本小节将会介绍如何利用已经预训练好的卷积神经网络模型对一张图像进行预测,并且通过可视化的方法,查看模型是如何得到其预测结果的。
我们直接看一个实例,利用已经预训练好的VGG16卷积神经网络对一张图像获取一些特定层的输出,并将这些输出可视化,并观察VGG16对图像的特征提取情况。
import torch
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import requests
import cv2
from torch import nn
import torch.nn.functional as F
from torchvision import models
from torchvision import transforms
from PIL import Image
vgg16=models.vgg16(pretrained=True)
im=Image.open("C:\\Users\\zex\\Downloads\\Compressed\\validation\\validation\\n7\\n704.jpg")
imarray=np.asarray(im)/255.0
plt.figure()
plt.imshow(imarray)
plt.show()通过PIL库读取图像,并转化为Numpy数组后,使用matplotlib库进行可视化,得到的图像下图所示:

图像输入VGG16模型之前,需要对该图像进行预处理,将其处理为网络可接受的输入。
#将图像处理为VGG16可以处理的形式
data_transforms=transforms.Compose([
transforms.Resize((224,224)),#重置图像分辨率
transforms.ToTensor(),#转化为张量并归一化至[0-1]
#图像标准化处理
transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])
])
input_im=data_transforms(im).unsqueeze(0)在获取图像的中间特征之前,先定义一个辅助函数get_activation,该函数可以更方便地获取、保存所需要的中间特征输出。
#定义一个辅助函数,获取指定层名称的特征
activation={}#保存不同层的输出
def get_activation(name):
def hook(model,input,output):
activation[name]=output.detach()
return hook下面我们获取vgg16网络中的第四层(也即经过第一次最大值池化后的特征映射)
#获取中间的卷积后的图像特征
vgg16.features[4].register_forward_hook(get_activation("maxpool1"))
_=vgg16(input_im)
maxpool1=activation["maxpool1"]
print(maxpool1.shape)
上面的程序通过钩子技术,即vgg16.features[4].register_forward_hook(),获取vgg16.features下的第四层向前输出结果,并将结果保存在字典activation下maxpool1所对应的结果。从输出中可知一张图像获取了64个112×112的特征映射,将特征映射可视化的程序及结果如下所示
plt.figure(figsize=(11,6))
for i in range(maxpool1.shape[1]):
plt.subplot(6,11,i+1)
plt.imshow(maxpool1.data.numpy()[0,i,:,:],cmap="gray")
plt.axis("off")
plt.subplots_adjust(wspace=0.1,hspace=0.1)
plt.show()

从上图的结果发现,很多特征映射都能分辨出原始图形所包含的内容,反映了网络中的较浅层能够获取图像的较大粒度的特征。接下来将获取更深层次的特征映射,获取vgg16.features[21]层的输出,程序及可视化结果如下:
vgg16.eval()
vgg16.features[21].register_forward_hook(get_activation("layer21_conv"))
_=vgg16(input_im)
layer21_conv=activation["layer21_conv"]
print(layer21_conv.shape)
plt.figure(figsize=(12,6))
for i in range(72):
plt.subplot(6,12,i+1)
plt.imshow(layer21_conv.data.numpy()[0,i,:,:],cmap="gray")
plt.axis("off")
plt.subplots_adjust(hspace=0.1,wspace=0.1)
plt.show()


从上图可以发现更深层次的映射已经不能分辨出图像的具体内容,说明更深的特征映射能从图像中提取更细粒度的特征。
针对已经预训练好的卷积神经网络,导入模型后,可以直接使用该模型对图像数据进行预测,输出图像所对应的类别。下图所对应的json文件中包含着ImageNet图像用于图像分类的1000个类别标签,这也是PyTorch中预训练模型所对应的类别标签。
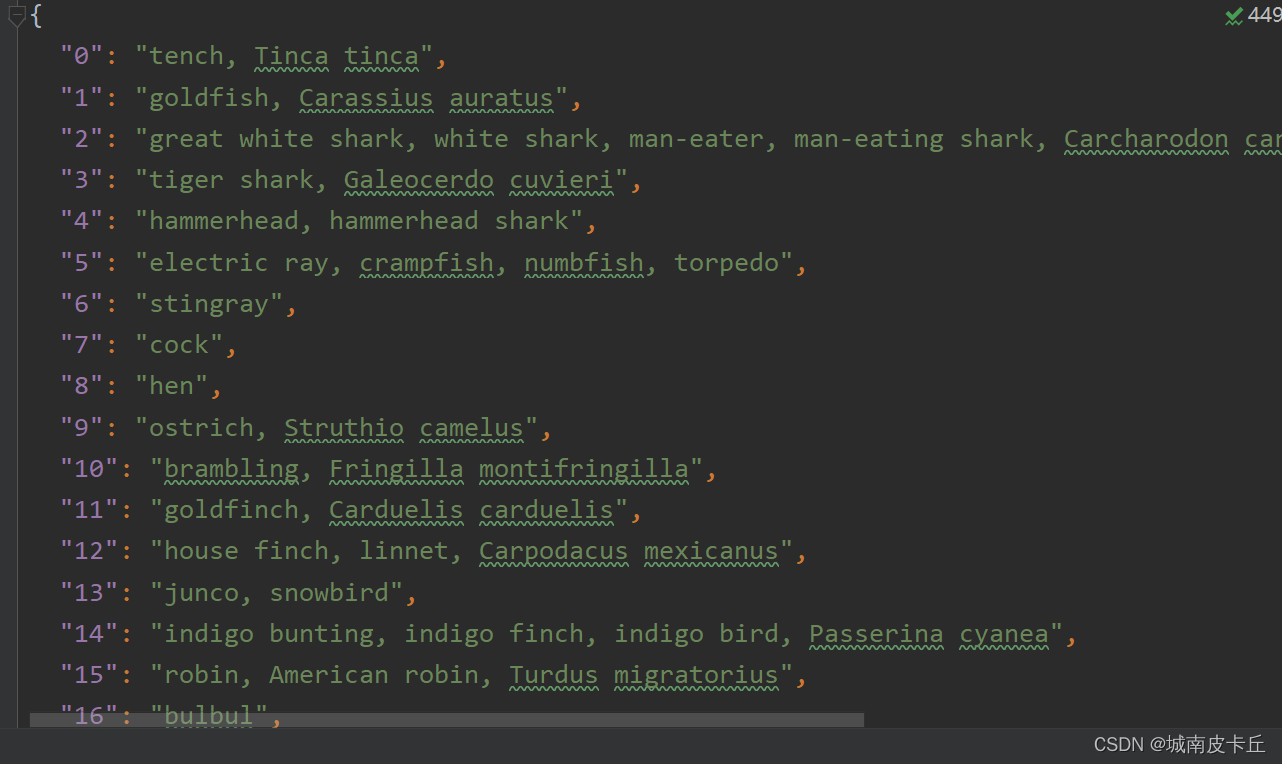
下面将使用预训练好的VGG16网络,对图片进行预测。在进行预测之前,首先需要读取VGG16模型对应的1000个标签,并将其预处理。
import json
jsonfile = r'E:\PythonWorkSpace\pytorch_project\pytorch_demo\Dataset\my_labels.json'
