数据监控平台
监控平台需要实时监控业务指标数据,系统特点:高并发,大数据,低延迟。主要使用的技术:
HBase存储海量数据,ScriptEngine引擎,MySQL分表,Redis集群。
- 高并发:系统调用量大,特别是大促期间,需要保证系统高可用
- 大数据:监控平台需要存储海量数据,包括历史数据,用于数据分析
- 低延迟:快速消费消息,保证监控数据无延迟。
数据实时监控-无延迟
在高并发下会有数据丢失,为提示系统吞吐量,在调用RPC失败时,接入方不会重试。
- 接入方调用RPC服务
- 实时存储数据

数据实时监控-有延迟
监控平台监听接入方的MQ消息,进行数据存储。数据不会丢失,但MQ消息会有延迟,监控的数据会有稍微的延迟。
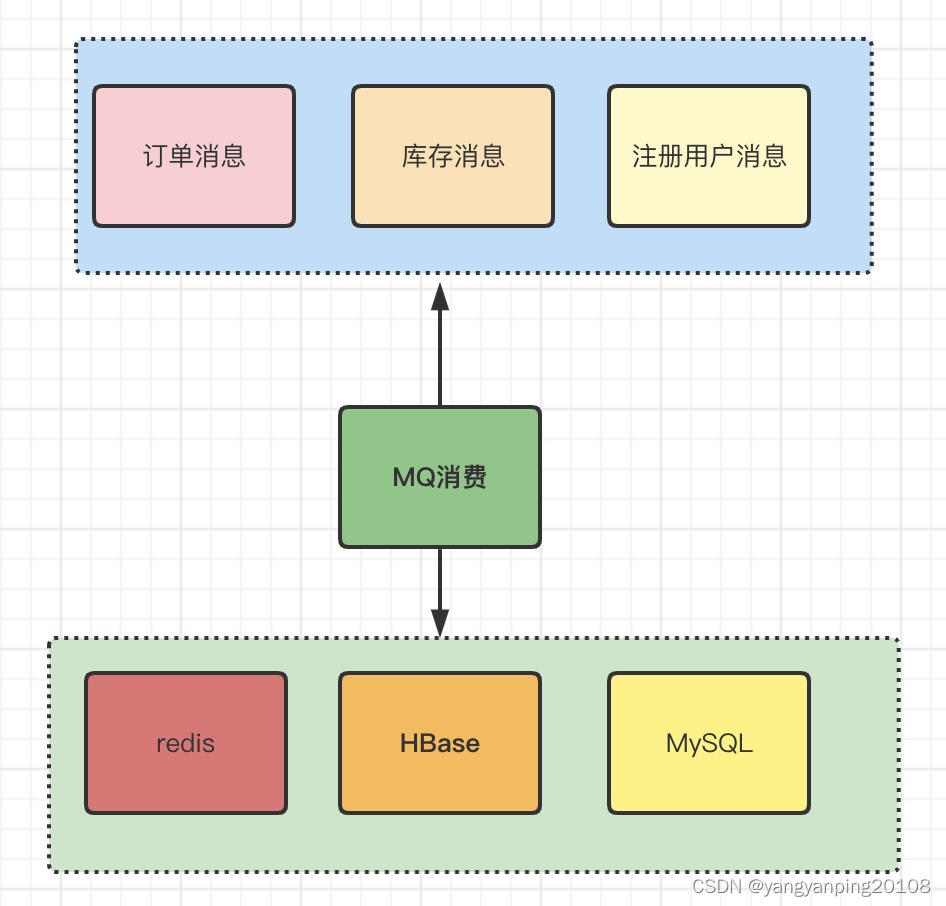
数据流转
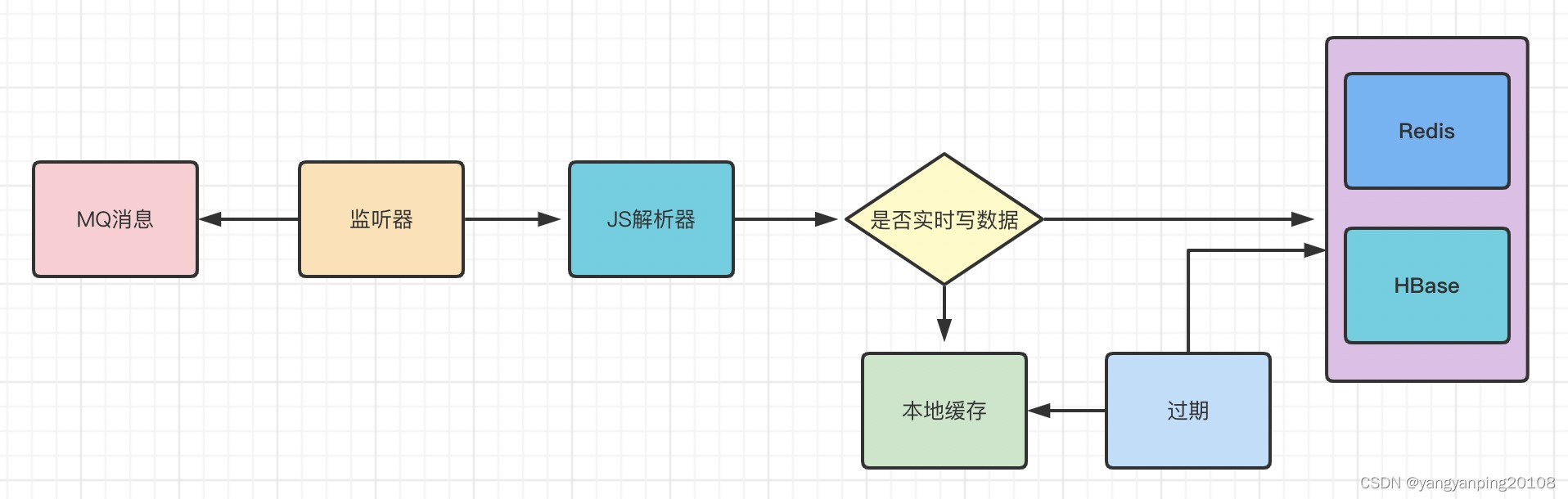
核心设计
Guava Cache
Guava Cache是单个应用运行时的本地缓存。它不把数据存放到文件或外部服务器。在重启服务器时缓存的数据会全部丢失。如果这不符合你的需求,请尝试Redis或Memcached这类工具。
优点:
①很好的封装了get、put操作,能够集成数据源。一般我们在业务中操作缓存,都会操作缓存和数据源两部分。如:put数据时,先插入DB,再删除原来的缓存;ge数据时,先查缓存,命中则返回,没有命中时,需要查询DB,再把查询结果放入缓存中。 guava cache封装了这么多步骤,只需要调用一次get/put方法即可。
②线程安全的缓存,与ConcurrentMap相似,但前者增加了更多的元素失效策略,后者只能显示的移除元素。
③Guava Cache提供了三种基本的缓存回收方式:基于容量回收、定时回收和基于引用回收。定时回收有两种:按照写入时间,最早写入的最先回收;按照访问时间,最早访问的最早回收。
④监控缓存加载/命中情况。
缓存回收方式
a. 基于容量回收
maximumSize(long):当缓存中的元素数量超过指定值时。
b. 定时回收
expireAfterAccess(long, TimeUnit):缓存项在给定时间内没有被读/写访问,则回收。请注意这种缓存的回收顺序和基于大小回收一样。
expireAfterWrite(long, TimeUnit):缓存项在给定时间内没有被写访问(创建或覆盖),则回收。如果认为缓存数据总是在固定时候后变得陈旧不可用,这种回收方式是可取的。
如下文所讨论,定时回收周期性地在写操作中执行,偶尔在读操作中执行。
c. 基于引用回收(Reference-based Eviction)
CacheBuilder.weakKeys():使用弱引用存储键。当键没有其它(强或软)引用时,缓存项可以被垃圾回收。
CacheBuilder.weakValues():使用弱引用存储值。当值没有其它(强或软)引用时,缓存项可以被垃圾回收。
CacheBuilder.softValues():使用软引用存储值。软引用只有在响应内存需要时,才按照全局最近最少使用的顺序回收。
通过官方wiki:CachesExplained · google/guava Wiki · GitHub ,具体如下
Caches built with CacheBuilder do not perform cleanup and evict values "automatically,"
or instantly after a value expires, or anything of the sort. Instead, it performs small amounts
of maintenance during write operations, or during occasional read operations if writes are rare.
The reason for this is as follows: if we wanted to perform Cache maintenance continuously, we would
need to create a thread, and its operations would be competing with user operations for shared locks.
Additionally, some environments restrict the creation of threads, which would make CacheBuilder
unusable in that environment.
Instead, we put the choice in your hands. If your cache is high-throughput, then you don't have to
worry about performing cache maintenance to clean up expired entries and the like. If your cache
does writes only rarely and you don't want cleanup to block cache reads, you may wish to create
your own maintenance thread that calls Cache.cleanUp() at regular intervals.
If you want to schedule regular cache maintenance for a cache which only rarely has writes,
just schedule the maintenance using ScheduledExecutorService.
