文本挖掘技术研究进展
1.文本挖掘的定义:从大量文本的集合C中,发现隐含的模式p。将C看作输入,p看作输出,那么文本挖掘的过程就是从输入到输出的一个映射C—>p
2.文本挖掘的一般处理过程: 对大量文档集合的内容进行 预处理、特征提取、结构分析、文本摘要、文本分类、文本聚类、 关联分析等
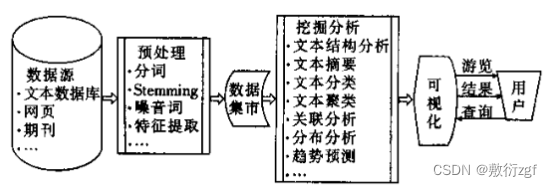
3.数据预处理技术: Stemming(english词干提取)/分词(chinese)、特征表示和特征提取
(1)分词技术
基于词库的分词算法:正向最大匹配、正向最小匹配、 逆向匹配及逐词遍历匹配法。
无词典的分词技术:将原文中任意前后紧邻的两个字作为一个词进行出现频率的统计,出现的次数越高,成为一个词的可能性也就越大,在频率超过某个预先设定的阈值时,就将其作为一个词进行索引。这种方法能够有效地提取出未登录词
(2)特征表示
文本特征指的是关于文本的元数据
描述性特征:文本的名称、日期、大小、类型等;
语义性特征:文本的作者、机构、标题、内容等
特征表示是指以一定特征项(如词条或描述)来代表文档,在文本挖掘时只需对这些特征项进行处理,从而实现对非结构化的文本处理。这是一个非结构化向结构化转换的处理步骤
(3)特征提取
用向量空间模型得到的特征向量维数达到数十万维,利用特征提取算法构造评价函数,对每一个特征进行评估,并将特征按照分值进行排序,预定分数最高的特征被选取。
常用的评估函数:信息增益、期望交叉熵、互信息、文本证据权和词频
4.挖掘分析技术: 文本结构分析、文本摘要、文本分类、文本聚类、文本关联分析、分布分析和趋势预测
(1)文本结构分析:建立文本的逻辑结构(文本结构树)根节点:文本主题,其他节点:层次和段落
(2)文本摘要:从文档中抽取关键信息,用简洁的形式对文档内容进行解释和概括。


(3)文本分类
让机器学会一个分类函数或分类模型,该模型能把文本映射到己存在的多个类别中的某一类,使检索或查询的速度更快,准确率更高
方法:朴素贝叶斯分类、向量空间模型、决策树、支持向量机、后向传播分类、遗传算法、基于案例的推理、K-最临近、基于中心点的分类方法、粗糙集、模糊集以及线性最小二乘等
(4)文本聚类
将文档集合分成若干个簇,要求同一簇内文档内容的相似度尽可能大,而不同簇间的相似度尽可能小。
方法:G-HAC等算法为代表的层次凝聚法和以 K-means等算法为代表的平面划分法。
(5)关联分析
从文档集合中找出不同词语之间的关系
(6)分布分析和趋势预测
通过对文档的分析,得到特定数据在某个历史时刻的情况或将来的取值趋势。
(7)可视化技术
运用计算机图形学和图像处理技术,将数据转换为图形或图像在屏幕上显示出来,并进行交互处理的理论、方法和技术