1. 仿射变换
warpAffine是一种二维仿射变换技术,可以将图像从一种形式转换为另一种形式。它是OpenCV图像处理库中的一个函数,可用于对图像进行平移、旋转、缩放和剪切等操作。
仿射变换可以通过线性变换来描述,可以用一个2x3的矩阵来表示。在图像处理中,这个矩阵通常称为变换矩阵,其中包含了平移、旋转、缩放和剪切的参数。
通过warpAffine函数,我们可以将这个变换矩阵应用到输入图像中的每个像素上,从而生成一个新的输出图像。这使得我们可以对图像进行各种几何变换,如旋转、缩放、翻转和扭曲等。
要使用warpAffine函数,您需要指定一个输入图像、一个输出图像和一个2x3的变换矩阵。该函数将变换矩阵应用于输入图像中的每个像素,并将结果存储在输出图像中。
总的来说,warpAffine函数是一种非常有用的图像处理工具,它可以帮助我们实现各种几何变换,以实现我们所需的图像效果。
仓库里面有一个杜老师写好的ipynb文件,写了一个python版本的仿射变换,双线性插值
2. 双线性插值
如果inverse mapping回原图发现是小数,启动双线性插值
双线性插值是一种图像处理中常用的插值方法。在进行缩放、旋转、仿射变换等操作时,由于目标图像的像素点坐标通常不是整数,因此需要对像素进行插值计算,以得到目标图像中对应的像素值。双线性插值就是其中一种常用的插值方法。
双线性插值的原理是基于线性插值的基础上,对两个方向分别进行一次线性插值。具体地,假设我们要计算一个目标像素点的像素值,该像素点的坐标在源图像中为(x, y),并且在该像素点的四个邻近像素点的坐标分别为(x1, y1),(x1, y2),(x2, y1),(x2, y2)。那么双线性插值的计算方法如下:
-
在x方向上,对x和x1之间以及x2和x之间的像素值进行线性插值,得到两个中间值f1和f2:
f1 = (x2 - x) / (x2 - x1) * I(y1, x1) + (x - x1) / (x2 - x1) * I(y1, x2)
f2 = (x2 - x) / (x2 - x1) * I(y2, x1) + (x - x1) / (x2 - x1) * I(y2, x2) -
在y方向上,对f1和f2进行线性插值,得到最终的像素值f:
f = (y2 - y) / (y2 - y1) * f1 + (y - y1) / (y2 - y1) * f2
其中I(y, x)表示源图像中坐标为(y, x)的像素值。
双线性插值计算出来的像素值(f)可能是浮点数,因为它是通过对原图像周围的四个像素进行加权平均得到的。但最终像素值需要在存储时转换成整数类型,通常是通过向下取整的方式实现。
双线性插值的主要优点是计算简单、速度快,并且可以得到相对较好的插值效果,可以避免出现明显的锯齿和图像失真等问题。因此,它被广泛应用于图像处理中的各种操作,如缩放、旋转、仿射变换等。
3. 代码的整体思路
是在对图像进行仿射变换并且保持特征不变,同时使用逆映射的方式将目标图像上的像素值回映射回原图像中。其中双线性插值是一种常见的插值方法,用于在原图像中找到目标像素的值,以保持图像质量。同时CUDA加速可以加速计算,提高运行效率。
3. 杜老师的原版代码main.cpp文件
#include <cuda_runtime.h>
#include <opencv2/opencv.hpp>
#include <stdio.h>
using namespace cv;
#define min(a, b) ((a) < (b) ? (a) : (b))
#define checkRuntime(op) __check_cuda_runtime((op), #op, __FILE__, __LINE__)
bool __check_cuda_runtime(cudaError_t code, const char* op, const char* file, int line){
if(code != cudaSuccess){
const char* err_name = cudaGetErrorName(code);
const char* err_message = cudaGetErrorString(code);
printf("runtime error %s:%d %s failed. \n code = %s, message = %s\n", file, line, op, err_name, err_message);
return false;
}
return true;
}
