丰富的统计检验方法
前言
估计和检验是统计学上最常见的两种分析手段。参数估计主要两大类为点估计和区间估计,这里面具体涉及的方法很多。本文主要描述的内容是关于检验方面的。假设检验的着重点在于检验参数的取值是否等于某个目标值。

一:假设检验的背景知识简介
- 两类思想
1:小概率事件:小概率事件是指在一次独立实验中几乎不可能发生的事件,如果在我们的假设下出现了小概率事件,那么就可以认为我们的假设是错误的,
2:反证法思想:先假设我们提出的假设是正确的,然后在该条件下检验观测到的事件是不是小概率事件。如果是,那么就可以否定我们的假设;否则,我们就无法否定。
- 假设检验步骤总结
1:先根据实际情况的要求提出一个论断,称为原假设或零假设,记为 H 0 H_0 H0 。同时提出一个互为反命题的备择假设,记为 H 1 H_1 H1 ,
2:在 H 0 H_0 H0 正确的条件下,求出样本数据出现的概率,看已知的样本是不是小概率事件,
3:如果样本是小概率事件,那么就认为原假设错误,即拒绝原假设,否则就是接受原假设。
4:对于原假设和备择假设假设的选择原则:(1).原假设应该是受保护的,不能轻易被拒绝;(2).备择假设是检验者所希望的结果;(3).等号永远出现在原假设中。
- 两类错误
1:第一类错误:即弃真错误。尽管小概率事件很难发生,但毕竟概率不为 0 0 0,也许原假设是正确的,但根据小概率事件原则,我们拒绝了原假设,犯第一类错误的概率为 α \alpha α ,
2:第二类错误:即取伪错误。也就是说,在假设检验中我们没有拒绝原本是错误的原假设,因为有时候原假设尽管是错误的,但非常接近真实值,犯第二类错误的概率为 β \beta β ,
3:错误权衡:如果我们想要降低 α \alpha α 的概率,也就是意味着提高拒绝条件,使得原假设不那么容易被拒绝,但与此同时,错误的原假设也不容易被拒绝,相当于提高了 β \beta β 值,所以二者不可能同时降低的。一般来说我们是控制 α \alpha α 而放任 β \beta β 。
- 显著性水平 α \alpha α 与 p p p 值
为了控制 $\alpha4 ,我们往往将 α \alpha α 的值固定,用条件概率表示为:
P ( 拒 绝 H 0 ∣ H 0 为 真 ) ≤ α P\left( 拒绝H_0|H_0为真 \right)\leq\alpha P(拒绝H0∣H0为真)≤α ,对于 α \alpha α 取值我们有 α = 0.1 \alpha =0.1 α=0.1, 0.05 0.05 0.05或者 0.01 0.01 0.01。
关于 p p p 值的解释,这里主要是对“更极端”事件出现的概率进行量化。比如原假设总体均值为 10 10 10,样本的均值为 9 9 9,样本均值原假设的差即为 − 1 -1 −1。那么“更极端”的情况就是指均值和 10 10 10的差大于 1 1 1或者小于 − 1 -1 −1的样本。我们于是把所得到的样本或者更极端的情况出现的概率叫做 p p p 值。
- 确定小概率事件
判定一个事件是否为小概率事件的基本原则就是:当 p p p 值小于等于 α \alpha α 时,我们的样本为小概率事件,而对于这两个值的比较,我们可以采用临界值检验法和显著性检验法!
