解调做完后,我开始研究解码。
我找到了这个资源不错。可以用来解码音频文件里的navtex文字信息。
GitHub - pd0wm/navtex: Simple Navtex decoder
它用的ipynb,我不习惯,转换为了如下的python代码。
import numpy as np
import scipy
import scipy.signal
from scipy.io import wavfile
import matplotlib.pyplot as plt
from navtex import ALPHABET_FIGS, ALPHABET_LTRS
# Load audio files
FILENAME = 'audio/navtex_44k_32bit.wav'
sample_rate, data = wavfile.read(FILENAME)
data = 1. * np.array(data) # Convert to floats
# If stero take left channel
if len(data.shape) > 1 and data.shape[1] == 2:
data = data[:, 1]
# Filter DC
data -= np.average(data)
print (sample_rate, data.shape)
# Approximate center frequency by taking strongest frequency
f = np.abs(np.fft.fft(data))
fs = np.fft.fftfreq(data.size, d=1.0/sample_rate)
# Take positive frequencies
f = f[:int(f.size/2)]
fs = fs[:int(fs.size/2)]
center_freq = fs[np.argmax(f)]
plt.plot(fs, f)
plt.xlim([center_freq-500, center_freq+500])
plt.xlabel('Freq [hz]')
print ("strongest frequency", center_freq)
# NAVTEX is modulated using FSK (frequency shift keying) which we have to demodulate first
# Find acceptable frequency range
f = center_freq # Use common center frequency. Can also use frequency found above
f_min = (f-500.) / sample_rate
f_max = (f+500.) / sample_rate
f = f / sample_rate
# Simple PLL to recover frequency without using slow FFTs
prev_start_t = 0
fs = []
for t in range(1, len(data)):
x = np.sin((t - prev_start_t) * 2 * np.pi * f)
# On zero crossing of received signal check phase of internal oscillator
if data[t] > 0 and data[t-1] < 0:
prev_start_t = t
# Adjust frequency proportional to phase offset
f -= (100.0 / sample_rate) * x
# Clip to acceptable frequency range
f = min(f, f_max)
f = max(f, f_min)
fs.append(f)
fs = np.array(fs)
#for it in fs:
# print (it)
N = int(40 * (1./100) * sample_rate)
plt.plot(fs)
plt.xlim([0, N])
# Extract bits from demodulated frequency. NAVTEX is transmitted at 100 bits/sec
avg = np.average(fs) # Center frequency
expected_len = sample_rate / 100. # 100 Baud
prev_change = 0
bits = []
for i in range(5, len(fs)):