void warp_affine_bilinear( // 声明
uint8_t* src, int src_line_size, int src_width, int src_height,
uint8_t* dst, int dst_line_size, int dst_width, int dst_height,
uint8_t fill_value
);
Mat warpaffine_to_center_align(const Mat& image, const Size& size){
/*
建议先阅读代码,若有疑问,可点击抖音短视频进行辅助讲解(建议1.5倍速观看)
思路讲解:https://v.douyin.com/NhrNnVm/
代码讲解: https://v.douyin.com/NhMv4nr/
*/
Mat output(size, CV_8UC3);
uint8_t* psrc_device = nullptr;
uint8_t* pdst_device = nullptr;
size_t src_size = image.cols * image.rows * 3;
size_t dst_size = size.width * size.height * 3;
checkRuntime(cudaMalloc(&psrc_device, src_size)); // 在GPU上开辟两块空间
checkRuntime(cudaMalloc(&pdst_device, dst_size));
checkRuntime(cudaMemcpy(psrc_device, image.data, src_size, cudaMemcpyHostToDevice)); // 搬运数据到GPU上
warp_affine_bilinear(
psrc_device, image.cols * 3, image.cols, image.rows,
pdst_device, size.width * 3, size.width, size.height,
114
);
// 检查核函数执行是否存在错误
checkRuntime(cudaPeekAtLastError());
checkRuntime(cudaMemcpy(output.data, pdst_device, dst_size, cudaMemcpyDeviceToHost)); // 将预处理完的数据搬运回来
checkRuntime(cudaFree(psrc_device));
checkRuntime(cudaFree(pdst_device));
return output;
}
int main(){
/*
若有疑问,可点击抖音短视频辅助讲解(建议1.5倍速观看)
https://v.douyin.com/NhMrb2A/
*/
// int device_count = 1;
// checkRuntime(cudaGetDeviceCount(&device_count));
Mat image = imread("yq.jpg");
Mat output = warpaffine_to_center_align(image, Size(640, 640));
imwrite("output.jpg", output);
printf("Done. save to output.jpg\n");
return 0;
}
4. 杜老师的原版affine.cu
#include <cuda_runtime.h>
#define min(a, b) ((a) < (b) ? (a) : (b))
#define num_threads 512
typedef unsigned char uint8_t;
struct Size{
int width = 0, height = 0;
Size() = default;
Size(int w, int h)
:width(w), height(h){
}
};
// 计算仿射变换矩阵
// 计算的矩阵是居中缩放
struct AffineMatrix{
/*
建议先阅读代码,若有疑问,可点击抖音短视频进行辅助讲解(建议1.5倍速观看)
- https://v.douyin.com/Nhr5UdL/
*/
float i2d[6]; // image to dst(network), 2x3 matrix
float d2i[6]; // dst to image, 2x3 matrix
