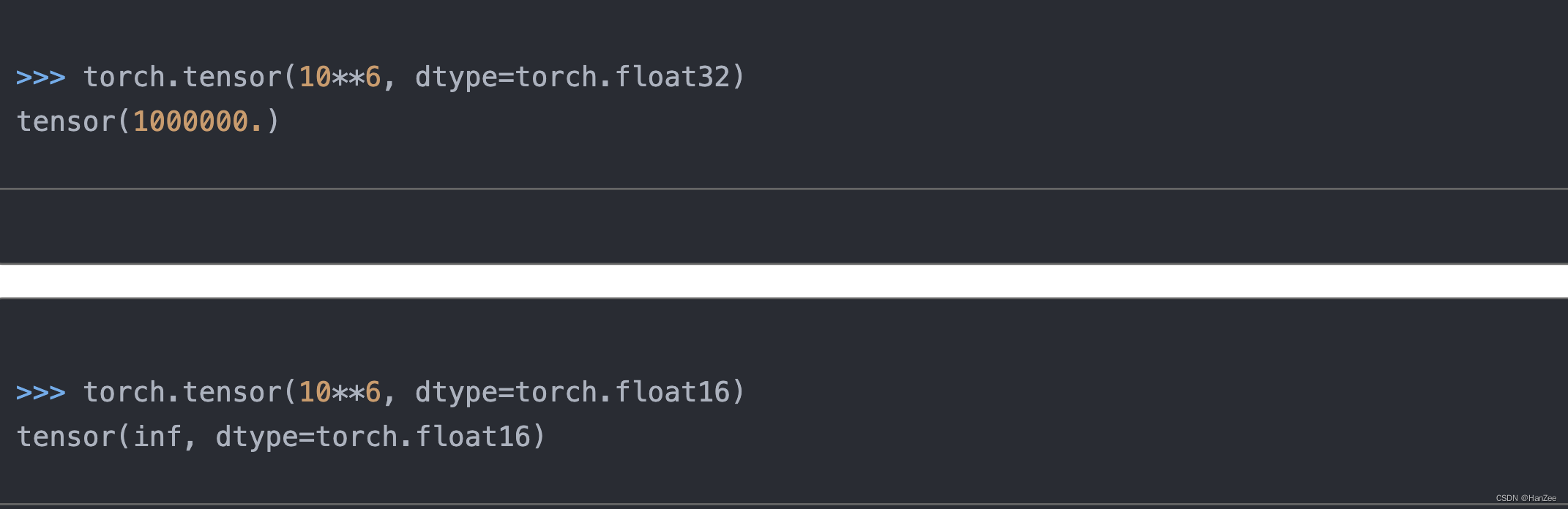
32为的最大数值是:340,282,000,000,000,000,000,000,000,000,000,000,000
16位则是:
65504
混合精度计算
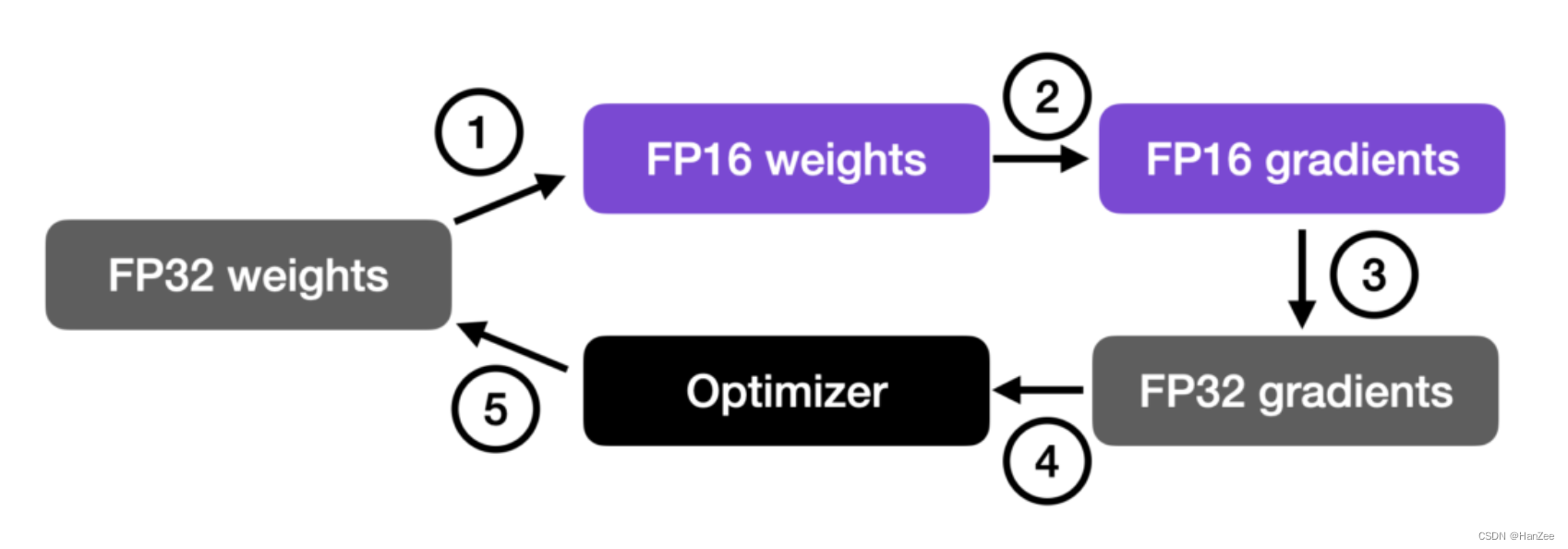
- 首先把32位参数转化为16位,进行forward pass然后计算各个参数对loss的gradients。