1:临界值检验法:简单来说就是根据样本构造合适的统计量后,根据 α \alpha α 和统计量所服从的概率分布求得临界值,一般临界值都满足一个特性,那就是 p = α p=\alpha p=α ,求得临界值后,可以将统计量与该临界值进行比较。如果统计量与原假设的偏差大于等于临界值与原假设的偏差,那么当前样本就与临界值一样极端或者更极端,其 p p p 值也就会小于等于 α \alpha α ,所以我们就认为当前样本为小概率事件,从而拒绝原假设。
2:显著性检验法:开始同样构建一个用于检验的统计量,与临界值法不同的是,我们直接根据原假设和统计量的概率分布求解其 p p p 值,然后将 p p p 值与 α \alpha α 进行比较,从而判定样本是否为小概率事件。
二:参数检验之 t t t 检验(主要用于样本含量较小(例如 n < 30 n < 30 n<30),总体标准差 σ σ σ未知的正态分布)
所谓参数检验,即构造的统计量或者总体分布服从一定的概率分布的情况下对总体参数(如均值、方差)推断。
- 单样本 t t t 检验
在总体服从正态分布 N ( μ , σ 2 ) N\left( \mu,\sigma^2 \right) N(μ,σ2) 的情况下,比较总体均值 μ \mu μ 是否与指定的检验
值 μ 0 \mu_0 μ0 存在显著性差异,原假设(双尾,如果是单尾原假设,即 μ 0 ≥ μ \mu_0\geq\mu μ0≥μ 或
μ 0 ≤ μ \mu_0\leq\mu μ0≤μ ,备择假设为互逆命题)为 H 0 : μ = μ 0 H_0:\mu=\mu_0 H0:μ=μ0 。如果样本
容量为 n n n ,样本均值为 X ˉ \bar{X} Xˉ ,在原假设成立的条件下,我们构建 t t t 检验统计量:
t = X ˉ − μ 0 s / n ∼ t ( n − 1 ) 其 中 s = 1 n − 1 ∑ i n ( x i − x ˉ ) 2 t=\frac{\bar{X}-\mu_0}{s/\sqrt{n}}\sim t(n-1) 其中 s=\sqrt{\frac{1}{n-1}\sum_{i}^{n}{\left( x_i-\bar{x} \right)^2}} t=s/nXˉ−μ0∼t(n−1)其中s=n−11∑in(xi−xˉ)2 为样本标准差。
得到统计量值后,我们便可根据 t t t 分布的分布函数计算出 p p p 值并与显著性水
平 α \alpha α 进行比较,或者与显著性水平 α \alpha α 下的临界值进行比较。
我们用Python实现这一过程:
import numpy as np
from scipy import stats
arr = np.array([10.1,10,9.8,10.5,9.5,10.1,9.9,10.2,10.3,9.9])
test_res = stats.ttest_1samp(arr,0)#原假设是收益率均值为0
##编写统计量值计算公式
mu = arr.mean()
mu = mu - 0
t = mu / (np.std(arr,ddof=1) / np.sqrt(len(arr)))
print(test_res)
print('公式得到的t统计量值:',t)
if test_res[1] < 0.05:
print('\033[1;32m原假设是收益率均值为0,由于p值为%s,小于显著性水平a=0.05,所以拒绝原假设,即收益率均值为0假设不成立!\033[0m'%test_res[1])
else:
print('\033[1;31m原假设是收益率均值为0,由于p值为%s,大于等于显著性水平a=0.05,所以接受原假设,即收益率均值为0假设成立!\033[0m' % test_res[1])
##根据概率分布手动计算p值(双尾)
p_value = (1 - stats.t.cdf(t, df=len(arr)-1)) * 2
print('手动计算P值:',p_value)
- 独立样本 t 检验
用于检验两个服从正态分布的总体均值是否存在显著性差异,假设两个总体分布分别为