// 这里其实是求解imat的逆矩阵,由于这个3x3矩阵的第三行是确定的0, 0, 1,因此可以简写如下
void invertAffineTransform(float imat[6], float omat[6]){
float i00 = imat[0]; float i01 = imat[1]; float i02 = imat[2];
float i10 = imat[3]; float i11 = imat[4]; float i12 = imat[5];
// 计算行列式
float D = i00 * i11 - i01 * i10;
D = D != 0 ? 1.0 / D : 0;
// 计算剩余的伴随矩阵除以行列式
float A11 = i11 * D;
float A22 = i00 * D;
float A12 = -i01 * D;
float A21 = -i10 * D;
float b1 = -A11 * i02 - A12 * i12;
float b2 = -A21 * i02 - A22 * i12;
omat[0] = A11; omat[1] = A12; omat[2] = b1;
omat[3] = A21; omat[4] = A22; omat[5] = b2;
}
void compute(const Size& from, const Size& to){
float scale_x = to.width / (float)from.width;
float scale_y = to.height / (float)from.height;
// 这里取min的理由是
// 1. M矩阵是 from * M = to的方式进行映射,因此scale的分母一定是from
// 2. 取最小,即根据宽高比,算出最小的比例,如果取最大,则势必有一部分超出图像范围而被裁剪掉,这不是我们要的
// **
float scale = min(scale_x, scale_y); // 缩放比例辅助视频讲解 https://v.douyin.com/NhrH8Gm/
/**
这里的仿射变换矩阵实质上是2x3的矩阵,具体实现是
scale, 0, -scale * from.width * 0.5 + to.width * 0.5
0, scale, -scale * from.height * 0.5 + to.height * 0.5
这里可以想象成,是经历过缩放、平移、平移三次变换后的组合,M = TPS
例如第一个S矩阵,定义为把输入的from图像,等比缩放scale倍,到to尺度下
S = [
scale, 0, 0
0, scale, 0
0, 0, 1
]
P矩阵定义为第一次平移变换矩阵,将图像的原点,从左上角,移动到缩放(scale)后图像的中心上
P = [
1, 0, -scale * from.width * 0.5
0, 1, -scale * from.height * 0.5
0, 0, 1
]
T矩阵定义为第二次平移变换矩阵,将图像从原点移动到目标(to)图的中心上
T = [
1, 0, to.width * 0.5,
0, 1, to.height * 0.5,
0, 0, 1
]
通过将3个矩阵顺序乘起来,即可得到下面的表达式:
M = [
scale, 0, -scale * from.width * 0.5 + to.width * 0.5
0, scale, -scale * from.height * 0.5 + to.height * 0.5
0, 0, 1
]
去掉第三行就得到opencv需要的输入2x3矩阵
**/
/*
+ scale * 0.5 - 0.5 的主要原因是使得中心更加对齐,下采样不明显,但是上采样时就比较明显
参考:https://www.iteye.com/blog/handspeaker-1545126
*/
i2d[0] = scale; i2d[1] = 0; i2d[2] =
-scale * from.width * 0.5 + to.width * 0.5 + scale * 0.5 - 0.5;
i2d[3] = 0; i2d[4] = scale; i2d[5] =
-scale * from.height * 0.5 + to.height * 0.5 + scale * 0.5 - 0.5;
invertAffineTransform(i2d, d2i);
}
};
