1.什么是数据挖掘
数据挖掘是在大型数据存储库中,自动地发现有用信息的过程。
数据挖掘技术用来探查大型数据库,发现先前未知的有用模式。数据挖掘还可以预测未来观测结果。
并非所有的信息发现任务都被视为数据挖掘。例如,使用数据库管理系统查找个别的记录,或通过因特网的搜索引擎查找特定的Web页面,则是信息检索(information retrieval)领域的任务。虽然这些任务非常重要,可能涉及使用复杂的算法和数据结构,但是它们主要依赖传统的计算机科学技术和数据的明显特征来创建索引结构,从而有效地组织和检索信息。尽管如此,人们也在利用数据挖掘技术增强信息检索系统的能力。
数据挖掘与知识发现
数据挖掘是数据库中知识发现(knowledge discovery in database,KDD)不可缺少的一部分,而KDD是将未加工的数据转换为有用信息的整个过程,如图1所示。该过程包括一系列转挨步骤,从数据的预处理到数据挖掘结果的后处理。

输入数据可以以各种形式存储(平展文件、电子数据表或关系表),并且可以驻留在集中的数据存储库中,或分布在多个站点上。数据预处理(preprocessing)的目的是将未加工的输入数据转换成适合分析的形式。数据预处理涉及的步骤包括融合来自多个数据源的数据,清洗数据以消除噪声和重复的观测值,选择与当前数据挖掘任务相关的记录和特征。由于收集和存储数据的方式多种多样,数据预处理可能是整个知识发现过程中最费力、最耗时的步骤。
“结束循环”(closing the loop)通常指将数据挖掘结果集成到决策支持系统的过程。例如在商业应用中,数据挖掘的结果所揭示的规律可以结合商业活动管理工具,从而开展或测试有效的商品促销活动。这样的结合需要后处理(postprocessing)步骤,确保只将那些有效的和有用的结果集成到决簧支持系统中。后处理的一个例子是可视化,它使得数据分析者可以从各种不同的视角探查数据和数据挖掘结果。在后处理阶段,还能使用统计度量或假设检验,删除虚假的数据挖掘结果。
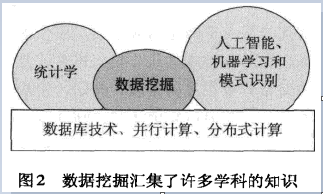
图2展示数据挖掘与其他领域之间的联系。
2.数据挖掘要解决的问题
(1)可伸缩。由于数据产生和收集技术的进步,数吉字节、数太字节甚至数拍字节的数据集越来越普遍。如果数据挖掘算法要处理这些海量数据集,则算法必须是可伸缩的(scalable)。许多数据挖掘算法使用特殊的搜索策略处理指数级搜索问题。为实现可伸缩可能还需要实现新的数据结构,才能以有效的方式访问每个记录。例如,当要处理的数据不能放进内存时,可能需要非内存算法。使用抽样技术或开发并行和分布算法也可以提高可伸缩程度。
(2)高维性。现在,常常遇到具有成百上千属性的数据集,而不是几十年前常见的只具有少量属性的数据集。在生物信息学领域,微阵列技术的进步已经产生了涉及数千特征的基因表达数据。具有时间或空间分量的数据集也经常具有很高的维度。例如,考虑包含不同地区的温度测量结果的数据集,如果在一个相当长的时间周期内反复地测量,则维度(特征数)的增长正比于测量的次数。为低维数据开发的传统的数据分析技术通常不能很好地处理这样的高维数据。此外,对于某些数据分析算法,随着维度(特征数)的增加,计算复杂性迅速增加。
(3)异种数据和复杂数据。通常,传统的数据分析方法只处理包含相同类型属性的数据集,或者是连续的,或者是分类的。随着数据挖掘在商务、科学、医学和其他领域的作用越来越大,越来越需要能够处理异种属性(包含不同类型属性、非连续、未分类等)的技术。近年来,已经出现了更复杂的数据对象。这些非传统的数据类型的例子有:含有半结构化文本和超链接的web页面集、具有序列和三维结构的DNA数据、包含地球表面不同位置上的时间序列测量值(温度、气压等)的气象数据。为挖掘这种复杂对象而开发的技术应当考虑数据中的联系,如时间和空间的自相关性、图的连通性、半结构化文本和XML文档中元素之间的父子联系。
(4)数据的所有权与分布。有时,需要分析的数据并非存放在一个站点,或归属一个机构,而是地理上分布在属于多个机构的资源中。这就需要开发分布式数据挖掘技术。分布式数据挖掘算法面临的主要挑战包括:(1)如何降低执行分布式计算所需的通信量?(2)如何有效地统一从多个资源得到的数据挖掘结果?(3)如何处理数据安全性问题?