di = i - prev_change
num_bits = round(di / expected_len)
if num_bits > 0.5:
if fs[i] > avg and fs[i-1] < avg: # Rising, previous was 0
bits += int(num_bits) * [0]
prev_change = i
elif fs[i] < avg and fs[i-1] > avg: # Falling, previous was 1
bits += int(num_bits) * [1]
prev_change = i
bits = np.array(bits)
# More information about the decoding process can be found here: https://arachnoid.com/JNX/
# Summarized:
# 1) Symbols are 7 bit, always 4 ones, 3 zeroes
# 2) Shift through data until symbols have 4 ones, 3 zeroes
# 3) Seperate two datastreams, indicated by [alpha] and [rep]
# 4) There are two alphabets, one for letters one for symbols. Switch on [ltrs] & [figs]
# 5) Accept characters if they are equal in both streams
# TODO: Error correction
N = 7
shift = 0
cur_alphabet_A = ALPHABET_LTRS
cur_alphabet_B = ALPHABET_LTRS
msg_a = ""
msg_b = ""
msgs_a = []
msgs_b = []
alpha_shift = 0
phased = False
phased_count = 0
i = 0
while i*N + shift < len(bits):
b = bits[i*N + shift:(i+1)*N + shift]
s = "".join(map(str, b))
s = s[::-1]
h = int(s, 2)
if s.count('1') != 4:
phased_count -= 1
if phased_count < 10:
shift += 1
continue
else:
phased_count += 1
phased_count = min(50, phased_count)
# Phasing signals, reset receiver
if h == 0xf: # [alpha]
alpha_shift = i % 2
cur_alphabet_A = ALPHABET_LTRS
if len(msg_a.replace('_', '')) > 10:
msgs_a.append(msg_a)
msgs_b.append(msg_b)
msg_a = ""
msg_b = ""
msg_a = ""
elif h == 0x66: # [rep]
alpha_shift = (i+1) % 2
cur_alphabet_B = ALPHABET_LTRS
if len(msg_a.replace('_', '')) > 10:
msgs_a.append(msg_a)
msgs_b.append(msg_b)
msg_a = ""
msg_b = ""
msg_b = ""
# Regular symbols
if i % 2 == alpha_shift:
dec = cur_alphabet_A[h]
if dec == '[ltrs]':
cur_alphabet_A = ALPHABET_LTRS
elif dec == '[figs]':
cur_alphabet_A = ALPHABET_FIGS
elif not dec.startswith('['):
msg_a += dec
else:
dec = cur_alphabet_B[h]
if dec == '[ltrs]':
cur_alphabet_B = ALPHABET_LTRS
elif dec == '[figs]':
cur_alphabet_B = ALPHABET_FIGS
elif not dec.startswith('['):
msg_b += dec
i += 1
i = 0
for msg_a, msg_b in zip(msgs_a, msgs_b):