__device__ void affine_project(float* matrix, int x, int y, float* proj_x, float* proj_y){
// matrix
// m0, m1, m2
// m3, m4, m5
*proj_x = matrix[0] * x + matrix[1] * y + matrix[2];
*proj_y = matrix[3] * x + matrix[4] * y + matrix[5];
}
__global__ void warp_affine_bilinear_kernel(
uint8_t* src, int src_line_size, int src_width, int src_height,
uint8_t* dst, int dst_line_size, int dst_width, int dst_height,
uint8_t fill_value, AffineMatrix matrix
){
/*
建议先阅读代码,若有疑问,可点击抖音短视频进行辅助讲解(建议1.5倍速观看)
- https://v.douyin.com/Nhr4vTF/
*/
// 2个1D的
int dx = blockDim.x * blockIdx.x + threadIdx.x;
int dy = blockDim.y * blockIdx.y + threadIdx.y;
if (dx >= dst_width || dy >= dst_height) return; // 启动线程数可能超过图像大小, 超过就return
float c0 = fill_value, c1 = fill_value, c2 = fill_value;
float src_x = 0; float src_y = 0;
affine_project(matrix.d2i, dx, dy, &src_x, &src_y);
/*
建议先阅读代码,若有疑问,可点击抖音短视频进行辅助讲解(建议1.5倍速观看)
- 双线性理论讲解:https://v.douyin.com/NhrH2tb/
- 代码代码:https://v.douyin.com/NhrBqpc/
*/
if(src_x < -1 || src_x >= src_width || src_y < -1 || src_y >= src_height){
// out of range
// src_x < -1时,其高位high_x < 0,超出范围
// src_x >= -1时,其高位high_x >= 0,存在取值
}else{
int y_low = floorf(src_y);
int x_low = floorf(src_x);
int y_high = y_low + 1;
int x_high = x_low + 1;
uint8_t const_values[] = {
fill_value, fill_value, fill_value};
float ly = src_y - y_low;
float lx = src_x - x_low;
float hy = 1 - ly;
float hx = 1 - lx;
float w1 = hy * hx, w2 = hy * lx, w3 = ly * hx, w4 = ly * lx;
uint8_t* v1 = const_values;
uint8_t* v2 = const_values;
uint8_t* v3 = const_values;
uint8_t* v4 = const_values;
if(y_low >= 0){
if (x_low >= 0)
v1 = src + y_low * src_line_size + x_low * 3;
if (x_high < src_width)
v2 = src + y_low * src_line_size + x_high * 3;
}
if(y_high < src_height){
if (x_low >= 0)
v3 = src + y_high * src_line_size + x_low * 3;
if (x_high < src_width)
v4 = src + y_high * src_line_size + x_high * 3;
}
c0 = floorf(w1 * v1[0] + w2 * v2[0] + w3 * v3[0] + w4 * v4[0] + 0.5f);
c1 = floorf(w1 * v1[1] + w2 * v2[1] + w3 * v3[1] + w4 * v4[1] + 0.5f);
c2 = floorf(w1 * v1[2] + w2 * v2[2] + w3 * v3[2] + w4 * v4[2] + 0.5f);
}
uint8_t* pdst = dst + dy * dst_line_size + dx * 3;
pdst[0] = c0; pdst[1] = c1; pdst[2] = c2;
}
void warp_affine_bilinear(
/*
建议先阅读代码,若有疑问,可点击抖音短视频进行辅助讲解(建议1.5倍速观看)
- https://v.douyin.com/Nhre7fV/
*/
uint8_t* src, int src_line_size, int src_width, int src_height,
uint8_t* dst, int dst_line_size, int dst_width, int dst_height,
uint8_t fill_value
){
// 2D layout
// 2个1D layout
dim3 block_size(32, 32); // blocksize最大就是1024,这里用2d来看更好理解
dim3 grid_size((dst_width + 31) / 32, (dst_height + 31) / 32); // 目标图像
AffineMatrix affine;
affine.compute(Size(src_width, src_height), Size(dst_width, dst_height));
warp_affine_bilinear_kernel<<<grid_size, block_size, 0, nullptr>>>(
src, src_line_size, src_width, src_height,
dst, dst_line_size, dst_width, dst_height,
fill_value, affine
);
}
5. 拆解代码
int main(){
Mat image = imread("yq.jpg");
// 参数类型 Mat Size
Mat output = warpaffine_to_center_align(image, Size(640, 640));
imwrite("output.jpg", output);
printf("Done. save to output.jpg\n");
return 0;
}
Size是OpenCV库中定义的一个结构体,用来表示图像或矩阵的尺寸(宽度和高度),其数据类型为整型,例如Size2i表示宽度和高度都是整型。const关键字用于指定函数参数不可修改,这样可以确保在函数内部不会无意间修改到原始的输入数据,提高代码的健壮性和可维护性。
Mat是OpenCV库中用于存储图像或矩阵数据的类,其数据类型为unsigned char类型的指针。通过创建Mat对象,可以方便地访问和处理图像或矩阵数据。在函数中使用const关键字和取地址引用的目的也是为了保证在函数内部不会无意间修改到原始的输入数据。
5.1 warpaffine_to_center_align()详细注释版
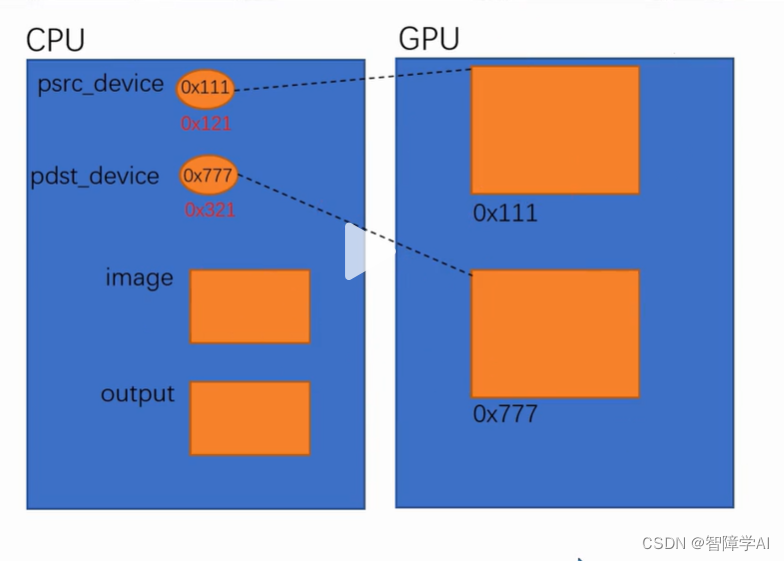
- 先在CPU上开辟4个东西,2个只想GPU的指针,先被空指针初始化. 还有两个是图像的Input, output
- 用cudaMalloc()在GPU上开辟两个内存,他们的内存大小等同于CPU上开辟的图像大小,然后用cudaMemcpy把CPU上的图像数据复制到GPU上面去。这里指针还是在CPU上的。
- 操作完成后用cudaMemcpy把数据从GPU复制回CPU上做一个输出的展示
Mat warpaffine_to_center_align(const Mat& image, const Size& size){
// 创建一个Mat类型的output, 大小为size,类型为CV_8UC3
Mat output(size, CV_8UC3);
// 定义CPU上的指针
// uint8_t是一种无符号8位整数类型,可以表示0到255之间的整数。在OpenCV中,像素值通常以8位无符号整数类型存储,
// 因此使用uint8_t类型可以确保正确的数据类型匹配和内存使用,同时提供了更好的可读性
uint8_t *psrc_device = nullptr;
uint8_t *pdst_device = nullptr;
