日志数据采集
平台搭建模型设计
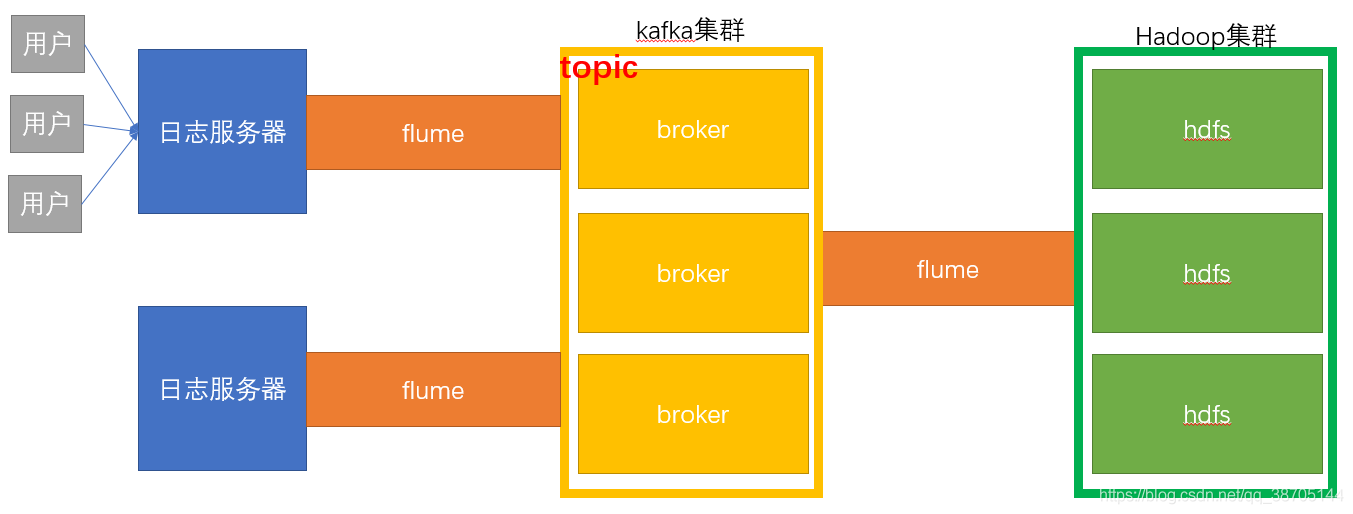
1、日志采集
方案选择
方案一:使用flume直接从日志服务器到hdfs
不能采用原因:
- 1、由于日志服务器较多,直接从日志服务器到HDFS,会导致HDFS的访问量过高,
- 2、由于flume采集到不同服务器上的同一时间段的日志,会写入到HDFS上同一个目录中,而同一文件的写入不支持多线程同时写入。
方案二:使用flume聚合再传输给hdfs
此方案解决了方案一中多线程同时写入的问题。
- 不能采用原因:由于flume聚合,多个flume将会写入到一个flume中,末端的flume的传输负载较大,造成数据堆积,采集停止
方案三:使用flume–>kafka–>flume的方式
- 中间通过kafka集群的缓冲,缓解了flume的负载,因此采用该方案。
第一层flume配置规划
flume读取本地日志服务器的数据,需要监控多目录中的文件的变化,所以source端采用taildir的方式,
方案一:memory channel + kafka sink

方案二:kafka channel

优势:无需经过kafka sink,传输速率更高
拦截器配置
为了后期对数据进行分析,需要考虑数据的格式问题,需要先将数据进行清洗,通过拦截器,将前端传输的非json格式的数据清洗
拦截器实现
import com.alibaba.fastjson.JSON;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.util.Iterator;
import java.util.List;
/**
* @ClassName : LocalKfkInterceptor
* @Author : kele
* @Date: 2021/1/13 18:39
* @Description :配置本地数据到kafka时的拦截器,拦截飞json格式的数据
*
*/
public class LocalKfkInterceptor implements Interceptor {
@Override
public void initialize() {
}
/**
* 单个事件的拦截器,判断传输的数据格式是否是json的格式
* @param event
* @return
*/
@Override
public Event intercept(Event event) {
String s = new String(event.getBody());
try {
//如果不是json格式,则会抛异常,设置返回空值,否则返回本身
//通过是否有异常,决定是否删除改数据
JSON.parseObject(s);
return event;
} catch (Exception e) {
return null;
}
}
@Override
public List<Event> intercept(List<Event> list) {
Iterator<Event> it = list.iterator();
while(it.hasNext()){
Event event = it.next();
if(intercept(event) == null)
it.remove();
}
return list;
}
@Override
public void close() {
}
/**
* 需要静态 内部类实现Builder
*/
public static class MyBuilder implements Builder{
@Override
public Interceptor build() {
return new LocalKfkInterceptor();
}
@Override
public void configure(Context context) {
}
}
}
flume配置文件
#使用taildir source,kafka channel将监测的数据写入
a1.sources = r1
a1.channels = c1
#配置监控的方式,TAILDIR多目录监控,监控的目录中文件变化时才能检测到
a1.sources.r1.type = TAILDIR
#设置监控组,用来实现多目录监控
a1.sources.r1.filegroups = f1
#设置监控的路径
a1.sources.r1.filegroups.f1 = /opt/module/applog/log/app.*
#配置批次的大小
a1.sources.r1.batchSize = 100
#设置断点续传记录的位置保存的地址
a1.sources.r1.positionFile = /opt/module/flume/position.json
#设置拦截器
#将不是json格式传输的数据拦截
a1.sources.r1.interceptors = i1
#设置拦截器的类型,地址
a1.sources.r1.interceptors.i1.type = com.atguigu.interce.LocalKfkInterceptor$MyBuilder
#配置kafka channel,
#channel类型,写入kafka channel的集群、topic名称、是否以事件的方式传输(该配置需要与kafka source设置的类型一致)
a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092
a1.channels.c1.kafka.topic = first
a1.channels.c1.parseAsFlumeEvent = false
#source与channel的连接方式
a1.sources.r1.channels = c1
2、日志存储