print (i)
i += 1
msg = ""
for a, b in zip(msg_a, msg_b):
if a == b:
msg += a
else:
if a == '_' and b != '_':
msg += b
elif a != '_' and b == '_':
msg += a
else:
msg += "_"
print ("A: ", msg_a)
print ("B: ", msg_b)
print ("final: ", msg)
print ("-" * 80)from collections import defaultdict
ALPHABET_LTRS = defaultdict(lambda: '_')
ALPHABET_FIGS = defaultdict(lambda: '_')
ALPHABET_LTRS.update({
0x0f: "[alpha]",
0x17: "J",
0x1b: "F",
0x1d: "C",
0x1e: "K",
0x27: "W",
0x2b: "Y",
0x2d: "P",
0x2e: "Q",
0x33: "[beta]",
0x35: "G",
0x36: "[figs]",
0x39: "M",
0x3a: "X",
0x3c: "V",
0x47: "A",
0x4b: "S",
0x4d: "I",
0x4e: "U",
0x53: "D",
0x55: "R",
0x56: "E",
0x59: "N",
0x5a: "[ltrs]",
0x5c: " ",
0x63: "Z",
0x65: "L",
0x66: "[rep]",
0x69: "H",
0x6a: "[]",
0x6c: "\n",
0x71: "O",
0x72: "B",
0x74: "T",
0x78: "[cr]"
})
ALPHABET_FIGS.update({
0x0f: "[alpha]",
0x17: "'",
0x1b: "!",
0x1d: ":",
0x1e: "(",
0x27: "2",
0x2b: "6",
0x2d: "0",
0x2e: "1",
0x33: "[beta]",
0x35: "&",
0x36: "[figs]",
0x39: ".",
0x3a: "/",
0x3c: ";",
0x47: "-",
0x4b: "[bell]",
0x4d: "8",
0x4e: "7",
0x53: "$",
0x55: "4",
0x56: "3",
0x59: ",",
0x5a: "[ltrs]",
0x5c: " ",
0x63: "\"",
0x65: ")",
0x66: "[rep]",
0x69: "#",
0x6a: "[]",
0x6c: "\n",
0x71: "9",
0x72: "?",
0x74: "5",
0x78: "[cr]"
})它还推荐了一个网站
Free NAVTEX decoder / ナブテックスデコーダーフリーダウンロード
可以把文字信息转为navtex格式的音频。
不过音频的格式不太一样。
网页编码器生成的是16bit 11.025kHz的音频。ipynb项目需要使用的是32bit 44kHz的音频。另外,我的gnuradio和portapack用的都是8bit 48kHz的音频。这个格式问题都可以用audacity解决。
然后我先用网页生成全部是R的信息、全部是O的信息,以及RO相间的信息。再用ipynb项目解都能解成功。我还用gnuradio看了这些音频的波型,在尝试找规律。
这是解码结果:
(44100, (338800,))
('strongest frequency', 1804.0909090909088)
0
('A: ', 'RRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRR')
('B: ', 'RRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRR')
('final: ', 'RRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRR')
--------------------------------------------------------------------------------
(48000, (368762,))
('strongest frequency', 1804.0904431584599)
0
('A: ', 'OOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOO')
