概述
我们的感知模式、语言和艺术作品都具有统计结构。学习这种结构是深度学习算法所擅长的。机器学习模型能够对图像、音乐和故事的统计潜在空间(latent space)进行学习,然后从这个空间中采样(sample),创造出与模型在训练数据中所见到的艺术作品具有相似特征的新作品。
而这种机器自发的学习是从我们完全不同的经验模式出发,因而能够给艺术家新的创作灵感。Iannis Xenakis 是电子音乐和算法音乐领域一位有远见的先驱,20 世纪60 年代,对于将自动化技术应用于音乐创作,他表达了与上面相同的观点:
作曲家从繁琐的计算中解脱出来,从而能够全神贯注于解决新音乐形式所带来的一般性问题,并在修改输入数据值的同时探索这种形式的鲜为人知之处。例如,他可以测试所有的乐器组合,从独奏到室内管弦乐队再到大型管弦乐队。在电子计算机的帮助下,作曲家变成了一名飞行员:他按下按钮,引入坐标,并监控宇宙飞船在声音空间中的航行,飞船穿越声波的星座和星系,这是以前只能在遥不可及的梦中出现的场景。
本文将用简单的LSTM实现字符级的文本生成,选用的例子是尼采的一些作品。,我们将会用到一个LSTM 层,向其输入从文本语料中提取的N 个字符组成的字符串,然后训练模型来生成第N+1 个字符。模型的输出是对所有可能的字符做softmax,得到下一个字符的概率分布。
如何生成序列数据
用深度学习生成序列数据的通用方法,就是使用前面的标记作为输入,训练一个网络(通常是循环神经网络或卷积神经网络)来预测序列中接下来的一个或多个标记。给定一个单词或者字符能够对下一个单词或者字符的概率进行建模的任何网络都叫作语言模型(language model)。
一旦训练好了这样一个语言模型,就可以从中采样(sample,即生成新序列)。向模型中输入一个初始文本字符串[即条件数据(conditioning data)],要求模型生成下一个字符或下一个单词(甚至可以同时生成多个标记),然后将生成的输出添加到输入数据中,并多次重复这一过程(下图)。这个循环可以生成任意长度的序列。
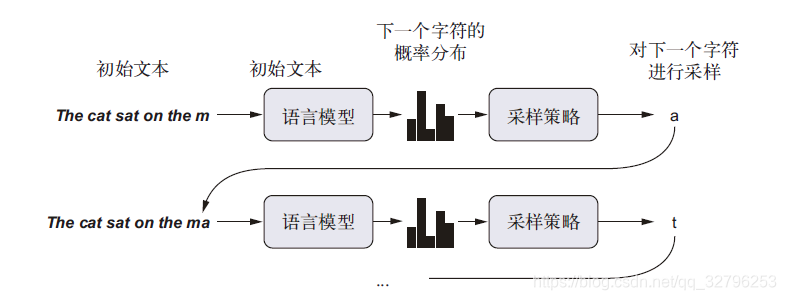
生成文本的采样策略
有两种采用策略,一种是贪婪采样(greedy sampling),另一种是随机采样。其实前一种可以看作后一种的特例。随机就是根据sofmax输出的概率进行采样,如果预测的一个词概率是10%,那么它被采样的概率也是10%。为了控制采样随机性的大小,我们引入softmax温度这个参数,对概率重新进行加权并计算。温度越高随机性越大,温度取0,就是贪婪采样。
文本序列生成程序流程
准备并解析初始文本
import keras
import numpy as np
path = keras.utils.get_file(
'nietzsche.txt',
origin='https://s3.amazonaws.com/text-datasets/nietzsche.txt')
text = open(path).read().lower()
print('Corpus length:', len(text))
将字符序列向量化
# 提取60 个字符组成的序列
maxlen = 60
# 每3个字符采样一个新序列
step = 3
# 保存所提取的序列
sentences = []
# 保存目标(即下一个字符)
next_chars = []
#就是对文本采样,相当于长度为60,步长为3的滑动窗口
for i in range(0, len(text) - maxlen, step):
sentences.append(text[i: i + maxlen])
next_chars.append(text[i + maxlen])
print('Number of sequences:', len(sentences))
# 语料中唯一字符组成的列表
chars = sorted(list(set(text)))
print('Unique characters:', len(chars))
# 一个字典,将唯一字符映射为它在列表chars 中的索引,为了后面的反向引索
char_indices = dict((char, chars.index(char)) for char in chars)
# Next, one-hot encode the characters into binary arrays.
print('Vectorization...')
x = np.zeros((len(sentences), maxlen, len(chars)), dtype=np.bool)
y = np.zeros((len(sentences), len(chars)), dtype=np.bool)
for i, sentence in enumerate(sentences):
for t, char in enumerate(sentence):
x[i, t, char_indices[char]] = 1
y[i, char_indices[next_chars[i]]] = 1
构建神经网络模型
from keras import layers
model = keras.models.Sequential()
model.add(layers.LSTM(128, input_shape=(maxlen, len(chars))))
model.add(layers.Dense(len(chars), activation='softmax'))
optimizer = keras.optimizers.RMSprop(lr=0.01)
model.compile(loss='categorical_crossentropy', optimizer=optimizer)
训练语言模型并采样
def sample(preds, temperature=1.0):
preds = np.asarray(preds).astype('float64')
preds = np.log(preds) / temperature
exp_preds = np.exp(preds)
preds = exp_preds / np.sum(exp_preds)
#第一个参量是取得个数,第二个参量是概率分布,第三个参量是生成多少个
probas = np.random.multinomial(1, preds, 1)
return np.argmax(probas)
用模型生成文本
import random
import sys
for epoch in range(1, 60):
print('epoch', epoch)
model.fit(x, y, batch_size=128, epochs=1)
start_index = random.randint(0, len(text) - maxlen - 1)
generated_text = text[start_index: start_index + maxlen]
print('--- Generating with seed: "' + generated_text + '"')
for temperature in [0.2, 0.5, 1.0, 1.2]:
print('------ temperature:', temperature)
sys.stdout.write(generated_text)
#从种子文本开始生成400个字符
for i in range(400):
# 对生成的字符进行one-hot 编码
sampled = np.zeros((1, maxlen, len(chars)))
for t, char in enumerate(generated_text):
sampled[0, t, char_indices[char]] = 1.
preds = model.predict(sampled, verbose=0)[0]
next_index = sample(preds, temperature)
next_char = chars[next_index]
generated_text += next_char
generated_text = generated_text[1:]
sys.stdout.write(next_char)