(5)非传统的分析。传统的统计方法基于一种假设-检验模式,即提出一种假设,设计实验来收集数据,然后针对假设分析数据。但是,这一过程劳力费神。当前的数据分析任务常常需要产生和评估数千种假设,因此需要自动地产生和评估假设,这促使人们开发了一些数据挖掘技术。此外,数据挖掘所分析的数据集通常不是精心设计的实验的结果,并且它们通常代表数据的时机性样本(opportunistic sample),而不是随机样本(random sample)。而且,这些数据集常常涉及非传统的数据类型和数据分布。
3.数据挖掘任务
通常,数据挖掘任务分为下面两大类。
- 预测任务。这些任务的目标是根据其他属性的值,预测特定属性的值。被预测的属性般称目标变量(target variable)或因变量(dependent variable),而用来做预测的属性称说明变量(explanatory variable)或自变量(independent variable)
- 描述任务。其目标是导出概括数据中潜在联系的模式(相关、趋势、聚类、轨迹和异常)。
本质上,描述性数据挖掘任务通常是探查性的,并且常常需要后处理技术验证和解释结果。
图3展示四种主要的数据挖掘任务。

(1)预测建模(predictive modeling)涉及以说明变量函数的方式为目标变量建立模型。有两类预测建模任务:
- 分类(classification),用于预测离散的目标变量;
- 回归(regression),用于预测连续的目标变量。
例如,预测一个web用户是否会在网上书店买书是分类任务,因为该目标变量是二值的,而预测某股票的未来价格则是回归任务,因为价格具有连续值属性。两项任务目标都是训练一个模型,使目标变量预测值与实际值之间的误差达到最小。预测建模可以用来确定顾客对产品促销活动的反应,预测地球生态系统的扰动,或根据检查结果判断病人是否患有某种疾病。
(2)关联分析(association analysis) 用来发现描述数据中强关联特征的模式。所发现的模式通常用蕴涵规则或特征子集的形式表示。由于搜索空间是指数规模的,关联分析的目标是以有效的方式提取最有趣的模式。
关联分析的应用:找出具有相关功能的基因组、识别用户一起访问的Web页面、理解地球气候系统不同元素之间的联系等。
(3)聚类分析(cluster-analysis) 并在发现紧密相关的观测值组群,使得与属于不同簇的观测值相比,属于同一族的观测值相互之间尽可能类似。
聚类分析的应用:对相关的顾客分组、找出显著影响地球气候的海洋区域以及压缩数据等。
(4)异常检测(anomaly.detection)的任务是识别其特征显著不同于其他数据的观测值。这样的观测值称为异常点(anomaly)或离群点(outlier)。异常检测算法的目标是发现真正的是赏点,而避免错误地将正常的对象标注为异常点.换言之,一个好的异常检测器必须具有高检测率和低误报率。
异常检测的应用:检测欺诈、网络攻击、疾病的不寻常模式、生态系统扰动等。
参考材料:《Introduction to Data Mining》 written Pang-Ning Tan, Michael Steinbach, Vipin Kumar, etc.