// 在GPU上开辟内存的大小
size_t src_size = image.cols * image.rows * 3;
size_t dst_size = size.width * size.height * 3;
// cudaMalloc开辟内存
checkRuntime(cudaMalloc(&psrc_device, src_size));
checkRuntime(cudaMalloc(&pdst_device, dst_size));
// 把数据搬运到GPU上面去
// image.data指的是image的首地址
checkRuntime(cudaMemcpy(psrc_device, image.data, src_size,cudaMemcpyHostToDevice));
warp_affine_bilinear(
psrc_device, image.cols * 3, image.cols, image.rows,
pdst_device, size.width * 3, size.width, size.height,
114
);
// 检查核函数执行是否存在错误
checkRuntime(cudaPeekAtLastError());
checkRuntime(cudaMemcpy(output.data, pdst_device, dst_size, cudaMemcpyDeviceToHost));
checkRuntime(cudaFree(psrc_device));
checkRuntime(cudaFree(pdst_device));
return output;
}
5.2 warp_affine_bilinear()详细注释版
定义布局,然后启动核函数
一个线程(thread)处理一个像素值的三个通道
一个线程块中的多个线程共同处理一个小块的像素值,这个小块的大小由block_size决定。在warp_affine_bilinear_kernel中,每个线程对应着目标图像中的一个像素点,通过线程ID和线程块中的索引计算出该像素点在原图像中的位置,然后使用仿射矩阵将该像素点映射到原图像中的位置,最后进行双线性插值得到目标图像中该像素点的像素值。因此,可以说是一个线程对应一个目标图像中的像素点。
首先,dim3是CUDA中定义线程块和线程格的数据结构。block_size定义了每个线程块中的线程数量,这里的(32, 32)表示每个线程块中包含32x32=1024个线程,因为CUDA支持的线程块中最多有1024个线程。
其次,grid_size定义了整个线程格中的线程块数量,即并行计算需要的线程块的数量。这里的31是为了将除法运算的结果向上取整,而不是四舍五入。具体来说,如果目标图像的宽度或高度是32的倍数,那么加上31后除以32得到的结果就是这个数值本身,即没有向上取整;如果目标图像的宽度或高度不是32的倍数,那么加上31后再除以32得到的结果就会向上取整,以确保线程格中包含足够的线程块来覆盖整个图像区域。
void warp_affine_bilinear(
/*
建议先阅读代码,若有疑问,可点击抖音短视频进行辅助讲解(建议1.5倍速观看)
- https://v.douyin.com/Nhre7fV/
*/
uint8_t *src, int src_line_size, int src_width, int src_height,
uint8_t *dst, int dst_line_size, int dst_width, int dst_height,
uint8_t fill_value)
{
/*
参数内容
原图参数:
*src: 原图指针
src_line_size: 原图每行的字节数 image.cols * 3
src_width: 原图宽 image.cols
src_height: 原图高 image.rows
目标图像参数:
*dst: 目标图指针
dst_line_size: 目标图每行字节数 size.width * 3
dst_width: 目标图宽
dst_height: 目标图高
fill_value: 仿射变换完其他地方需要填充的东西
*/
// 定义block size, 每一个block里面有32x32个线程块
dim3 block_size(32, 32); // blocksize最大就是1024
// 定义grid_Size, 向上取整确保线程格中包含足够的线程块来覆盖整个图像区域
