最近遇到同一环境下,拍摄多张图片,检测结果存在差异的问题,故调研,考虑使用融合多帧信息去解决上述问题,发现这篇论文,该算法适用于我当前的问题,更适用于从事监控领域的同学,算法细节不赘述,看算法主体思路:
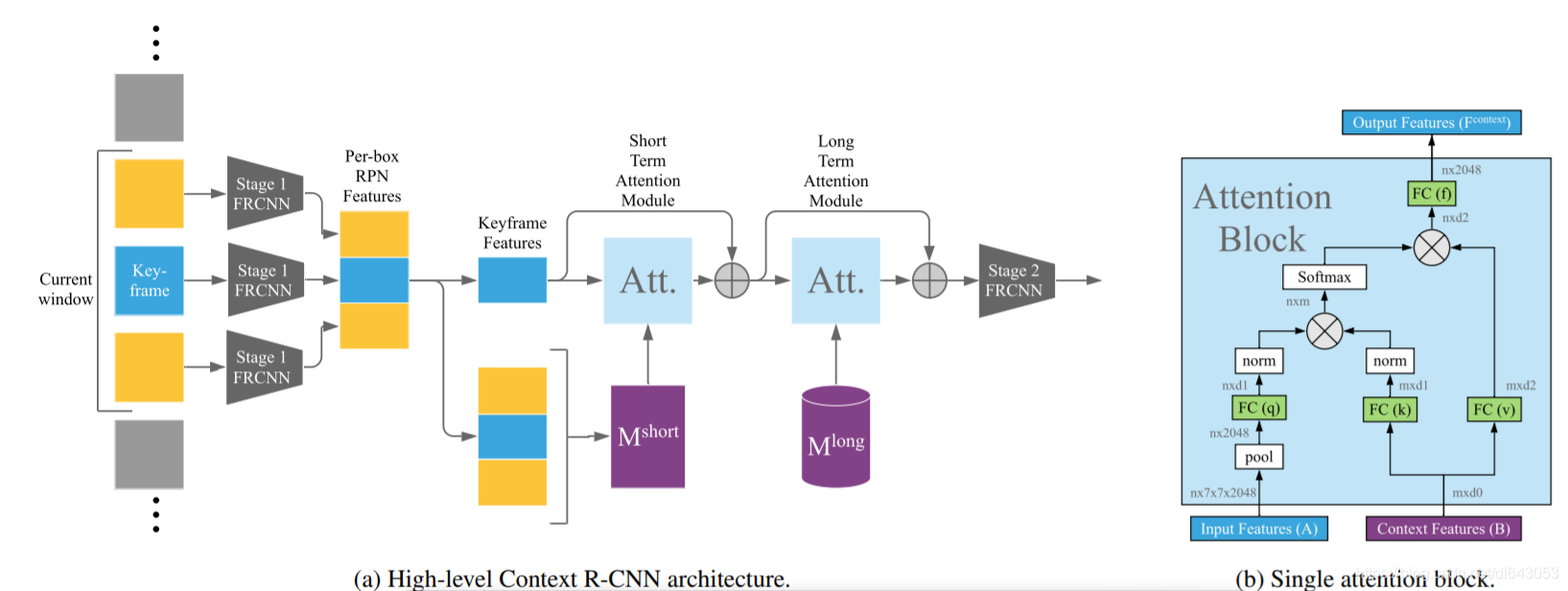
算法前半部分与双阶段RPN网络基本无异, 只是输入为多帧图片,得到若干anchor box的featrues,其中关键帧提取出n个,关键帧与其他帧共m个,此处双阶段检测相比于单阶段在视频信息融合上体现出了优势,即可以提取语义特征后接融合算法,接下来就是融合RPN的信息,论文中使用了attention机制,为了减少运算和存储负担,先对RPN特征进行pooling,此处操作和SEblock很像,之后通过前向得到q,k,v,q由关键帧得到,字典k则由所有帧(上下文帧以及关键帧)前向得到,接下来的操作在我看来具有很强的可解释性,通过q与k相乘,很好的查找了上下文特征与关键帧特征相关联的信息,并得到高权重,最后对v加权,投影后再叠加到关键帧的RPN特征上。
这种通过attention融合第一阶段特征进行视频分析相似的论文还有Object Detection in Video with Spatial-temporal Context Aggregation,Memory Enhanced Global-Local Aggregation for Video Object Detection,在我看来这几篇基本是一个意思,但谷歌的这篇论文写的不错,另外两篇notation满天飞,看着烦,只粗读