N ( μ 1 , σ 1 2 ) 和 N ( μ 2 , σ 2 2 ) N\left( \mu_1,\sigma_1^2 \right) 和 N\left( \mu_2,\sigma_2^2 \right) N(μ1,σ12)和N(μ2,σ22) ,则原假设为 H 0 : μ 1 = μ 2 H_0:\mu_1=\mu_2 H0:μ1=μ2 ,由正态分布可加性
( x 1 + x 2 + . . . + x n ) ∼ N ( n μ , n σ 2 ) , 则 x ˉ ∼ N ( μ , σ 2 n ) (x_1+x_2+...+x_n)\sim N\left( n\mu,n\sigma^2 \right) ,则 \bar{x}\sim N\left( \mu,\frac{\sigma^2}{n} \right) (x1+x2+...+xn)∼N(nμ,nσ2),则xˉ∼N(μ,nσ2) ,则对于两独立
样本有 x 1 ˉ − x 2 ˉ ∼ N ( μ 1 − μ 2 , σ 1 2 n 1 + σ 2 2 n 2 ) \bar{x_1}-\bar{x_2}\sim N\left( \mu_1-\mu_2,\frac{\sigma_1^2}{n_1}+\frac{\sigma_2^2}{n_2} \right) x1ˉ−x2ˉ∼N(μ1−μ2,n1σ12+n2σ22) ,简化其中推导我们直接给出其检
验统计量为 ( x 1 ˉ − x 2 ˉ ) − ( μ 1 − μ 2 ) s p ( 1 n 1 + 1 n 2 ) ∼ t ( n 1 + n 2 − 2 ) \frac{(\bar{x_1}-\bar{x_2})-(\mu_1-\mu_2)}{\sqrt{s_p\left( \frac{1}{n_1}+\frac{1}{n_2} \right)}}\sim t(n_1+n_2-2) sp(n11+n21)(x1ˉ−x2ˉ)−(μ1−μ2)∼t(n1+n2−2) ,
这里的 s p = ( n 1 − 1 ) s 1 2 + ( n 2 − 1 ) s 2 2 n 1 + n 2 − 2 s_p=\frac{(n_1-1)s_1^2+(n_2-1)s_2^2}{n_1+n_2-2} sp=n1+n2−2(n1−1)s12+(n2−1)s22 为混合标准差。
同上“单样本方法”计算相应 p p p 值。
我们用Python实现这一过程:
arr1 = np.array([5,4,2,3,4,5,6,7,3])
arr2 = np.array([2,3,4,2,3,4])##两样本长度不必相等!!
res = stats.ttest_ind(arr1,arr2)
print(res)
- 配对样本 t 检验
当两样本并不互相独立时候,我们可以使用配对样本 t t t 检验对两个总体的均值差异进行检验。比如研究夫妻之间的人均消费差异,因为夫妻双方的人均消费水平并不是独立的,这时候我们只需要稍变变形一下,即用丈夫的消费水平减去妻子的消费水平的差值做单样本 t t t 检验即可。则建立的原假设
H 0 : d = μ 1 − μ 2 = 0 H_0:d=\mu_1-\mu_2=0 H0:d=μ1−μ2=0 ,其检验统计量为: t = d ˉ s d / n ∼ t ( n − 1 ) t=\frac{\bar{d}}{s_d/\sqrt{n}}\sim t(n-1) t=sd/ndˉ∼t(n−1) ,这里
要说明 d ˉ \bar{d} dˉ 为配对样本中各元素对应的差值, s d s_d sd 为差值的标准差, n n n 为配对数。
同上“单样本方法”计算相应 p p p 值。
我们用Python实现这一过程:
arr1 = np.array([5,4,2,3,4,5,6,7,3])##注意这时候的两个向量长度要求一致!!
arr2 = np.array([2,3,4,2,3,4,3,9,10])
res = stats.ttest_rel(arr1,arr2)
print(res)
三:参数检验之 z z z 检验(主要用于大样本(例如 n > 30 n > 30 n>30),总体标准差 σ σ σ已知的正态分布)
由于 z z z 检验和 t t t 检验原理很像,这里我们将简单介绍下其原理。样本容量越大,样本标准差接近总体标准差!