从上面这段说明中,我们知道一下几点:
使用CacheBuilder构建的Cahe不会“自动”执行清理数据,或者在数据过期后,立即执行清除操作。相反,它在写操作期间或偶尔读操作期间执行少量维护(如果写很少)。
这样做的原因如下:
如果我们想要连续地执行缓存维护,我们需要创建一个线程,它的操作将与共享锁的用户操作发生竞争。此外,一些环境限制了线程的创建,这会使CacheBuilder在该环境中不可用。
简单来说,GuavaCache 并不保证在过期时间到了之后立刻删除该 <Key,Value>,如果你此时去访问了这个 Key,它会检测是不是已经过期,过期就删除它,所以过期时间到了之后你去访问这个 Key 会显示这个 Key 已经被删除,但是如果你不做任何操作,那么在 过期时间到了之后也许这个<Key,Value> 还在内存中。
POM依赖
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>30.1-jre</version>
</dependency>代码演示
秒级监控 duration = 100ms
分钟级监控 duration = 700ms
import com.google.common.cache.*;
import java.util.concurrent.TimeUnit;
public class GuavaTest {
public static void main(String[] args) throws Exception {
LoadingCache<String, Integer> cache = CacheBuilder.newBuilder()
//.expireAfterWrite(100, TimeUnit.MICROSECONDS)
//.expireAfterAccess(100, TimeUnit.MICROSECONDS)
.refreshAfterWrite(100, TimeUnit.MILLISECONDS) //当缓存项上一次更新操作之后的多久会被刷新。
.initialCapacity(500)
//设置缓存最大容量为500,超过500之后就会按照LRU最近虽少使用算法来移除缓存项
.maximumSize(1000)
//设置要统计缓存的命中率
.removalListener(new RemovalListener<Object, Object>() {
@Override
public void onRemoval(RemovalNotification<Object, Object> removal) {
System.out.println("loadingCache is removed. key:" + removal.getKey() + ",value:" + removal.getValue());
}
})
.build(new CacheLoader<String, Integer>() {
@Override
public Integer load(String s) throws Exception {
System.out.println("load exprie=" + s);
return 1;
}
});
cache.put("monitor_order_1_20220729090001", 100);
System.out.println(cache.size());
Thread.sleep(1000);
if (cache != null && cache.size() > 0) {
for (String key : cache.asMap().keySet()) {
System.out.println(key);
cache.get(key);
}
}
}
}HBase 设计
读写性能:Hbase采用了LSM结构,写快读慢,Hbase读延时在一般在几毫秒,Redis读延时在几十微秒,性能相差比较大
数据量:Redis在热数据比内存大时,性能下降比较厉害,非常依赖内存,Hbase不存在这问题
数据持久化:Hbase采用了WAL,先记录日志再写入数据,理论上不会丢失数据,而Redis采用的是异步复制数据,failover时可能丢失数据
用Hbase+Redis实现数据仓库加缓存数据库,速度和扩展性都兼顾

RowKey设计
| 分类 | RowKey | 总数 |
| 秒级 | monitor_name(业务名称)_type(业务数据类型)_yyyyMMddHHMMss | count |
| 分钟级 | monitor_name(业务名称)_type(业务数据类型)_yyyyMMddHHMM | count |
ScriptEngineManager
ScriptEngineManager 为 ScriptEngine 类实现一个发现和实例化机制,还维护一个键/值对集合来存储所有 Manager 创建的引擎所共享的状态。此类使用服务提供者机制枚举所有的 ScriptEngineFactory 实现。
ScriptEngineManager 提供了一个方法,可以返回一个所有工厂实现和基于语言名称、文件扩展名和 mime 类型查找工厂的实用方法所组成的数组。
键/值对的 Bindings(即由管理器维护的 "Global Scope")对于 ScriptEngineManager 创建的所有 ScriptEngine 实例都是可用的。Bindings 中的值通常公开于所有脚本中。
package com.example;
import javax.script.Invocable;
import javax.script.ScriptEngine;
import javax.script.ScriptEngineManager;
public class ScriptEngineTest {
public static void main(String[] args) throws Exception {
ScriptEngineManager manager = new ScriptEngineManager();
//查找并创建一个给定名称的 ScriptEngine
ScriptEngine engine = manager.getEngineByName("js");
//执行指定的脚本
engine.eval("function add (a, b) {c = a + b; return c; }");
