集群规划

日志消费Flume配置
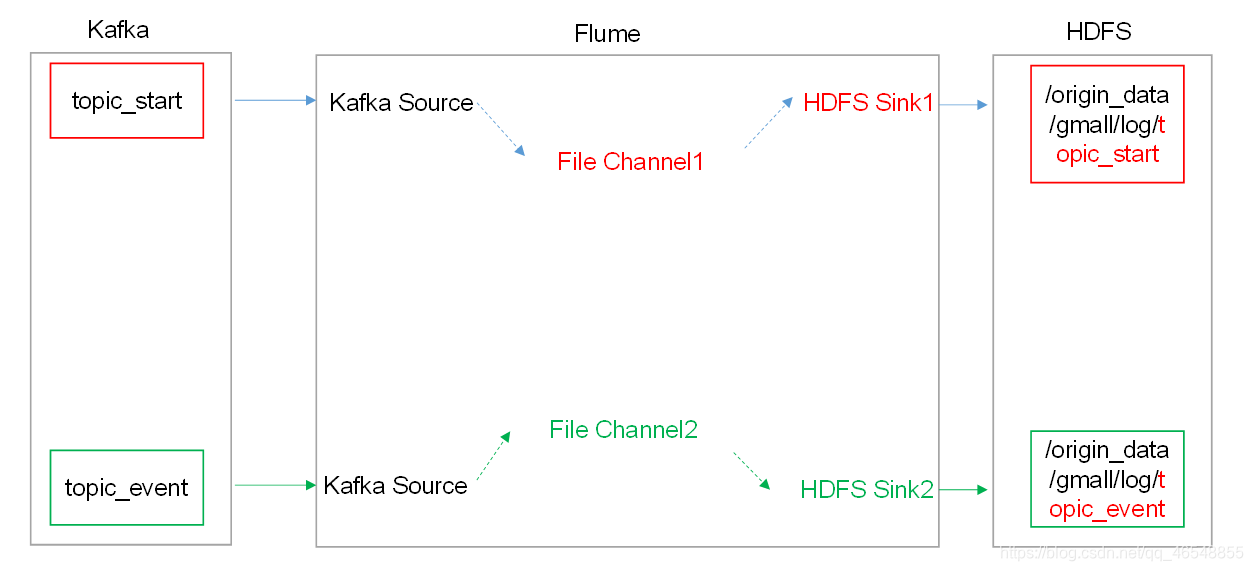
1.Flume的具体配置如下:
(1)在hadoop14的/export/servers/flume/conf目录下创建kafka-flume-hdfs.conf文件
a1.sources=r1 r2
a1.channels = c1 c2
a1.sinks = k1 k2
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.batchSize = 5000
a1.sources.r1.batchDurationMillis = 2000
a1.sources.r1.kafka.bootstrap.servers = hadoop12:9092,hadoop13:9092,hadoop14:9092
a1.sources.r1.kafka.topics = topic_start
## source2
a1.sources.r2.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r2.batchSize = 5000
a1.sources.r2.batchDurationMillis = 2000
a1.sources.r2.kafka.bootstrap.servers = hadoop12:9092,hadoop13:9092,hadoop14:9092
a1.sources.r2.kafka.topics=topic_event
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /export/servers/flume/checkpoint/behavior1
a1.channels.c1.dataDirs = /export/servers/flume/data/behavior1/
a1.channels.c1.maxFileSize = 2146435071
a1.channels.c1.capacity = 1000000
a1.channels.c1.keep-alive = 6
a1.channels.c2.type = file
a1.channels.c2.checkpointDir = /export/servers/flume/checkpoint/behavior2
a1.channels.c2.dataDirs = /export/servers/flume/data/behavior2/
a1.channels.c2.maxFileSize = 2146435071
a1.channels.c2.capacity = 1000000
a1.channels.c2.keep-alive = 6
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /origin_data/gmall/log/topic_start/%Y-%m-%d
a1.sinks.k1.hdfs.filePrefix = logstart-
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = second
a1.sinks.k2.type = hdfs
a1.sinks.k2.hdfs.path = /origin_data/gmall/log/topic_event/%Y-%m-%d
a1.sinks.k2.hdfs.filePrefix = logevent-
a1.sinks.k2.hdfs.round = true
a1.sinks.k2.hdfs.roundValue = 10
a1.sinks.k2.hdfs.roundUnit = second
## 不要产生大量小文件
a1.sinks.k1.hdfs.rollInterval = 10
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k2.hdfs.rollInterval = 10
a1.sinks.k2.hdfs.rollSize = 134217728
a1.sinks.k2.hdfs.rollCount = 0
## 控制输出文件是原生文件。
a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k2.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.codeC = lzop
a1.sinks.k2.hdfs.codeC = lzop
## 拼装
a1.sources.r1.channels = c1
a1.sinks.k1.channel= c1
a1.sources.r2.channels = c2
a1.sinks.k2.channel= c2

Flume内存优化
1.问题描述:如果启动消费Flume抛出如下异常
ERROR hdfs.HDFSEventSink: process failed
java.lang.OutOfMemoryError: GC overhead limit exceeded
2.解决方案步骤:
(1)在hadoop12服务器的/export/servers/flume/conf/flume-env.sh文件中增加如下配置
export JAVA_OPTS="-Xms100m -Xmx2000m -Dcom.sun.management.jmxremote"
(2)同步配置到hadoop13、hadoop14服务器
xsync flume-env.sh
3.Flume内存参数设置及优化
JVM heap一般设置为4G或更高,部署在单独的服务器上(4核8线程16G内存)
-Xmx与-Xms最好设置一致,减少内存抖动带来的性能影响,如果设置不一致容易导致频繁fullgc。
Flume组件