对于总体方差已知的样本情况,对单样本 z z z 检验,我们有统计量 z = x ˉ − μ σ / n z=\frac{\bar{x}-\mu}{\sigma/\sqrt{n}} z=σ/nxˉ−μ ,一般
原假设(双尾)还是设为 H 0 : μ = μ 0 H_0:\mu=\mu_0 H0:μ=μ0 ,双样本检测原理跟同理 t t t 检验。
我们简单用代码运用此方法:
import statsmodels.stats.weightstats as sw
arr1 = [23,36,42,34,39,34,35,42,53,28,49,39,46,45,39,38,45,27,43,54,36,34,48,36,47,44,48,45,44,33,24,40,50,32,39,31]
arr2 = [41, 34, 36, 32, 32, 35, 33, 31, 35, 34,37, 34, 31, 36, 37, 34, 33, 37, 33, 38,38, 37, 34, 36, 36, 31, 33, 36, 37, 35,33, 34, 33, 35, 34, 34, 34, 35, 35, 34]
###返回的元组形式,第一个值是统计量的值,第二个值是p值
print(sw.ztest(arr1, value=39, alternative='two-sided'))##其中value单样本时候,是样本假设的均值,默认双尾检验
print(sw.ztest(arr1,arr2, value=0))##其中value单样本时候,是两样本假设的均值之差
###根据概率分布求解p(双尾)
p_value = (1 - stats.norm.cdf(z检验统计量值)) * 2
四:参数检验之方差分析
方差分析主要研究的是一个因子对反应变量的影响。比如分析食品行和金融行业的股票收益率的差异,如果发现这两个行业的股票收益率有显著差异,则可有一下结论:行业是影响股票收益率的一个重要因素。
方差分析的目的在于分析因子对反应变量的有无显著影响,亦即因子的不同水平下反应变量的均值是否有显著差异。若因子水平对反应变量无影响,则不同因子水平下反应变量的均值是相同的,这也就是方差分析的原假设。
方差分析要满足以下两点:
1:样本是从服从正态分布的总体中独立抽取出来的,
2:不同反应变量的总体方差是大致相同的(方差一致性)。
接下来,我们简单概括一下方差分析的一般步骤:
1:根据感兴趣的因子的不同取值水平,将反应变量分为 M 个组,
2:提出原假设,即 H 0 : H_0: H0: 因子对于反应变量均值没有影响;备择假设 $H_1: $因子对于反应变量均值有影响,
3:求出样本数据中每组样本的平均值和全体样本的平均值,算出组内均方差 M S F MSF MSF和组间均方差 M S E MSE MSE,
4:构建统计量 φ = M S F M S E ∼ F ( M − 1 , N − M ) \varphi=\frac{MSF}{MSE}\sim F(M-1,N-M) φ=MSEMSF∼F(M−1,N−M) ,其中 F F F 为 F F F 分布,
5:由显著性水平 α \alpha α 的取值,查 F F F 分布表的临界值 F α ( M − 1 , N − M ) F_\alpha(M-1,N-M) Fα(M−1,N−M) 来判断是接受还是拒绝原假设。
- 单因素方差分析
比如我们列举的例子就是关于行业是否是影响股票收益率的一个重要因素。
from statsmodels.formula.api import ols
import statsmodels.stats.anova as no
import pandas as pd
return_ls = [0.57298,0.82757,0.33648,0.64532,0.47798,0.25123,0.00256,0.01125,0.75658,0.05654,0.95765,0.87851,0.99856,0.00245]
industry_ls = ['货币金融服务业','房地产行业','医药制造业','房地产行业','房地产行业','游戏业','农业','电影业','服务业','交通业','房地产行业','房地产行业','房地产行业','农业']
df1 = pd.DataFrame([return_ls,industry_ls],index=['Return','Industry']).T
data_new1 = df1.dropna()
data_new1['Return'] = data_new1['Return'].apply(pd.to_numeric)#强行转化为数值
model1 = ols('Return ~ C(Industry)',data_new1).fit()
table1 = no.anova_lm(model1)
print(table1)

由上图图1 p p p 值我们发现,对于因变量收益率,自变量行业确实是对因变量有显著影响的。
- 多因素方差分析(独立)
顾名思义,研究多个因子是否对因变量有重要影响,且每个因子影响对因变量的影响方向和程度是不一样的。
edu_ls = [13,18,3,5,8,12,3,8,12,15]
