前言
文本生成旨在利用NLP技术,根据给定信息产生特定目标的文本序列,应用场景众多,并可以通过调整语料让相似的模型框架适应不同应用场景。本文重点围绕Encoder-Decoder结构,列举一些以文本摘要或QA系统文本生成为实验场景的技术进展。
Seq2Seq框架及其最新研究进展
Seq2Seq框架最初是解决机器翻译任务设计的算法架构,主要分成编码器和解码器两部分。编码器负责将源语言句子压缩为语义空间中的一个向量,期望该向量包含源语言句子的主要信息;另一部分解码器,它基于编码器提供的语义向量,产生语义上等价的目标语言句子。其本质是解决了多对多的映射任务。下面主要分别从模型构建的动机、预训练任务、微调和实验四个方面以对比的方式。
介绍两个比较具有前沿的模型BART和T5。
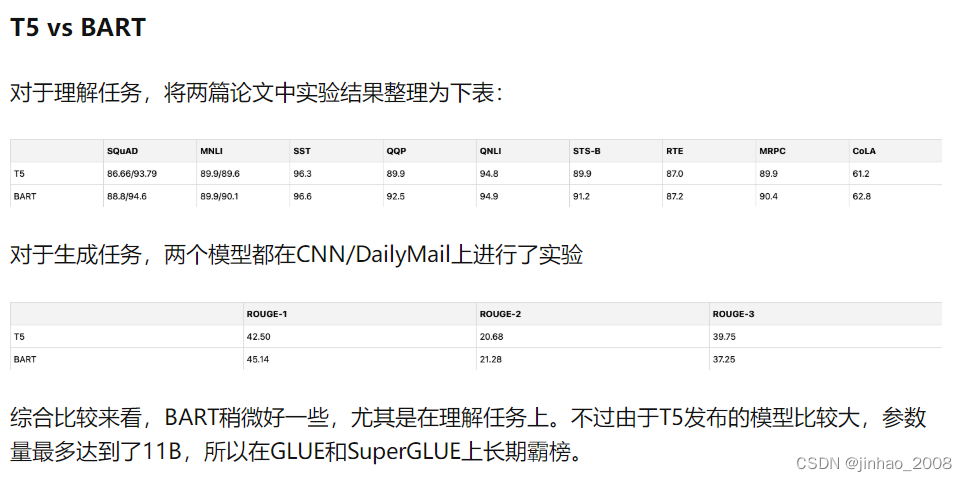
| T5 | BART | |
|---|---|---|
| 动机 | 是语言模型综述,寻找语言模型的最优结构,尝试多种结构后确定Seq2Seq结构,通过多任务学习等角度进行大量实验,再NLU和NLG任务上达到SOTA水平。产出C4英文语料。 | 想统一BERT和GPT,确定Transformers的原始结构。BART探索各种目标函数的有效性,即对输入加各种类型的噪音,在输出时将其还原。BART在NLU保持和RoBerta差不多的前提下,在多个NLG任务上取得了SOTA成绩。 |
| 模型特点 | 1、T5将Position Encoding改成相对位置嵌入 2、T5采用仍是ReLU |
1、BART 换成了和BERT一样的可学习的绝对位置编码 2、激活函数BART和BERT、GPT一样都采用的时GELU |
| 预训练任务 | T5 使用两种任务,分为有监督和无监督。其中无监督任务也是span级别的mask,不过输出不需要还原整句。只需要输出mask掉的tokens就可以。有监督任务提升不大。T5 还尝试了其他的任务类型。前缀语言模型任务,Bert 风格任务(decode 输出原句和BART类似)和打乱还原任务(DEshuffling) | 1、将带噪音的输入还原 2、使用Text Infilling + Sentence permutation,其中Text Infilling 起到了最主要的作用,其就是Span级别的mask, span 长度可取0,且服从泊松分布 |
| 微调 | 1)多任务学习上做微调 2)无论分类任务还是生成任务,全都视为生成式任务 |
1)、分类任务输入同时送入Encoder和decoder,最终输出文本表示 2)、翻译任务时,由于词表(翻译任务的词表和模型词表)不同,使用小型Encoder替代BART中的Embedding |
| 实验 | T5的实验并没有直接和BERT这种只有Encoder的模型比较,因为实验要完成生成任务,这种任务BERT无法完成 T5: 2048 ( batch_size)* 512(seq_length) * 1000000(steps) T5-base: 12-12-768(220M) T5-large: 24-24-1024(770M) |
BART: 8000(batch_size) * 512(seq_length) * 500000(steps) BART-large: 12-12-1024 |
关键技术点分析
Relu 和GELU激活函数的区别
| Relu | GELU(高斯误差线性单元) | |
|---|---|---|
| 函数性质 | 分段线性函数并不光滑,且在某点不光滑(0点不可微) | 基本上线性输出,x接近0时非线性输出。具有一定的连续性, |
| 优点 | 简化计算过程,降低计算成本,避免梯度爆炸和梯度消失 | 提供随机正则性,同时保持输入信息,提高模型的泛化能力 |
| 缺点 | 零点不可微,会某种程度上影响网络性能,需要加入随机正则提高模型泛化能力 | 计算复杂度高,增加计算成本 |
| 图形 |  |
 |