//由 ScriptEngines 实现的可选接口,该 ScriptEngines 的方法允许在以前执行过的脚本中调用程序
Invocable jsInvoke = (Invocable) engine;
//用于调用脚本中定义的顶层程序和函数
Object result1 = jsInvoke.invokeFunction("add", new Object[]{10, 5});
System.out.println("result1=" + result1);
Adder adder = jsInvoke.getInterface(Adder.class);
int result2 = adder.add(10, 5);
System.out.println("result2=" + result2);
}
public interface Adder {
int add(int a, int b);
}
}监控表
QPS:每秒查询率,是一台服务器每秒能够响应的查询次数,是对一个特定的查询服务器在规定时间内所处理流量衡量标准
TPS:每秒事务数,是一台数据库服务器在单位时间内处理的事务的个数
最大连接数:通常MySQL的最大连接数默认是151 最大可以达到16384。实际连接数是最大连接数的85%较为合适,所以最大连接数我们可以根据实际连接数去设置(如果你想设置最大连接数超过1024,还需要修改文件描述符的上限)
测试参数
| 实例规格 | 存储空间 | 表数量 | 表行数 | 数据集大小 | 并发数 | 执行时间(m) |
|---|---|---|---|---|---|---|
| 1核1GB | 200GB | 4 | 2000万 | 19GB | 128 | 30 |
| 1核2GB | 200GB | 4 | 4000万 | 38GB | 128 | 30 |
| 2核4GB | 200GB | 8 | 4000万 | 76GB | 128 | 30 |
| 4核8GB | 200GB | 15 | 4000万 | 142GB | 128 | 30 |
| 4核16GB | 400GB | 25 | 4000万 | 238GB | 128 | 30 |
| 8核32GB | 700GB | 25 | 4000万 | 238GB | 128 | 30 |
| 16核64GB | 1TB | 40 | 4000万 | 378GB | 256 | 30 |
| 16核96GB | 1.5TB | 40 | 4000万 | 378GB | 128 | 30 |
| 16核128GB | 2TB | 40 | 4000万 | 378GB | 128 | 30 |
| 24核244GB | 3TB | 60 | 4000万 | 567GB | 128 | 30 |
| 48核488GB | 6TB | 60 | 4000万 | 567GB | 128 | 30 |
| 48核488GB(调优) | 6TB | 60 | 1000万 | 140GB | 128 | 30 |
测试结果
| 实例规格 | 存储空间 | 数据集 | 客户端数 | 单客户端并发数 | QPS | TPS |
|---|---|---|---|---|---|---|
| 1核1GB | 200GB | 19GB | 1 | 128 | 1757 | 97 |
| 1核2GB | 200GB | 38GB | 1 | 128 | 3016 | 167 |
| 2核4GB | 200GB | 76GB | 1 | 128 | 4082 | 816 |
| 4核8GB | 200GB | 142GB | 1 | 128 | 6551 | 1310 |
| 4核16GB | 400GB | 238GB | 1 | 128 | 11098 | 2219 |
| 8核32GB | 700GB | 238GB | 2 | 128 | 20484 | 3768 |
| 16核64GB | 1TB | 378GB | 2 | 128 | 36395 | 7279 |
| 16核96GB | 1.5TB | 378GB | 3 | 128 | 56464 | 11292 |
| 16核128GB | 2TB | 378GB | 3 | 128 | 81752 | 16350 |
| 24核244GB | 3TB | 567GB | 4 | 128 | 98528 | 19705 |
| 48核488GB | 6TB | 567GB | 6 | 128 | 142246 | 28449 |
| 48核488GB(调优) | 6TB | 140GB | 6 | 128 | 245509 | 46304 |
参考:Mysql性能指标(QPS、TPS)_武壮的博客-CSDN博客_mysql qps tps
https://www.jianshu.com/p/b51c4d5bdfc4
monitor_seconds_202207
| 列明 | 类型 | 是否主键 | 是否为空 |
|---|---|---|---|
| id | BIGINT | 是 | 否 |
| date | VARCHAR(16) | ||
| name | VARCHAR(32) | ||
| type | INT | ||
| minutes | INT | ||
| count | BIGINT | ||
| create_time | DATETIME | ||
| modified_time | DATETIME |
monitor_minutes_202207
| 列明 | 类型 | 是否主键 | 是否为空 |
|---|---|---|---|
| id | BIGINT | 是 | 否 |
| date | VARCHAR(16) | ||
| name | VARCHAR(32) | ||
| type | INT | ||
| minutes | INT | ||
| count | BIGINT | ||
| create_time | DATETIME | ||
| modified_time | DATETIME |
Redis
OPS : redis中的OPS 即operation per second 每秒操作次数。意味着每秒对Redis的持久化操作。
数据包 : 控制好数据包大小,高性能网络通信最忌收发大量小包,控制在1400字节附近最佳,最差也要pipeline。
Redis 采用集群部署,多个分片(如:16个分片),每个分片内存10G。每个分片的OPS 大约 5W,则16个分片可以支持 80W的OPS。