1.FileChannel和MemoryChannel区别
MemoryChannel传输数据速度更快,但因为数据保存在JVM的堆内存中,Agent进程挂掉会导致数据丢失,适用于对数据质量要求不高的需求。
FileChannel传输速度相对于Memory慢,但数据安全保障高,Agent进程挂掉也可以从失败中恢复数据。
选型:
金融类公司、对钱要求非常准确的公司通常会选择 FileChannel
传输的是普通日志信息(京东内部一天丢 100 万-200 万条,这是非常正常的),通常 选择 MemoryChannel。
2.FileChannel 优化
通过配置 dataDirs 指向多个路径,每个路径对应不同的硬盘,增大 Flume 吞吐量。
官方说明如下:
Comma separated list of directories for storing log files. Using multiple directories on separate disks can improve file channel peformance
checkpointDir 和 backupCheckpointDir 也尽量配置在不同硬盘对应的目录中,保证 checkpoint 坏掉后,可以快速使用 backupCheckpointDir 恢复数据
3.Sink:HDFS Sink
(1)HDFS 存入大量小文件,有什么影响?
元数据层面:每个小文件都有一份元数据,其中包括文件路径,文件名,所有者,所属组,权限,创建时间等,这些信息都保存在 Namenode 内存中。所以小文件过多,会占用 Namenode 服务器大量内存,影响 Namenode 性能和使用寿命
计算层面:默认情况下 MR 会对每个小文件启用一个 Map 任务计算,非常影响计算性
能。同时也影响磁盘寻址时间。
(2)HDFS 小文件处理
官方默认的这三个参数配置写入 HDFS 后会产生小文件, hdfs.rollInterval、 hdfs.rollSize、 hdfs.rollCount
基于以上 hdfs.rollInterval=3600,hdfs.rollSize=134217728,hdfs.rollCount=0 几个参数综合作用,效果如下:
(1)文件在达到 128M 时会滚动生成新文件
(2)文件创建超 3600 秒时会滚动生成新文件
日志消费Flume启动停止脚本
(1)在/usr/local/bin 目录下创建脚本 f2.sh
vim f2.sh
在脚本中填写如下内容
#! /bin/bash
case $1 in
"start"){
for i in hadoop14
do
echo " --------启动 $i 消费flume-------"
ssh $i "nohup /export/servers/flume/bin/flume-ng agent --conf-file /export/servers/flume/conf/kafka-flume-hdfs.conf --name a1 -Dflume.root.logger=INFO,LOGFILE >/export/servers/flume/log.txt 2>&1 &"
done
};;
"stop"){
for i in hadoop14
do
echo " --------停止 $i 消费flume-------"
ssh $i "ps -ef | grep kafka-flume-hdfs | grep -v grep |awk '{print \$2}' | xargs kill"
done
};;
esac
(2)增加脚本执行权限
chmod 777 f2.sh
(3)f2 集群启动脚本
f2.sh start
(4)f2 集群停止脚本
f2.sh stop
采集通道启动/停止脚本
(1)在/usr/local/bin 目录下创建脚本 cluster.sh
#! /bin/bash
case $1 in
"start"){
echo " -------- 启动 集群 -------"
echo " -------- 启动 hadoop集群 -------"
/export/servers/hadoop-2.7.7/sbin/start-dfs.sh
ssh hadoop13 "/export/servers/hadoop-2.7.7/sbin/start-yarn.sh"
#启动 Zookeeper集群
zk.sh start
sleep 4s;
#启动 Flume采集集群
f1.sh start
#启动 Kafka采集集群
kf.sh start
sleep 6s;
#启动 Flume消费集群
f2.sh start
};;
"stop"){
echo " -------- 停止 集群 -------"
#停止 Flume消费集群
f2.sh stop
#停止 Kafka采集集群
kf.sh stop
sleep 6s;
#停止 Flume采集集群
f1.sh stop
#停止 Zookeeper集群
zk.sh stop
echo " -------- 停止 hadoop集群 -------"
ssh hadoop13 "/export/servers/hadoop-2.7.7/sbin/stop-yarn.sh"
/export/servers/hadoop-2.7.7/sbin/stop-dfs.sh
};;
esac
(2)增加脚本执行权限
chmod 777 cluster.sh
(3)f2 集群启动脚本
cluster.sh start
(4)f2 集群停止脚本
cluster.sh stop
Flume消费Kafka到HDFS上-HDFS上没有
尽量不用脚本启动,单独在hadoop14集群上启动
前提Flume==>Kafka是畅通的
解决方案:再次lg.sh==>f1.sh start==>在hadoop14启动 就能消费到了
如果还是不行在/kafka/conf/server.properties 改成3