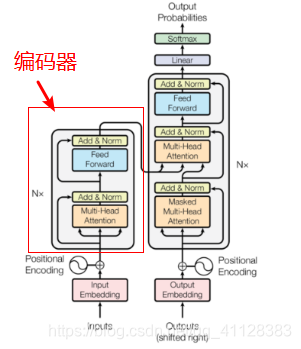
Transformer编码器部分
由N个编码器组成,每一个编码器有两个子层连接,一个是多头自注意力,规范化层及残差单元,另一个是前馈层,规范化层级残差单元
结构图如下
编码器中注意力下计算规则
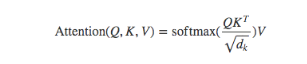
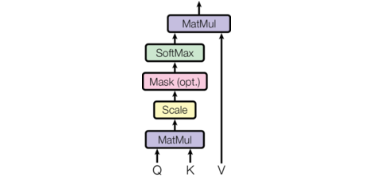
注意力机制结构图:
注意力机制代码实现
def attion(query,key,value,mask=None,dropout=None):
d_value=query.size()[-1]
scores=torch.matmul(query,key.transpose(-2,-1))/math.sqrt(d_value)
if mask is not None:
scores=scores.masked_fill(mask==0,-1e9)
p_attn=F.softmax(scores,dim=-1)
if dropout is not None:
p_attn=dropout(p_att)
return torch.matmul(p_attn,value),p_attn
query=key=value=pe_result
attn,p_attn=attion(query,key,value)
print(attn)
前馈全连接层:在Transformer中前馈全连接层就是具有两层线性层的全连接网络
前馈全连接层代码实现
import torch
import torch.nn as nn
import torch.nn.functional as F
class FeedForward(nn.Module):
def __init__(self,dim_model,ff_dmodel,dropout):
super().__init_()
self.f1=nn.Linear(dim_model,ff_model)
self.f2=nn.Linear(ff_model,dim_model)
self.dropout=nn.Dropout(p=dropout)
def forward(self,inp):
retun self.f2(self.dropout(F.relu(self.f1(input))))
规范层代码实现
class LayerNorm(nn.Module):
def __init__(self,size,eps=1e-6):
super().__init__()
self.a1=nn.Parameter(torch.ones(model_dim))
self.b1=nn.Parameter(torch.zeros(size))
self.eps=eps
def forward(self,input):
mean=input.mean(-1,keepdim=True)
std=input.std(-1,keepdim=True)
return self.a1*(input-mean)/(std+self.eps) +self.b1
子层连接结构:每个编码器层中,都有两个子层,输入到每个子层以及规范化层的过程中,使用了残差链接
class SublayerConnection(nn.Module):
def __init__(self,size,dropout):
super().__init__()
self.norm=LayerNorm(size)
self.dropout=nn.Dropout(p=dropout)
def forward(self,input,sublayer):
return input+self.dropout(sublayer(self.norm(input)))
self_attn=MultiHeadedAttention(head,d_model)
sublayer=lambda x:self_attn(input,input,input,mask)
sc=SublayerConnection(size,dropout)
sc_result=sc(input,sublayer)
编码器层: 作为编码器的组成单元, 每个编码器层完成一次对输入的特征提取过程, 即编码过程
class EncoderLayer(nn.Module):
def __init__(self,size,attn,feed_forward,dropout):
super().__init__()
self.size=size
self.attn=attn
self.feed_forward=feed_forward
self.sublayer=clones(SublayerConnection(size,dropout),2)
def forward(self,input,mask):
input=self.sublayer[0](input,lambda input:self.attn(input,input,input,mask)
return self.sublayer[1](input,self.feed_forward)
编码器:用于对输入进行指定的特征提取过程, 也称为编码, 由N个编码器层堆叠而成
class Encoder(nn.Module):
def __init__(self,encoderlayer,N):
super().__init__()
self.layers=clones(EncoderLayer,N)
self.norm=LayerNorm(encoderlayer.size)
def forward(self,input,mask):
for layer in self.layers:
input=layer(input,mask)
return self.norm(input)
c=copy.deepcopy
attn=MultiHeadedAttention(head,dim_model)
fforward=FeedForward(dim_model,ff_model,dropout)
encoderlayer=Encoder(size,c(attn),c(fforward),dropout)
en=Encoder(encoderlayer,N)
output=en(input,mask)