marr_ls = ['y','y','n','n','n','n','y','n','n','y']
ear_ls = [77005,85212,5264,10222,20013,31212,6451,18221,45613,56872]
df2 = pd.DataFrame([edu_ls,marr_ls,ear_ls],index=['education','married','earnings']).T
data_new2 = df2.dropna()
data_new2['earnings'] = data_new2['earnings'].apply(pd.to_numeric)
model2 = ols('earnings ~ C(education)+C(married)',data_new2).fit()
table2 = no.anova_lm(model2)
print(table2)

由上图图2我们发现,当研究两个变量是否对收入有影响时,我们发现教育和是否结婚影响程度是不一样的,教育是有显著影响的,而是否结婚是没有显著影响的。
- 析因素方差分析(非独立)
析因方差分析与多元素方差分析差不多,仅多了一个因子乘项。比如,在上面的例子中,我们可以添加married与education的乘项,以检验这两者对收入的影响是否与另一个因子水平有关。
model3 = ols('earnings ~ C(education)*C(married)',data_new2).fit()
table3 = no.anova_lm(model3)
print(table3)

由上面图3我们发现,第3个 p p p 值等于 0.05 > 0.5 0.05>0.5 0.05>0.5,即结果不显著,所以婚姻状况和受教育水平对收入的影响并不依赖于另一者的水平。
五:非参数检验之卡方检验
卡方检验(慎与跟卡方分布概念混淆)是一种用途很广的计数资料的假设检验方法。属于非参数检验,主要是比较两个及两个以上样本率(构成比)以及两个分类变量的关联性分析。根本思想在于比较理论频数和实际频数的吻合程度或者拟合优度问题。
接下来,我们简单概括一下卡方检验(特指拟合优度)的一般步骤:
1:建立独立样本联表,建立原假设 H 0 : H_0: H0:比如不吃晚饭对体重下降没有影响,或者喝牛奶对身体恢复没影响等等,

2:根据概率频次对四方联表进行理论值频数计算,

3:卡方检验统计量公式: χ 2 = ∑ i k ( f o − n p i ) 2 n p i \chi^2=\sum_{i}^{k}{\frac{\left( f_o-np_i \right)^2}{np_i}} χ2=∑iknpi(fo−npi)2 ,这里的 k k k 就是就是总体样本分
为 k k k 块,也就是 4 , n = 200 4, n= 200 4,n=200。根据拟合优度公式有 χ 2 = ( 95 − 55 ) 2 55 + ( 15 − 55 ) 2 55 \chi^2 = \frac{\left( 95-55 \right)^2}{55}+\frac{\left( 15-55 \right)^2}{55} χ2=55(95−55)2+55(15−55)2
+ ( 85 − 45 ) 2 45 + ( 5 − 45 ) 2 45 = 129.3 +\frac{\left( 85-45 \right)^2}{45}+\frac{\left( 5-45 \right)^2}{45}=129.3 +45(85−45)2+45(5−45)2=129.3
4:根据自由度计算公式: v = ( 行 数 − 1 ) ( 列 数 − 1 ) v=(行数-1)(列数-1) v=(行数−1)(列数−1) 以及 χ 2 \chi^2 χ2 临界表、拟合优度值,我们可查到 p p p ,
5:根据 p p p 值的取值的大小来确定是否拒绝原假设。
我们用直接调用Python里的方法走一遍上面的过程。
from scipy.stats import chi2_contingency
df = pd.DataFrame({
'medical':['A','A','B','B','C','C'],
'cured':[1,0,1,0,1,0],
'count':[1800,200,600,1200,500,200]
})
print('\033[1;31m原始表:\033[0m')
print(df)
cross_tab = pd.pivot_table(data=df,values='count',index='medical',columns='cured',margins=True,aggfunc=np.sum)
print('\033[1;32m联表:\033[0m')
print(cross_tab)
kf = chi2_contingency(cross_tab)
print('chisq-statistic=%.2f, p-value=%.6f, df=%s expected_frep=%s'%kf)

从上图图4的 p 值,我们可以发现不同药对治疗效果是有关系的。
PS:卡方检验的结果非常受数据量级的影响,实际运用中要注意!!!
六:非参数检验之Kruskal-Wallis检验
在实际生产中,经常比较多组独立数据均值(或者分布)之间的差异性,然而实际数据很难符合正态性,基本都是偏态性,这时很难用参数检验进行分析。作为对样本分布没有太大要求的Kruskal-Wallis(简称克氏)检验,它是一个将两个独立样本Wilcoxon(Mann-Whitney)推广到3个或者更多组的检验。
接下来,我们简单概括一下Kruskal-Wallis检验的一般步骤
1:对于分布是否相同的检验的原假设可以设为 H 0 : F 1 ( x ) = F 2 ( x ) = . . . = F k ( x ) H_0:F_1(x)=F_2(x)=...=F_k(x) H0:F1(x)=F2(x)=...=Fk(x) ,这里的 k k k 为是独立样本的个数, F F F 是分布函数的意思,那么备择假设 H 1 : F H_1: F H1:F 中至少两个不相等, 对于位置参数(均值、中位数等)的原假设 H 0 : θ 1 = θ 2 = . . . = θ k H_0:\theta_1=\theta_2=...=\theta_k H0:θ1=θ2=...=θk ,备择假设同理,
2:构造检验统计量 H = 12 N ( N + 1 ) ∑ i k n i ( R ˉ j − R ˉ ) 2 H=\frac{12}{N(N+1)}\sum_{i}^{k}{n_i\left(\bar{R}_j-\bar{R} \right)^2} H=N(N+1)12∑ikni(Rˉj−Rˉ)2 ,这里的统计量涉及的参数比较多,有秩的概念、总样本的概念等,我们这不详细介绍,主要介绍检验用法,有兴趣的可以参考这,
http://www.doc88.com/p-9985360704629.html
3:作出决策,对于大样本和小样本的统计量分布查表是不同的,大样本下近似 H H H 近似服从 χ 2 ( k − 1 ) \chi^2(k-1) χ2(k−1) ,小样本下可直接查表得到,通过决策值或者 p p p 值判定是否拒绝或接受原假设。
我们以实际例子作为联系,研究不同的药对咳嗽的治疗是否不同,
from scipy import stats
##服用不同药情况下咳嗽人群阶段治愈数
medicine_a = [80,203,236,252,284,368,457,393]
medicine_b = [133,180,100,160]
medicine_c = [156,295,320,448,465,481,885]
medicine_d = [194,214,272,330,386,475]
df = pd.DataFrame([medicine_a,medicine_b,medicine_c,medicine_d],index=['medinine_a','medinine_b','medinine_c','medinine_d']).T
test_res = stats.kruskal(df['medinine_a'].dropna(),df['medinine_b'].dropna(),df['medinine_c'].dropna(),df['medinine_d'].dropna())
print(test_res)
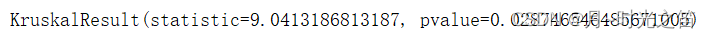
由上图5我们根据 p p p 值发现,不同药对咳嗽的治疗是有不同作用的。
另外,K-W检验对应于参数检验的方法是方差分析,即研究因子在不同水平下对反应变量均值是否有显著影响,那么假设以上数据满足方差齐次和正态分布,方差分析结果如下:
med_ls = ['medicine_a','medicine_a','medicine_a','medicine_a','medicine_a','medicine_a','medicine_a','medicine_a'