- 通过16位 weight得到16位的gradients。
- 然后把16位的gradients转换成32位。
- 把32位gradients与lr相乘得到移动的步伐
- 32位原始参数-步伐得到新的32位参数。
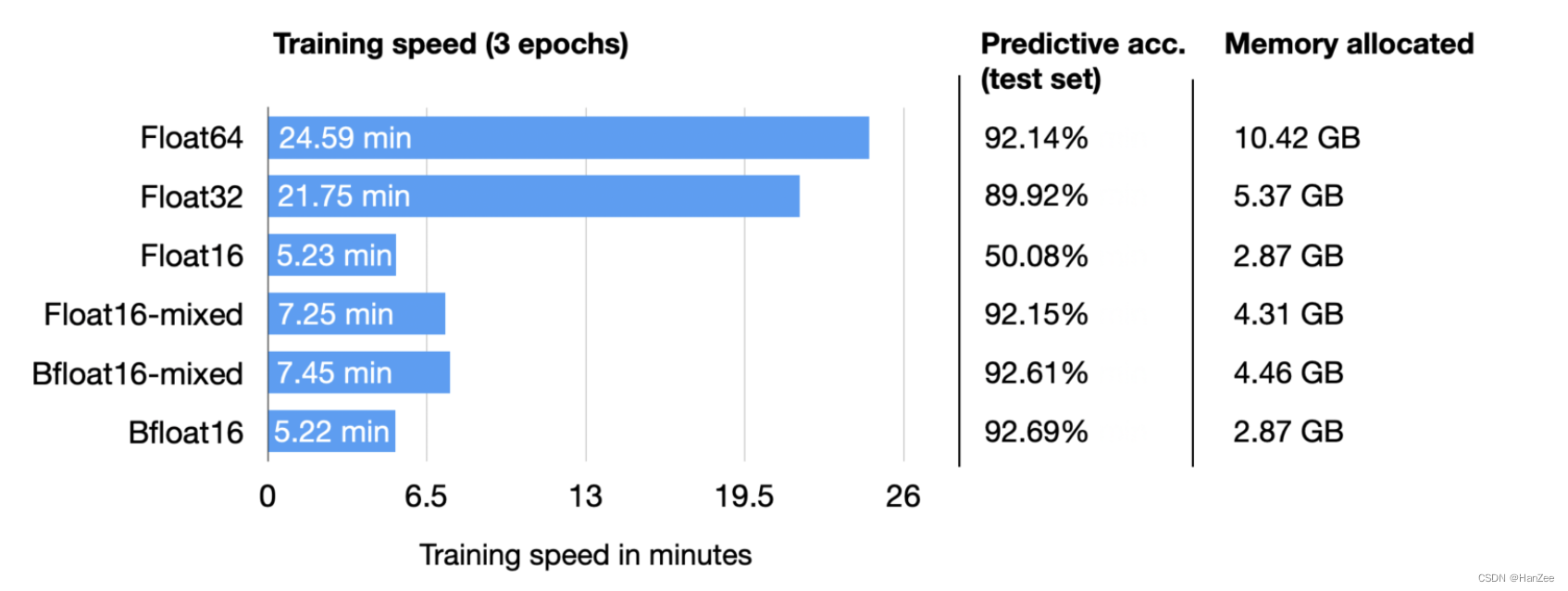
实验