with open(jsonfile, 'r') as load_f:
load_json = json.load(load_f)
labels = {int(key): value for (key, value) in load_json.items()}
接下来导入vgg16网络模型对图像进行预测。
vgg16.eval()
im_pre=vgg16(input_im)
softmax=nn.Softmax(dim=1)
im_pre_prob=softmax(im_pre)
prob,prelab=torch.topk(im_pre_prob,5)
prob=prob.data.numpy().flatten()
prelab=prelab.numpy().flatten()
for i,lab in enumerate(prelab):
print("index:",lab,"label:",labels[lab],"||",prob[i])上面的程序输出了预测可能性最大的前5个类别,得到的结果如下所示:
index: 382 label: squirrel monkey, Saimiri sciureus || 0.56855154
index: 380 label: titi, titi monkey || 0.36315396
index: 381 label: spider monkey, Ateles geoffroyi || 0.06263459
index: 384 label: indri, indris, Indri indri, Indri brevicaudatus || 0.0024695916
index: 371 label: patas, hussar monkey, Erythrocebus patas || 0.0021503093
在预测结果中,预测概率最大的是第382类squirrel monkey可能性为56.85%,其次是380类titi monkey 可能性为6.26%。
以上案例的完整代码:
import torch
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import requests
import cv2
from torch import nn
import torch.nn.functional as F
from torchvision import models
from torchvision import transforms
from PIL import Image
vgg16=models.vgg16(pretrained=True)
im=Image.open("C:\\Users\\zex\\Downloads\\Compressed\\validation\\validation\\n7\\n704.jpg")
imarray=np.asarray(im)/255.0
plt.figure()
plt.imshow(imarray)
plt.show()
#将图像处理为VGG16可以处理的形式
data_transforms=transforms.Compose([
transforms.Resize((224,224)),#重置图像分辨率
transforms.ToTensor(),#转化为张量并归一化至[0-1]
#图像标准化处理
transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])
])
input_im=data_transforms(im).unsqueeze(0)
#定义一个辅助函数,获取指定层名称的特征
activation={}#保存不同层的输出
def get_activation(name):
def hook(model,input,output):
activation[name]=output.detach()
return hook
#获取中间的卷积后的图像特征
# vgg16.features[4].register_forward_hook(get_activation("maxpool1"))
# _=vgg16(input_im)
# maxpool1=activation["maxpool1"]
# print(maxpool1.shape)
#
# plt.figure(figsize=(11,6))
# for i in range(maxpool1.shape[1]):
# plt.subplot(6,11,i+1)
# plt.imshow(maxpool1.data.numpy()[0,i,:,:],cmap="gray")
# plt.axis("off")
# plt.subplots_adjust(wspace=0.1,hspace=0.1)
# plt.show()
vgg16.eval()
vgg16.features[21].register_forward_hook(get_activation("layer21_conv"))
_=vgg16(input_im)
layer21_conv=activation["layer21_conv"]
print(layer21_conv.shape)
plt.figure(figsize=(12,6))
for i in range(72):
plt.subplot(6,12,i+1)
plt.imshow(layer21_conv.data.numpy()[0,i,:,:],cmap="gray")
plt.axis("off")
plt.subplots_adjust(hspace=0.1,wspace=0.1)
plt.show()
import json
jsonfile = r'E:\PythonWorkSpace\pytorch_project\pytorch_demo\Dataset\my_labels.json'