,'medicine_b','medicine_b','medicine_b','medicine_b','medicine_c','medicine_c','medicine_c','medicine_c',
'medicine_c','medicine_c','medicine_c','medicine_d','medicine_d','medicine_d','medicine_d','medicine_d',
'medicine_d']
recov_ls = [80,203,236,252,284,368,457,393,133,180,100,160,156,295,320,448,465,481,885,194,214,272,330,386,475]
df = pd.DataFrame([med_ls,recov_ls],index=['med','nums']).T
data_new = df.dropna()
data_new['nums'] = data_new['nums'].apply(pd.to_numeric)
model = ols('nums ~ C(med)',data_new).fit()
table = no.anova_lm(model)
print(table)

图6就是对应方差分析的结果。
七:非参数检验之K-S分布检验
Kolmogorov-Smirnov(K-S)分布检验是一种非常重要的非参数检验方法。它是一种统计检验方法,它通过比较两样本的频率分布,或者一个样本的频率分布与特定理论分布(如正态分布、泊松分布等)之间的差异大小来推论两个分布是否来自同一个分布。
KS检验的原假设 H 0 : H_0: H0: 对所有 x x x 的值, F ( x ) = F 0 ( x ) F(x)=F_0(x) F(x)=F0(x) ,双尾的备择假设:
H 1 : H_1: H1: 对至少一个 x x x 值, F ( x ) ≠ F 0 ( x ) F(x)\ne F_0(x) F(x)=F0(x) 。令 S ( x ) S(x) S(x) 表示该组数据的经验分布,
一般来说随机样本 X 1 , X 2 , . . . X n X_1,X_2,...X_n X1,X2,...Xn 的经验分布函数定义为阶梯函数:
S ( x ) = X i ≤ x 的 个 数 n S(x)=\frac{X_i\leq x的个数}{n} S(x)=nXi≤x的个数 ,它是小于等于 x x x 值的比例,它是总体分布 F ( x ) F(x) F(x) 的一个估
计,对于双尾检验,检验统计量设为: D = s u p x ∣ S ( X ) − F 0 ( X ) ∣ D=sup_x\left| S(X)-F_0(X) \right| D=supx∣S(X)−F0(X)∣ 。
注:统计量 D D D 的分布实际上在零假设下对于一切连续分布 F 0 ( x ) F_0(x) F0(x) 是一样的,所以与分布无关。由于 S ( x ) S(x) S(x) 是阶梯函数,只取离散值,考虑到跳跃问题,在实际运作中,如果有 n n n 个观测值,则下面的统计量来代替 D D D , D n = m a x ( i ∈ [ 1 , n ] ) { m a x ( ∣ S ( x i ) − F 0 ( x i ) ∣ , ∣ S ( x i − 1 ) − F ( x i ) ∣ ) } D_n=max(i\in[1,n])\left\{ max\left( \left| S(x_i)-F_0(x_i) \right|,\left| S(x_{i-1})-F(x_i) \right| \right) \right\} Dn=max(i∈[1,n]){ max(∣S(xi)−F0(xi)∣,∣S(xi−1)−F(xi)∣)} 。