('B: ', 'OOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOO')
('final: ', 'OOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOO')
--------------------------------------------------------------------------------
(44100, (338800,))
('strongest frequency', 1804.0909090909088)
0
('A: ', 'ROROROROROROROROROROROROROROROROROR')
('B: ', 'ROROROROROROROROROROROROROROROROROROR')
('final: ', 'ROROROROROROROROROROROROROROROROROR')
--------------------------------------------------------------------------------
以下分别是纯r和纯o、ro相间的波型图的最后部分,注意最后一段与内容无关的波型。
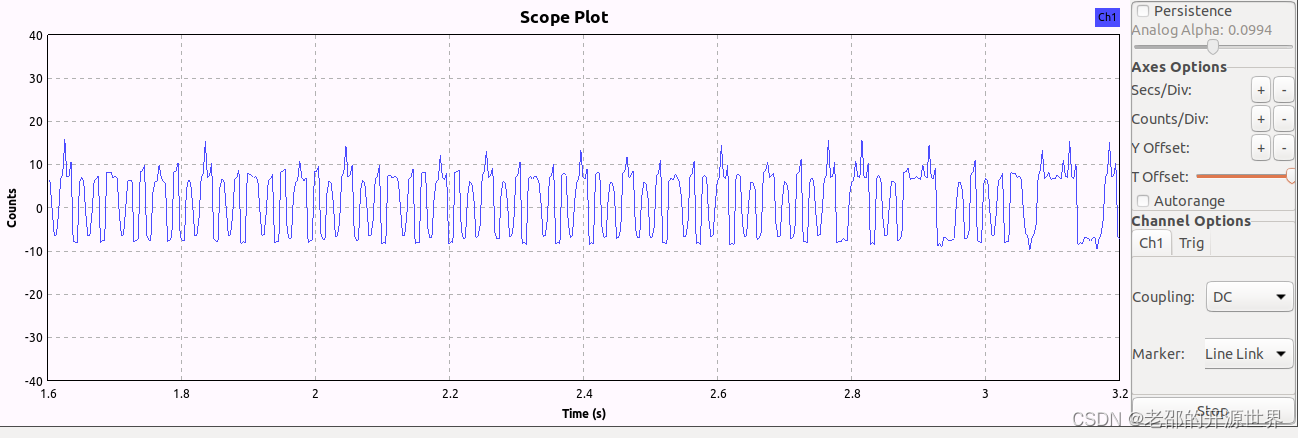

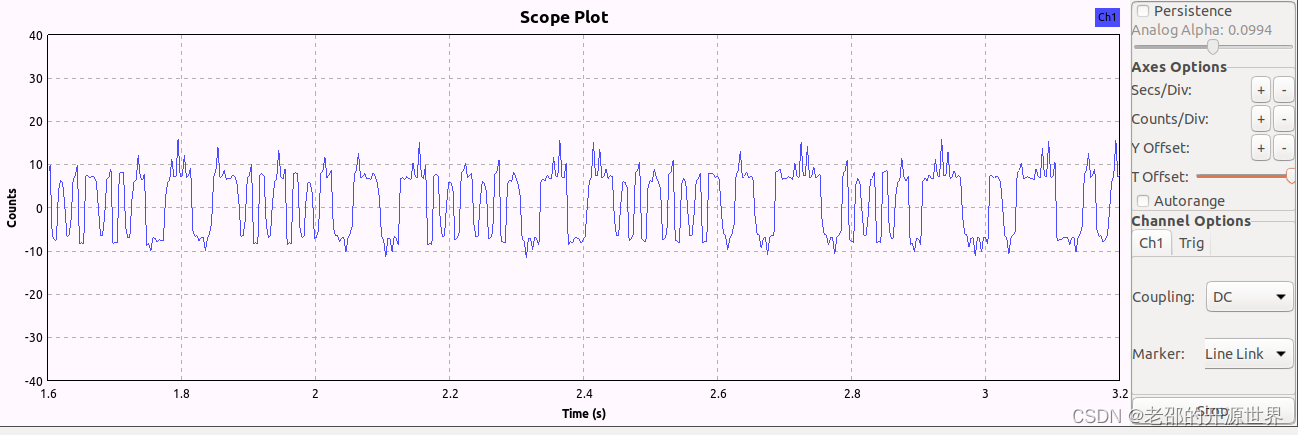
另外,由于生成的音频频率偏高,所以重新调整了滤波器中心频率,为了波型看着更好,还调整了滤波器带宽。流图如下:

我大致看了python代码和协议的描述。(上一篇文章中文里的4B3Y,是4个0,3个1是错的)。
每个字符是7bit,会有4个1和3个0。可以用这个特性来判断字符从哪一位开始。每个bit是1的时候就是高电平,0的时候就是低电平。
另外,字符会重复传输,用来验证传输有没有出错。
重复方法如下:
原字符串:ABCDEFGHI
实际字符串:ABCADBECFDGEHFIGHI
这样对全是RRRRRRRRRRRRRRR或者全是OOOOOOOOOOO的字符串,第二个特性没有效果。只需要关注第一个特性。
R <-> 1010101
O <-> 1110001
如此一来RRRRRRRR的字符串,在空气中还是RRRRRRR,对应每个bit是:
101010110101011010101,可以看到规律是时不时会出现两个连着的1,对应一个较长的高电平,然后左右各有3次的快速01切换。与第一张实际解调波型完全一致。
OOOOOOO的字符串,在空气中还是OOOOOOO,对应每个bit是:
11100011110001111000111100011110001,可以看到规律是4个1和3个0不停重复,对应很长的高电平和比较长的低电平,周期性出现。这与第二章实际解调波型也是一致的。
针对原始信息是RORORORORORORO,发到空中后是:
RORROORROORROORROR
对应每个bit是:
1010101111000110101011010101111000111100011010101101010111100011110001
我对比了第三张图,一开始怎么都对不上,后来发现要左右反一反才能对上:
1000111100011110101011010101100011110001111010101101010110001111010101
然后还要把一开头单独的RO去掉,这样才符合这串数据中间任意段落的情况:
10001111000111101010110101011000111100011110101011010101
这样上面这段就跟流图波型对上了。
所以总结下来除了之前知道的每个字符对应的bit,以及字符的重复方式需要注意外,还有流图里波型左右顺序要和01相反。就类似big endian和little endian的问题。至于纯R和纯O没发现这个问题,是因为它们的编码和波型本就左右对称。
通过本篇文章可以确定解调出的方波,高电平就是1,低电平就是0。
要区分连续0和连续1,只需要求采样率48kHz和波特率100之比,这样480个采样点对应1个bit。
我们只要找出上升沿和下降沿,然后计算出两个边沿之间的采样点,把采样点数量除以480,就能知道这两个边沿之间有多少个连续0或连续1。
恢复出0101的数据后,再去找从哪个位置开始分隔,分隔出的每7bit数据里有4个1和3个0,并至少持续40个有效数据。
最后,还要把两个序列区分出来,也就是说要把RROORROORROO,分开为两列RORORORORO,然后验证这两列数据是否相等(帮助判断通信质量)。这两列数据的开头有0x0f和0x66会告诉你他们属于A列还是B列。