with open(jsonfile, 'r') as load_f:
load_json = json.load(load_f)
labels = {int(key): value for (key, value) in load_json.items()}
vgg16.eval()
im_pre=vgg16(input_im)
softmax=nn.Softmax(dim=1)
im_pre_prob=softmax(im_pre)
prob,prelab=torch.topk(im_pre_prob,5)
prob=prob.data.numpy().flatten()
prelab=prelab.numpy().flatten()
for i,lab in enumerate(prelab):
print("index:",lab,"label:",labels[lab],"||",prob[i])
针对一幅图像使用已经预训练好的深度学习网络,为了便于观察图像中哪些位置的内容对分类结果影响较大,可以输出图像的类激活热力图。计算图像类激活热力图数据,可以使用卷积神经网络中最后一层网络输出和其对应的梯度,但需要先定义一个新的网络,并且输出网络的卷积核梯度。
import torch
import torch.nn as nn
import torchvision.models
class MyVGG16Net(nn.Module):
def __init__(self):
super(MyVGG16Net, self).__init__()
#使用预训练好的vgg16模型
self.vgg=models.vgg16(pretrained=True)
#切分vgg16模型,便于获取卷积层的输出
self.features_conv=self.vgg.features[:30]
#使用Vgg原始的最大池化层
self.max_pool=self.vgg.features[30]
self.avgpool=self.vgg.avgpool
#使用vgg16的分类层
self.classifier=self.vgg.classifier
#生成梯度占位符
self.gradients=None
#定义获取梯度的钩子函数
def activations_hook(self,grad):
self.gradients=grad
def forward(self,x):
x=self.features_conv(x)
#注册钩子函数
h=x.register_hook(self.activations_hook)
#对卷积后的输出使用最大池化层
x=self.max_pool(x)
x=self.avgpool(x)
x=x.view((1,-1))
x=self.classifier(x)
return x
#定义获取梯度的方法
def get_activations_gradient(self):
return self.gradients
#定义获取卷积层输出的方法
def get_activations(self,x):
return self.features_conv(x)
上面的程序定义了一个新的函数类MyVGG16Net,其使用预训练好的VGC16网络为基础,用于获取图像在全连接层前的特征映射和对应的梯度信息。在类MyVGG16Net中定义activations_hook()函数来辅助获取图像在对应层的梯度信息,并定义get_activations_gradient()方法来获取梯度。在forward()函数中,使用x.register_hook()注册一个钩子,保存最后一层的特征映射的梯度信息,并使用get_activations()方法获取特征映射的输出。
接下来使用定义好的函数类初始化一个新的卷积神经网络vggcam,并对一张老虎图像进行预测。
class MyVGG16Net(nn.Module):
def __init__(self):
super(MyVGG16Net, self).__init__()
#使用预训练好的vgg16模型
self.vgg=models.vgg16(pretrained=True)
#切分vgg16模型,便于获取卷积层的输出
self.features_conv=self.vgg.features[:30]
#使用Vgg原始的最大池化层
self.max_pool=self.vgg.features[30]
self.avgpool=self.vgg.avgpool
#使用vgg16的分类层
self.classifier=self.vgg.classifier
#生成梯度占位符
self.gradients=None
#定义获取梯度的钩子函数
def activations_hook(self,grad):
self.gradients=grad
def forward(self,x):
x=self.features_conv(x)
#注册钩子函数
h=x.register_hook(self.activations_hook)
#对卷积后的输出使用最大池化层
x=self.max_pool(x)
x=self.avgpool(x)
x=x.view((1,-1))
x=self.classifier(x)
return x
#定义获取梯度的方法
def get_activations_gradient(self):
return self.gradients
#定义获取卷积层输出的方法
def get_activations(self,x):
return self.features_conv(x)
im=Image.open("C:\\Users\\zex\\Desktop\\tiger.jpg")#一张老虎图片
#将图像处理为VGG16可以处理的形式
data_transforms=transforms.Compose([
