在Kafka当中数据是以日志的形式存在的
Kafka 的存储日志
在Kafka当中。数据在磁盘当中的存储:
- Kafka中的数据是保存在 /export/server/kafka_2.12-2.4.1/data中
- 消息是保存在以:「主题名-分区ID」的文件夹中的
- 数据文件夹中包含以下内容

这些分别对应:
| 文件名 | 说明 |
|---|---|
| 00000000000000000000.index | 索引文件,根据offset查找数据就是通过该索引文件来操作的 |
| 00000000000000000000.log | 日志数据文件 |
| 00000000000000000000.timeindex | 时间索引 |
| leader-epoch-checkpoint | 持久化每个partition leader对应的 LEO(log end offset、日志文件中下一条待写入消息的offset ) |
- 每个日志文件的文件名为起始偏移量,因为每个分区的起始偏移量是0,所以,分区的日志文件都以0000000000000000000.log开始的
- 默认的每个日志文件最大为:log.segment.bytes =102410241024 是为1G
- 为了简化根据 offset 查找消息,Kafka 日志文件名设计为开始的偏移量。
日志的观察模式
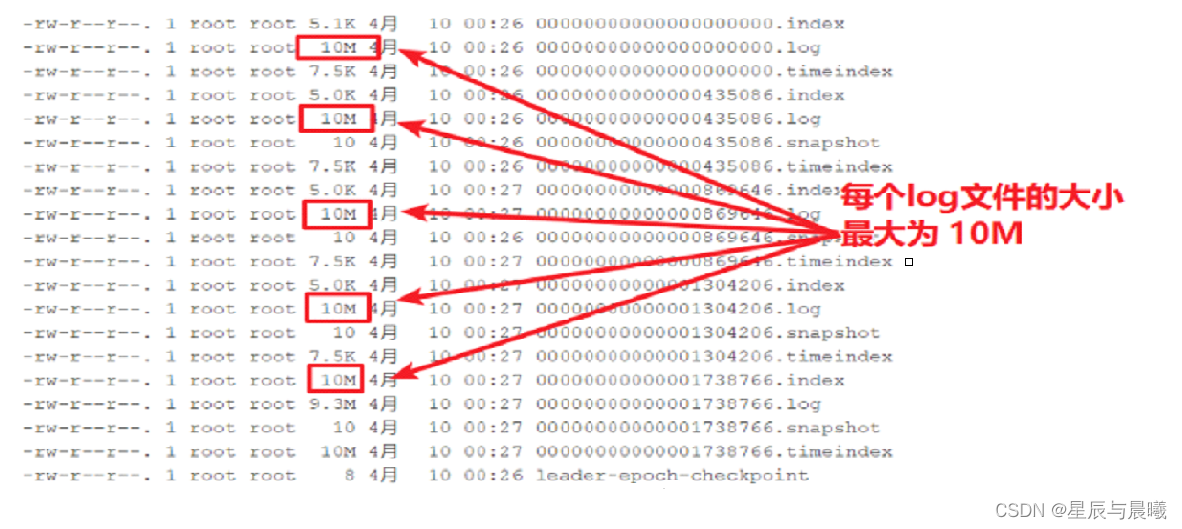
为了方便测试观察,新创建一个topic:「test_10m」,该topic每个日志数据文件最大为10M
bin/kafka-topics.sh --create --zookeeper node1.itcast.cn --topic test_10m --replication-factor 2 --partitions 3 --config segment.bytes=10485760
使用之前的生产者程序以往主题中生产数据,可以观察到如下:
每个log文件的大小最大为10M

日志写入模式
- 新的消息总是写入到最后的一个日志文件中
- 该文件如果到达指定的大小(默认为:1GB)时,将滚动到一个新的文件中
日志读写模式
- 根据offset首先需要找到存储数据的 segment 段(注意:offset指定分区的全局偏移量)
- 然后根据这个全局分区 offset 找到相对于文件的 segment段offset
- 最后再根据 「segment段offset」读取消息
- 为了提高查询效率,每个文件都会维护对应的范围内存,查找的时候就是使用简单的二分查找
删除消息
- 在Kafka中,消息是会被定期清理的。一次删除一个segment段的日志文件。
- Kafka 的日志管理器,会根据Kafka的配置,来决定哪些文件可以被删除
数据挤压问题
Kafka 消费者消费数据的速度是非常快的,但如果由于处理 Kafka 消息时,由于有一些外部 IO、或者是产生网络拥堵,就会造成 Kafka 中的数据积压(或称为数据堆积)。如果数据一直积压,会导致数据出来的实时性受到较大影响。
当Kafka出现数据积压问题时,首先要找到数据积压的原因。
以下是在企业中出现数据积压的几个类场景:
- 数据写入MySQL失败
问题描述:
某日运维人员找到开发人员,说某个 topic 的一个分区发生数据积压,这个topic 非常重要,而且开始有用户投诉。运维非常紧张,赶紧重启了这台机器。重启之后,还是无济于事。
问题分析:
消费这个 topic 的代码比较简单,主要就是消费topic数据,然后进行判断在进行数据库操作。运维通过 kafka-eagle 找到积压的 topic,发现该topic的某个分区积压了几十万条的消息。
最后,通过查看日志发现,由于数据写入到 MySQL 中报错,导致消费分区的 offset 一直没有提交,所以数据积压严重。
- 因为网络延迟消费失败
问题描述:
基于Kafka开发的系统平稳运行了两个月,突然某天发现某个topic中的消息出现数据积压,大概有几万条消息没有被消费.
问题分析:
通过查看应用程序日志发现,有大量的消费超时失败。后查明原因,因为当天网络抖动,通过查看 Kafka 的消费者超时配置为50ms,随后,将消费的时间修改为 500ms 后问题解决。
数据清理
Kafka的消息存储在磁盘中,为了控制磁盘占用空间,Kafka需要不断地对过去的一些消息进行清理工作。Kafka 的每个分区都有很多的日志文件,这样也是为了方便进行日志的清理。在Kafka中,提供两种日志清理方式:
- 日志删除(Log Deletion):按照指定的策略直接删除不符合条件的日志。
- 日志压缩(Log Compaction):按照消息的key进行整合,有相同key的但有不同value值,只保留最后一个版本。
在Kafka的broker或topic配置中:
| 配置项 | 配置值 | 说明 |
|---|---|---|
| log.cleaner.enable | true(默认) | 开启自动清理日志功能 |
| log.cleanup.policy | delete(默认) | 删除日志 |
| log.cleanup.policy | compaction | 压缩日志 |
| log.cleanup.policy | delete,compact | 同时支持删除、压缩 |
日志删除
日志删除是以段(segment日志)为单位来进行定期清理的。
定时日志删除任务
Kafka日志管理器中会有一个专门的日志删除任务来定期检测和删除不符合保留条件的日志分段文件,这个周期可以通过broker端参数log.retention.check.interval.ms 来配置,默认值为300,000,即5分钟。当前日志分段的保留策略有3种:
- 基于时间的保留策略
- 基于日志大小的保留策略
- 基于日志起始偏移量保留策略
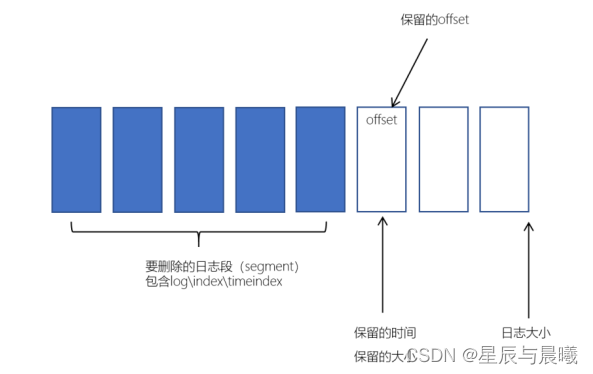
基于时间的保留策略
以下三种配置可以指定如果Kafka中的消息超过指定的阈值,就会将日志进行自动清理
- log.retention.hours
- log.retention.minutes
- log.retention.ms
其中,优先级为 log.retention.ms > log.retention.minutes > log.retention.hours。默认情况,在broker中,配置如下:
log.retention.hours=168
也就是,默认日志的保留时间为168小时,相当于保留7天。
删除日志分段时:
- 从日志文件对象中所维护日志分段的跳跃表中移除待删除的日志分段,以保证没有线程对这些日志分段进行读取操作
- 将日志分段文件添加上“.deleted”的后缀(也包括日志分段对应的索引文件)
- Kafka的后台定时任务会定期删除这些“.deleted”为后缀的文件,这个任务的延迟执行时间可以通过file.delete.delay.ms参数来设置,默认值为60000,即1分钟。
基于日志大小的保留策略
日志删除任务会检查当前日志的大小是否超过设定的阈值来寻找可删除的日志分段的文件集合。可以通过 broker 端参数 log.retention.bytes 来配置,默认值为 -1,表示无穷大。如果超过该大小,会自动将超出部分删除.
注意:log.retention.bytes 配置的是日志文件的总大小,而不是单个的日志分段的大小,一个日志文件包含多个日志分段
基于日志起始偏移量保留策略
每个segment日志都有它的起始偏移量,如果起始偏移量小于 logStartOffset,那么这些日志文件将会标记为删除.
日志压缩
Log Compaction是默认的日志删除之外的清理过时数据的方式。它会将相同的key对应的数据只保留一个版本。
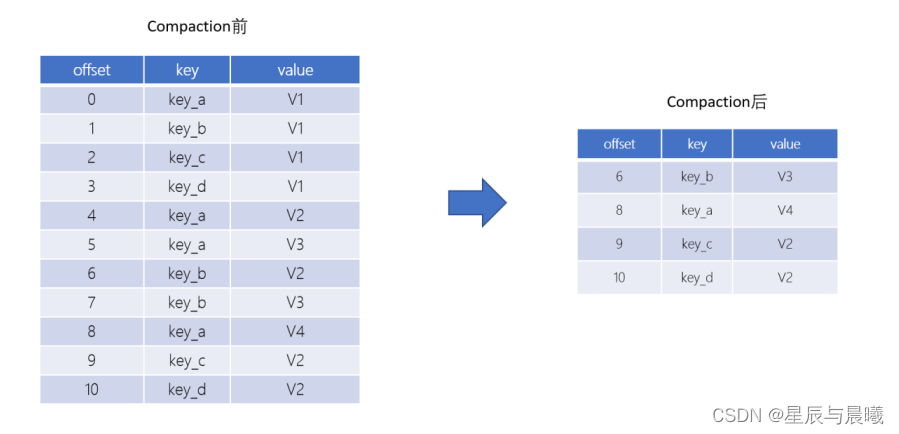
- Log Compaction执行后,offset将不再连续,但依然可以查询Segment
- Log Compaction执行前后,日志分段中的每条消息偏移量保持不变。Log Compaction会生成一个新的Segment文件。
- Log Compaction是针对key的,在使用的时候注意每个消息的key不为空。
- 基于Log Compaction可以保留key的最新更新,可以基于Log Compaction来恢复消费者的最新状态。