channel的类型选择
方案一:MemoryChannel
MemoryChannel传输数据速度更快,但因为数据保存在JVM的堆内存中,Agent进程挂掉会导致数据丢失,适用于对数据质量要求不高的需求。
方案二:FileChannel
FileChannel传输速度相对于Memory慢,但数据安全保障高,Agent进程挂掉也可以从失败中恢复数据。
方案三:kafkaChannel
使用kafkachannel则不需要source,但由于需要拦截器,如果有没source则无法配置拦截器,(需要解决零点漂移问题)
拦截器配置
由于Flume默认会用Linux系统时间,作为输出到HDFS路径的时间。如果数据是23:59分产生的。Flume消费Kafka里面的数据时,有可能已经是第二天了,那么这部门数据会被发往第二天的HDFS路径。我们希望的是根据日志里面的实际时间,发往HDFS的路径,所以下面拦截器作用是获取日志中的实际时间。
- 解决的思路:拦截json日志,通过fastjson框架解析json,获取实际时间ts。将获取的ts时间写入拦截器header头,header的key必须是timestamp,因为Flume框架会根据这个key的值识别为时间,写入到HDFS。
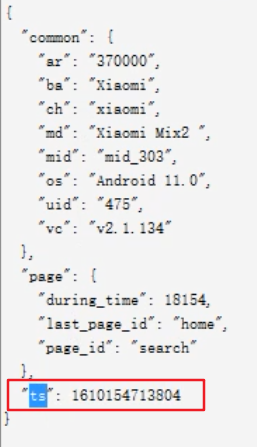
数据形式
获取ts字段
仿照默认的TimpStamp interceptor拦截器进行设置
官网Timestamp Interceptor介绍:
Timestamp Interceptor
This interceptor inserts into the event headers, the time in millis at which it processes the event. This interceptor inserts a header with key timestamp (or as specified by the header property) whose value is the relevant timestamp. This interceptor can preserve an existing timestamp if it is already present in the configuration.
这个拦截器插入一个带有键时间戳的头(或由头属性指定的),它的值是timestamp 。如果配置中已经存在一个时间戳,这个拦截器可以保留它。
拦截器实现
/**
* @ClassName : KfkHdfsInterceptor
* @Author : kele
* @Date: 2021/1/12 21:02
* @Description :自定义拦截器,
* 通过设置event的K,V来解决零点漂移问题
*/
public class KfkHdfsInterceptor implements Interceptor {
@Override
public void initialize() {
}
/**
* 增加时间的k,v解决零点漂移问题
* @param event
* @return
*/
@Override
public Event intercept(Event event) {
String s = new String(event.getBody());
JSONObject json = JSON.parseObject(s);
Long ts = json.getLong("ts");
Map<String, String> headers = event.getHeaders();
headers.put("timestamp",ts+"");
return event;
}
@Override
public List<Event> intercept(List<Event> list) {
for (Event event : list) {
intercept(event);
}
return list;
}
@Override
public void close() {
}
public static class MyBuilder implements Builder{
@Override
public Interceptor build() {
return new KfkHdfsInterceptor();
}
@Override
public void configure(Context context) {
}
}
}
flume的配置文件
#1、定义agent、channel、source、sink的名称
a1.sources = r1
a1.channels = c1
a1.sinks = k1
#2、描述source
#source类型,所在集群,topic名称,groupid,
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092
a1.sources.r1.kafka.topics = first
a1.sources.r1.kafka.consumer.group.id = g3
a1.sources.r1.batchSize = 100
a1.sources.r1.useFlumeEventFormat = false
a1.sources.r1.kafka.consumer.auto.offset.reset = earliest
#3、描述拦截器
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.atguigu.interce.KfkHdfsInterceptor$MyBuilder
#4、描述channel
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /opt/module/flume/checkpoint
a1.channels.c1.dataDirs = /opt/module/flume/datas
a1.channels.c1.checkpointInterval = 1000
a1.channels.c1.transactionCapacity = 1000
#5、描述sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.channel = c1
a1.sinks.k1.hdfs.path = hdfs://hadoop102:8020/applog/%Y-%m-%d
a1.sinks.k1.hdfs.filePrefix = log-
a1.sinks.k1.hdfs.rollInterval = 30
#滚动大小,一般设置为稍小于128M,这里设置为126M
a1.sinks.k1.hdfs.rollSize = 132120576
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.batchSize = 100
#设置文件保存到HDFS的时候采用哪种压缩格式
#a1.sinks.k1.hdfs.codeC = lzop
#设置文件的输出格式
#a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.fileType = DataStream
#6、关联source->channel->sink
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1