- 关于qq图检验的运用
q q qq qq图检验数据分布是一种非常直观的方法了。由于样本 x x x 的分位数为其经验累积分布函数的逆函数,如果把数据列 x x x 的经验分位数点对一个已知分布的相应分位数点画出散点图,那么当 x x x 的经验分布类似于已知分布时,图形就近似地形成一条斜率为 1 1 1的直线,否则,图形中端部就会较大地偏离这个直线。
我们用Python感受这一过程:
import matplotlib.pyplot as plt
from scipy import stats
norm_arr = np.random.uniform(0,1,10000)
stats.probplot(norm_arr, dist='uniform', plot=plt)
plt.show()
stats.probplot(norm_arr, dist='norm', plot=plt)
plt.show()
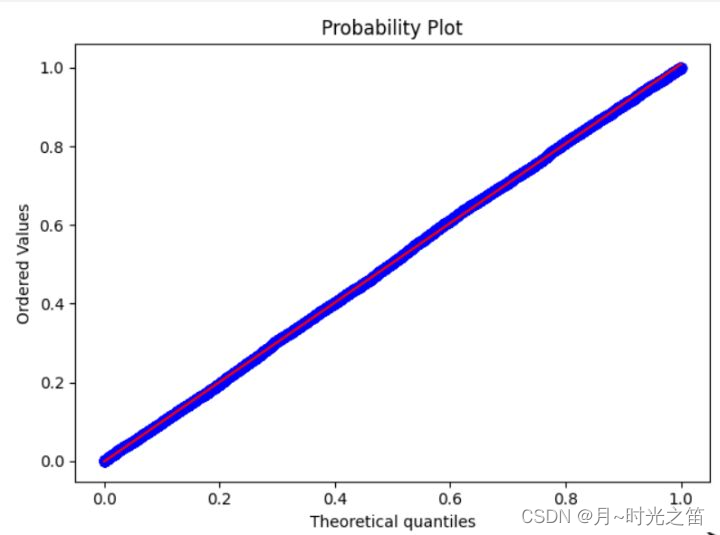
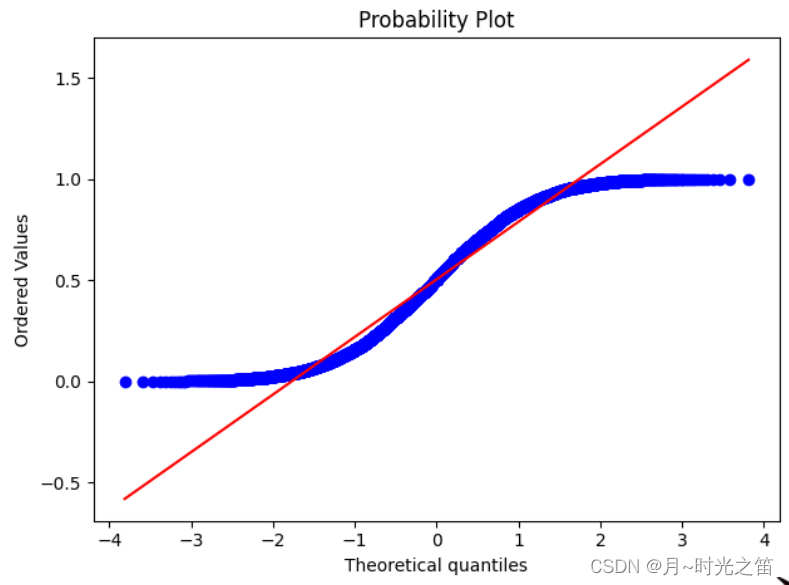
我们已知给定的数据是上下限为 0 − 1 0-1 0−1的均匀随机数,图7是 d i s t = ′ u n i f o r m ′ dist='uniform' dist=′uniform′时的结果,图8是 d i s t = ′ n o r m ′ dist='norm' dist=′norm′时的结果,明显直观感觉到 q q qq qq图方法的直观性,且原本随机数是服从均匀分布的!
- 关于KS检验的运用
我们对上述数据用KS检验法看看结果如何:
res = stats.kstest(norm_arr,'uniform',alternative='two-sided')
print('\033[1;33m用KS检验方法检验上述随机数分布:\033[0m',res)

从 p p p 值结果看,很明显原本随机数是服从均匀分布的,接受原假设。
接着我们对两组或两组以上数据运用KS检验方法观察结果:
arr1 = np.random.uniform(0,1,100)
arr2 = np.random.normal(0,1,100)
res1 = stats.ks_2samp(arr1,arr2)
print('\033[1;31m一个正态分布N~(0,1),一个均匀分布U~(0,1)的检测结果:\033[1;0m',res1)
arr1 = np.random.normal(0,1,100)##数据长度不一致也可行!!
arr2 = np.random.normal(0,1,150)
res2 = stats.ks_2samp(arr1,arr2)
print('\033[1;32m两个都是正态分布N~(0,1)的检测结果:\033[1;0m',res2)

综上,我们能感受到KS检验的方便性和适用性,但对于是否服从正态分布等检验的检验方法不止局限上述两种,还有Shapiro-Wilk正态检验、历史悠久的 χ 2 \chi^2 χ2 检验等等。
八:总结
本篇文章主要是关于统计学中常见和重要的检验分析。其它参数检验如 F F F 检验,非参数检验如二项检验、游程检验等等,都是类似的原理和方法。熟练运用以上6种检验能解决生活和生产中很多问题了,学习其它方法也会更加游刃有余。
但我们一定要清楚统计检验和统计分布的概念区别,检验是对样本统计量进行一系列操作,分布则就是指一些数据(一般指随机变量)符合何种概率或者概率密度分布。所以卡方检验和卡方分布是完全不同的两个概念!