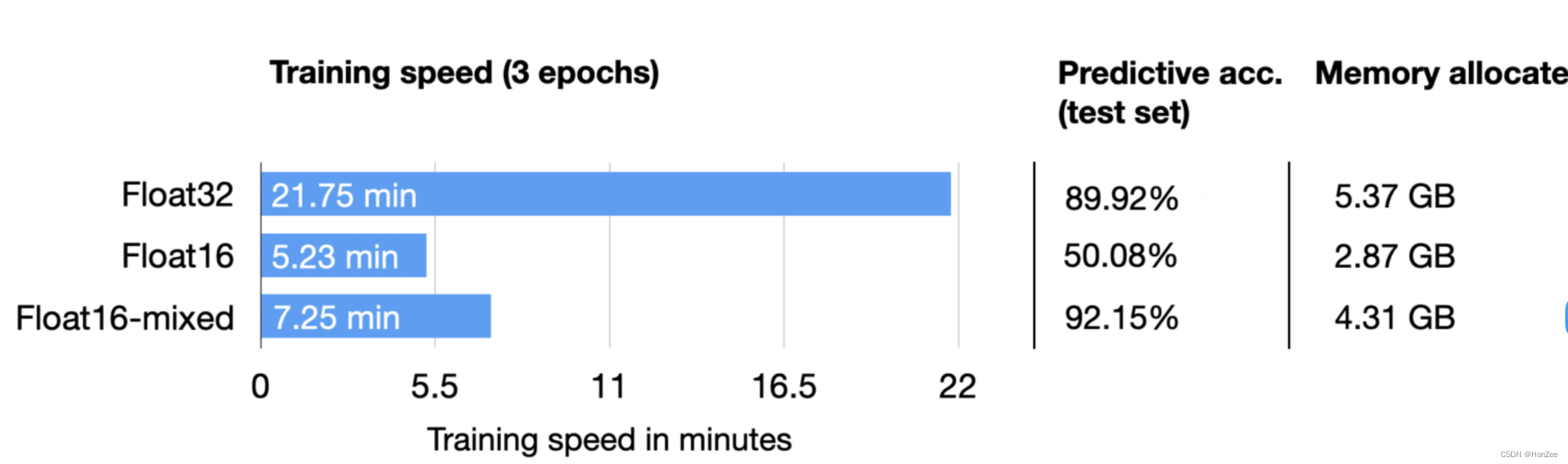
这里我们发现,混合精度的在测试集上面的表现要比32还高,原因可能与batch小一点是一个道理,引入了一些误差,起到了正则化的效果。
bfloat16
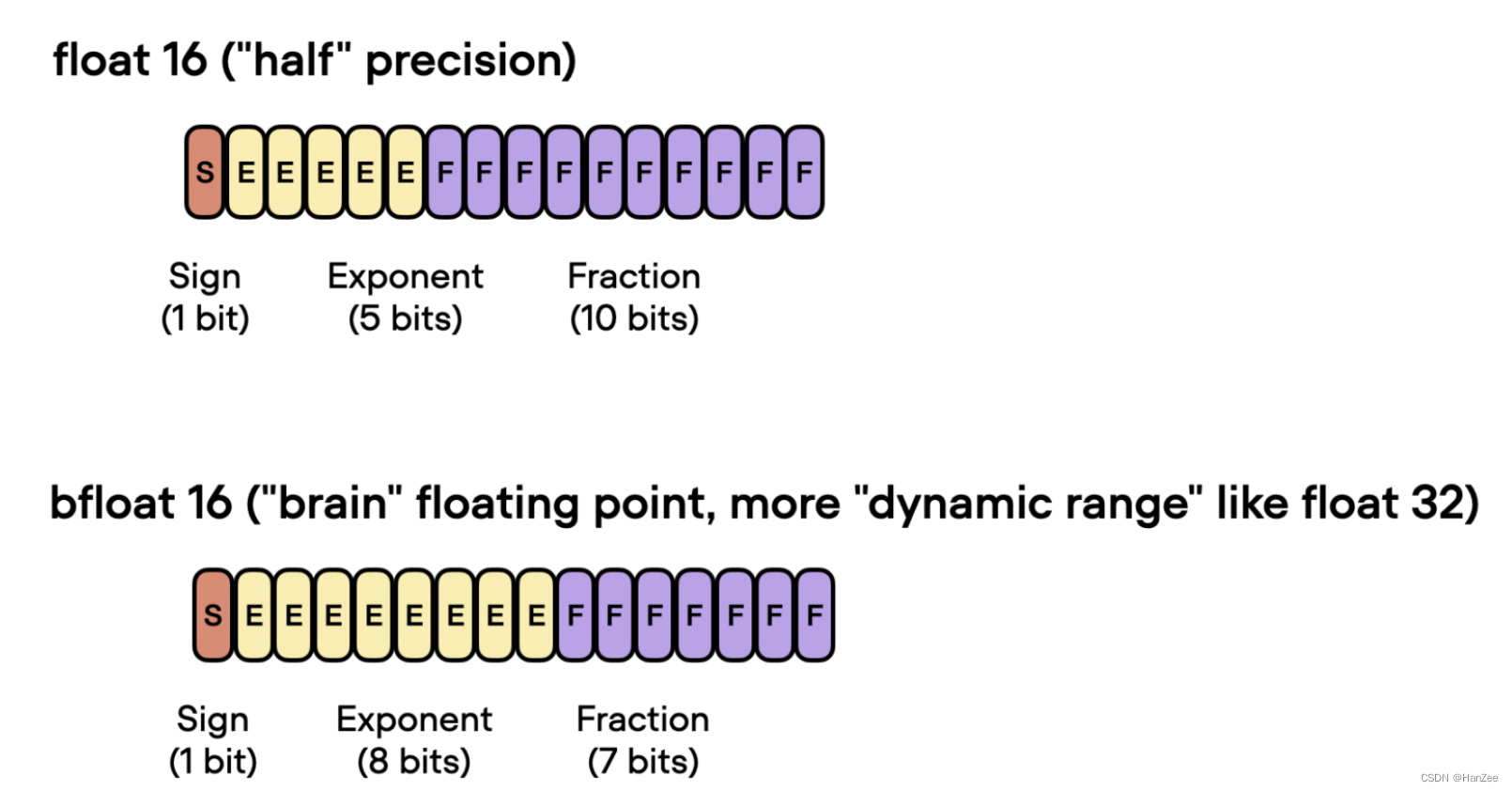
与传统float16格式相比,Bfloat16扩展了动态范围,但代价是降低了精度。
扩展的动态范围帮助bfloat16表示非常大和非常小的数字,使其更适合可能遇到大范围值的深度学习应用程序。但是,较低的精度可能会影响某些计算的准确性,或者在某些情况下导致舍入误差。但在大多数深度学习应用中,这种降低的精度对建模性能的影响微乎其微。
虽然bfloat16最初是为tpu开发的,但这种格式现在也被一些NVIDIA gpu所支持,从NV的一部分A100 Tensor Core gpu开始.
实验: