import requests
from bs4 import BeautifulSoup
import json
import re
headers = {"Cookie": "SINAGLOBAL=1340288961669.5112.1559828635483; UOR=,,www.baidu.com; Ugrow-G0=169004153682ef91866609488943c77f; login_sid_t=851912c52eb5bfb51baac61a5c95e5ac; cross_origin_proto=SSL; YF-V5-G0=8a1a69dc6ba21f1cd10b039dff0f4381; _s_tentry=passport.weibo.com; Apache=8952837854874.121.1560057315193; ULV=1560057315202:4:4:1:8952837854874.121.1560057315193:1559956552023; SSOLoginState=1560057387; YF-Page-G0=112e41ab9e0875e1b6850404cae8fa0e|1560519695|1560519693; SCF=AqS7E90doP65N8vbMSLd4kyOAtaeFwjmNEQlgZrEOg_A7qDzGoMkQI1mFPd9IIj1w28fCg0CzB-BStG3QOo4Vmc.; SUB=_2A25wB9RBDeRhGeBP4lUR9SnOyDmIHXVTdUKJrDV8PUJbmtBeLXTYkW9NRQ29hCuEgG2yOH2yx3LX7m_UqH9GwHDe; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WhOsgAJRZjhUO8CY1cVR00u5JpX5K-hUgL.Foqp1KM7SKMEe0-2dJLoIpUZqgSaqbH8SCHWSb-RebH8SC-R1F-4x5tt; SUHB=0C1yiLJnMlt4wz; ALF=1592055685"}
r = requests.get('https://weibo.com/p/1004061195242865/follow?relate=fans&from=100406&wvr=6&mod=headfans¤t=fans#place',headers=headers)
fansStr = r.text.split("</script>")
tmpJson = fansStr[-2][17:-1] if fansStr[-2][17:-1].__len__()>fansStr[-3][17:-1].__len__() else fansStr[-3][17:-1]
soup = BeautifulSoup(json.loads(tmpJson)['html'],'lxml')
class person(object):
def __init__(self, personTag = None):
self.analysis(personTag)
def analysis(self,personTag):
self.analysisName(personTag)
self.analysisFollowAndFansNumber(personTag)
self.analysisCity(personTag)
self.analysisIntroduce(personTag)
self.analysisFollowWay(personTag)
self.analysisID(personTag)
def analysisName(self,personTag):
self.name = personTag.div.a.string
def analysisFollowAndFansNumber(self,personTag):
for divTag in personTag.find_all('div'):
if divTag['class'] == ["info_connect"]:
infoTag = divTag
if locals().get("infoTag"):
self.followNumber = infoTag.find_all('span')[0].em.string
self.fansNumber = infoTag.find_all('span')[1].em.a.string
self.assay = infoTag.find_all('span')[2].em.a.string
def analysisCity(self,personTag):
for divTag in personTag.find_all('div'):
if divTag['class'] == ['info_add']:
addressTag = divTag
if locals().get('addressTag'):
self.address = addressTag.span.string
def analysisIntroduce(self,personTag):
for divTag in personTag.find_all('div'):
if divTag['class'] == ['info_intro']:
introduceTag = divTag
if locals().get('introduceTag'):
self.introduce = introduceTag.span.string
def analysisFollowWay(self,personTag):
for divTag in personTag.find_all('div'):
if divTag['class'] == ['info_from']:
fromTag = divTag
if locals().get('fromTag'):
self.fromInfo = fromTag.a.string
def analysisID(self,personTag):
personRel = personTag.dt.a['href']
self.id = personRel[personRel.find('=')+1:-5]+personRel[3:personRel.find('?')]
for divTag in soup.find_all('div'):
if divTag['class'] == ["follow_inner"]:
followTag = divTag
if __name__ == '__main__':
if locals().get("followTag"):
for personTag in followTag.find_all('dl'):
p = person(personTag)
print(p.__dict__)
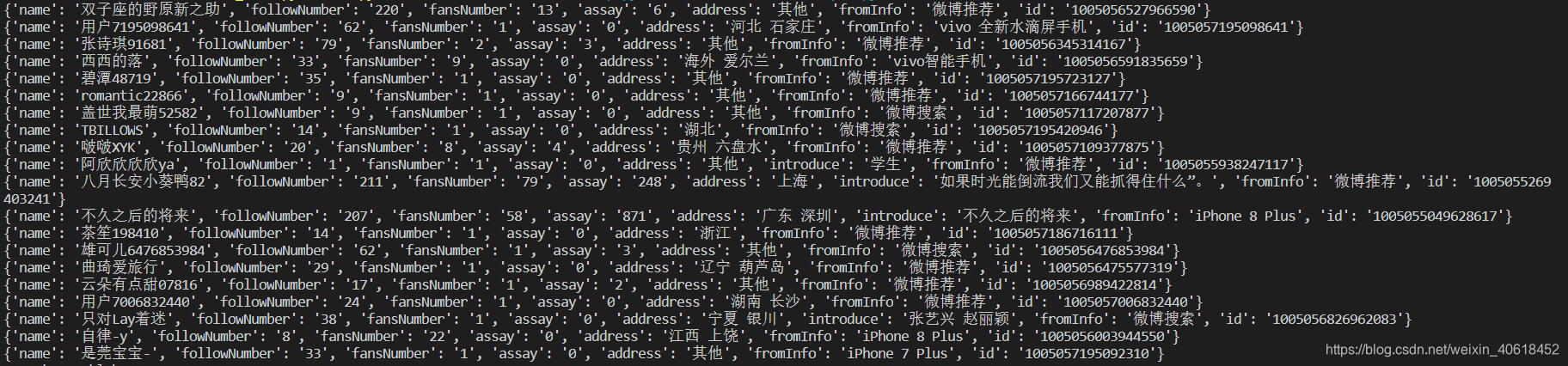
运行效果如下: