- Kafka中的消息是根据Topic进行分类的。生产者生产数据,消费者消费数据,都是面向topic。
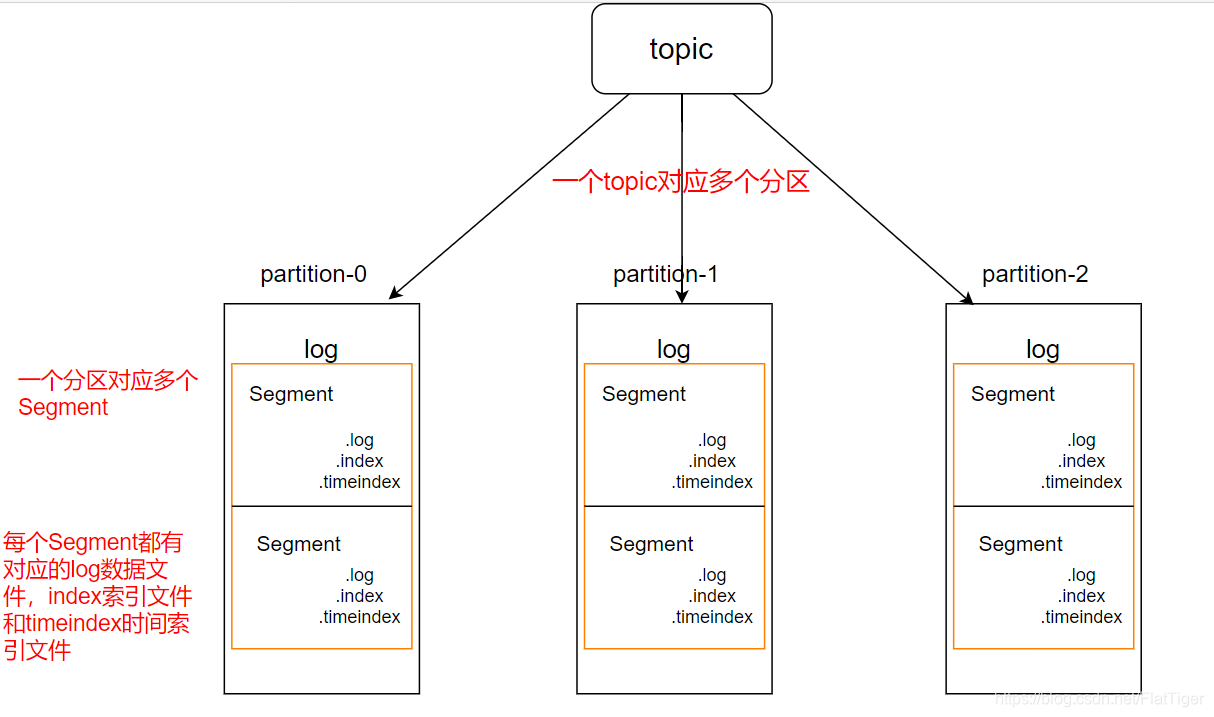
- Topic是逻辑上的概念,分区是物理上的概念,分区规则为“topic名称+分区名”。每个分区中都对应一个log文件,该文件就是生产者生产的数据。生产者生产的数据会不断的追加到log文件末尾。此外每个分区都有其副本,不同副本存储在不同的broker节点。
- 为了防止log文件过大,导致数据定位效率过低,Kafka采用了分片和索引机制。
- 每个log文件在达到一定的大小后(默认1G),都被物理上切分为多个Segment,每个Segment都有其对应的log文件、index索引文件、timeindex时间索引文件。
- log文件和index文件的命名规则为,当前Segment的第一条消息的offset。