transforms.Resize((224,224)),#重置图像分辨率
transforms.ToTensor(),#转化为张量并归一化至[0-1]
#图像标准化处理
transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])
])
input_im=data_transforms(im).unsqueeze(0)
vggcam=MyVGG16Net()
vggcam.eval()
im_pre=vggcam(input_im)
softmax=nn.Softmax(dim=1)
im_pre_prob=softmax(im_pre)
prob,prelab=torch.topk(im_pre_prob,5)
prob=prob.data.numpy().flatten()
prelab=prelab.numpy().flatten()
#读取ImageNet数据集1000类别json文件
jsonfile = r'E:\PythonWorkSpace\pytorch_project\pytorch_demo\Dataset\my_labels.json'
with open(jsonfile, 'r') as load_f:
load_json = json.load(load_f)
labels = {int(key): value for (key, value) in load_json.items()}
for i,lab in enumerate(prelab):
print("index:",lab,"label:",labels[lab],"||",prob[i])网络预测结果如下:
index: 292 label: tiger, Panthera tigris || 0.6837202
index: 282 label: tiger cat || 0.22213535
index: 133 label: bittern || 0.04011252
index: 340 label: zebra || 0.020502226
index: 290 label: jaguar, panther, Panthera onca, Felis onca || 0.013023969
下面开始计算所需要的特征映射与梯度信息
上面的程序在使用vggcam.get_activations_gradient()方法获取梯度信息gradients后,将每个通道的梯度信息计算均值,然后将特征映射的每个通道乘以相应的梯度均值,在经过ReLU函数运算后即可得到类激活热力图的取值heatmap,将heatmap的取值处理到0~1之间,即可对其进行可视化,得到如下图所示的类激活热力图。
#获取相对于模型参数的输出梯度
im_pre[:,prelab[0]].backward()
#获取模型的梯度
gradients=vggcam.get_activations_gradient()
#计算梯度相应通道的均值
mean_gradients=torch.mean(gradients,dim=[0,2,3])
#获取图像在相应卷积层输出的卷积特征
activations=vggcam.get_activations(input_im).detach()
#每个通道乘以相应的梯度均值
for i in range(len(mean_gradients)):
activations[:,i,:,:] *=mean_gradients[i]
#计算所有通道的均值输出得到的热力图
heatmap=torch.mean(activations,dim=1).squeeze()
#使用relu函数作用于热力图
heatmap=F.relu(heatmap)
#对热力图进行标准化
heatmap /=torch.max(heatmap)
heatmap=heatmap.numpy()
#可视化热力图
plt.matshow(heatmap)
plt.show()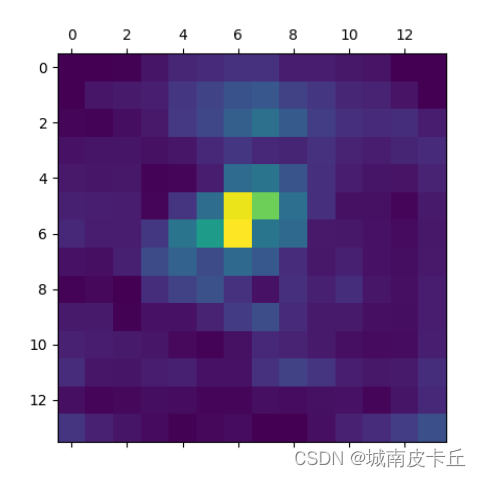
直接观察图像的类激活热力图,并不能很好地反应原始图像中哪些地方的内容对图像的分类结果影响更大。所以针对获得的类激活热力图可以将其和原始图像融合,更方便观察图像中对分类结果影响更大的图像内容。
import cv2
import numpy as np
#将CAM热力图融合到原始图像上去
img=cv2.imread("C:\\Users\\zex\\Desktop\\tiger.jpg")
heatmap=cv2.resize(heatmap,(img.shape[1],img.shape[0]))
heatmap=np.uint8(255 * heatmap)
heatmap=cv2.applyColorMap(heatmap,cv2.COLORMAP_JET)
Grad_cam_img=heatmap *0.4 +img
Grad_cam_img=Grad_cam_img / Grad_cam_img.max()
#可视化图像
b,g,r=cv2.split(Grad_cam_img)
Grad_cam_img=cv2.merge([r,g,b])
plt.figure()
plt.imshow(Grad_cam_img)
plt.show()
上图显示了预测结果响应的主要位置,图像中老虎身体中间部位的内容对预测的结果影响更大
本案例的完整代码如下:
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torchvision.models as models
from torchvision import transforms
from PIL import Image
import json
import torch.nn.functional as F
import matplotlib.pyplot as plt
class MyVGG16Net(nn.Module):
def __init__(self):
super(MyVGG16Net, self).__init__()
#使用预训练好的vgg16模型
self.vgg=models.vgg16(pretrained=True)
#切分vgg16模型,便于获取卷积层的输出
self.features_conv=self.vgg.features[:30]
#使用Vgg原始的最大池化层
self.max_pool=self.vgg.features[30]
self.avgpool=self.vgg.avgpool
#使用vgg16的分类层
self.classifier=self.vgg.classifier
#生成梯度占位符
self.gradients=None
#定义获取梯度的钩子函数
def activations_hook(self,grad):
self.gradients=grad
def forward(self,x):
x=self.features_conv(x)
#注册钩子函数
h=x.register_hook(self.activations_hook)
#对卷积后的输出使用最大池化层
x=self.max_pool(x)
x=self.avgpool(x)
x=x.view((1,-1))
x=self.classifier(x)
return x
#定义获取梯度的方法
def get_activations_gradient(self):
return self.gradients
#定义获取卷积层输出的方法
def get_activations(self,x):
return self.features_conv(x)
im=Image.open("C:\\Users\\zex\\Desktop\\tiger.jpg")
#将图像处理为VGG16可以处理的形式
data_transforms=transforms.Compose([
transforms.Resize((224,224)),#重置图像分辨率
transforms.ToTensor(),#转化为张量并归一化至[0-1]
#图像标准化处理
transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])
])
input_im=data_transforms(im).unsqueeze(0)
vggcam=MyVGG16Net()
vggcam.eval()
im_pre=vggcam(input_im)
softmax=nn.Softmax(dim=1)
im_pre_prob=softmax(im_pre)
prob,prelab=torch.topk(im_pre_prob,5)
prob=prob.data.numpy().flatten()
prelab=prelab.numpy().flatten()
jsonfile = r'E:\PythonWorkSpace\pytorch_project\pytorch_demo\Dataset\my_labels.json'
with open(jsonfile, 'r') as load_f:
load_json = json.load(load_f)
labels = {int(key): value for (key, value) in load_json.items()}
for i,lab in enumerate(prelab):
print("index:",lab,"label:",labels[lab],"||",prob[i])
#获取相对于模型参数的输出梯度
im_pre[:,prelab[0]].backward()
#获取模型的梯度
gradients=vggcam.get_activations_gradient()
#计算梯度相应通道的均值
mean_gradients=torch.mean(gradients,dim=[0,2,3])
#获取图像在相应卷积层输出的卷积特征
activations=vggcam.get_activations(input_im).detach()
#每个通道乘以相应的梯度均值
for i in range(len(mean_gradients)):
activations[:,i,:,:] *=mean_gradients[i]
#计算所有通道的均值输出得到的热力图
heatmap=torch.mean(activations,dim=1).squeeze()
#使用relu函数作用于热力图
heatmap=F.relu(heatmap)
#对热力图进行标准化
heatmap /=torch.max(heatmap)
heatmap=heatmap.numpy()
#可视化热力图
plt.matshow(heatmap)
plt.show()
import cv2
import numpy as np
#将CAM热力图融合到原始图像上去
img=cv2.imread("C:\\Users\\zex\\Desktop\\tiger.jpg")
heatmap=cv2.resize(heatmap,(img.shape[1],img.shape[0]))
heatmap=np.uint8(255 * heatmap)
heatmap=cv2.applyColorMap(heatmap,cv2.COLORMAP_JET)
Grad_cam_img=heatmap *0.4 +img
Grad_cam_img=Grad_cam_img / Grad_cam_img.max()
#可视化图像
b,g,r=cv2.split(Grad_cam_img)
Grad_cam_img=cv2.merge([r,g,b])
plt.figure()
plt.imshow(Grad_cam_img)
plt.show()