dim3 grid_size((dst_width + 31) / 32, (dst_height + 31) / 32);
// 计算仿射矩阵
AffineMatrix affine;
// Size构建两个结构体传入affine.compute()里面
affine.compute(Size(src_width, src_height), Size(dst_width, dst_height));
// 启动核函数实现栓线性插值仿射变换
warp_affine_bilinear_kernel<<<grid_size, block_size, 0, nullptr>>>(
src, src_line_size, src_width, src_height,
dst, dst_line_size, dst_width, dst_height,
fill_value, affine);
}
5.3 核函数 warp_affine_bilinear_kernel()
4个点的坐标讲解,lx, ly, hx, hy
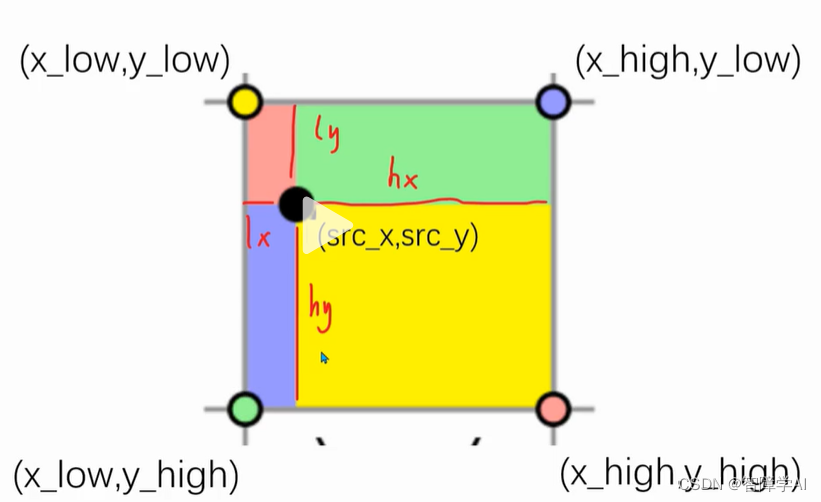
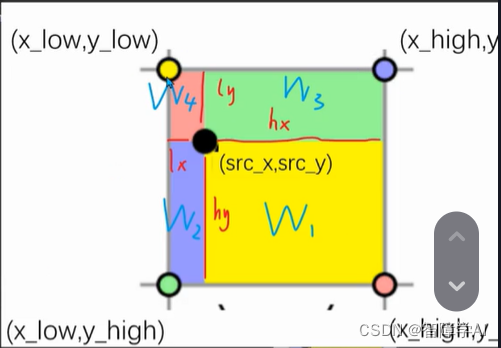
4个对应的面积,这里是黄色点x黄色面积, 示意图w1在右小角, 4个点在代码中的填充分别是v1, v2, v3, v5
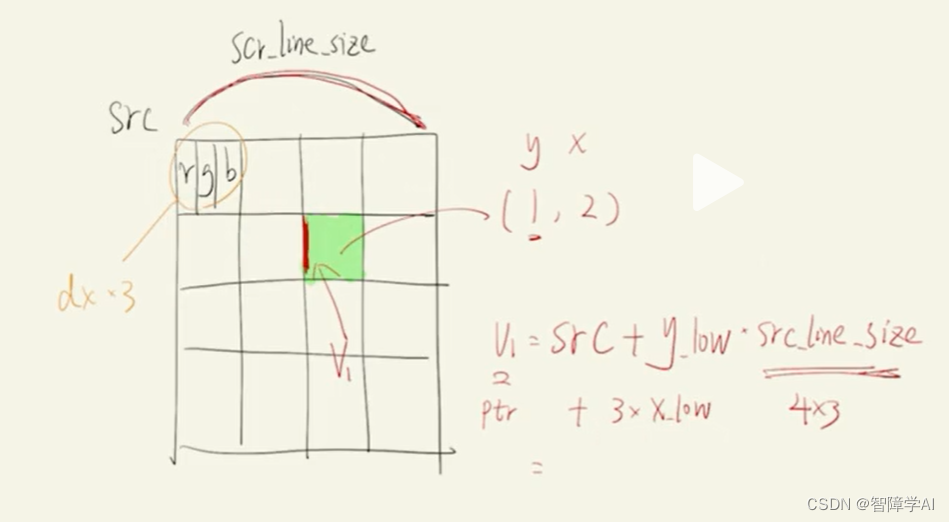
v1, v2, v3, v4的ptr, 怎么指向, 可以看到在整个布局中还是2D的,但是每一行就是一个像素的rgb三个通道的值是粘在一起的
__device__ void affine_project(float *matrix, int x, int y, float *proj_x, float *proj_y)
{
// matrix
// m0, m1, m2
// m3, m4, m5
*proj_x = matrix[0] * x + matrix[1] * y + matrix[2];
*proj_y = matrix[3] * x + matrix[4] * y + matrix[5];
}
__global__ void warp_affine_bilinear_kernel(
uint8_t *src, int src_line_size, int src_width, int src_height,
uint8_t *dst, int dst_line_size, int dst_width, int dst_height,
uint8_t fill_value, AffineMatrix matrix)
{
// 2个1D的 block维度 * block索引 * 线程所在维度的索引
int dx = blockDim.x * blockIdx.x + threadIdx.x;
int dy = blockDim.y * blockIdx.y + threadIdx.y;
// 如果启动的线程索引超过了图像, 直接return
if (dx > dst_width || dy > dst_height)
{
return;
}
// 定义fill value, 因为这里的fill value是main函数传进来的
float c0 = fill_value;
float c1 = fill_value;
float c2 = fill_value;
// 定义src_x, src_y 用与affine_project返回的
// 通过dx, dy 线程索引返回src_x, src_y的值
// 这一步的操作就是获得src_x, src_y
// matrix.d2i 是inverse mapping, 用于从目标图像的坐标反向计算出原图像上的坐标
float src_x = 0;
float src_y = 0;
affine_project(matrix.d2i, dx, dy, &src_x, &src_y);
// 这里开始进行双线性插值
if (src_x < -1 || src_x >= src_width || src_y < -1 || src_y >= src_height)
{
/*
out of range 超出边界了,这里注意的一点是x_low, y_low是可以取到-1
[-1, src_width] 这个区间x是有取值的
[-1, src_height] 这个区间的y是有取值的
*/
}
else{
// 找到最近四个点的坐标
int y_low = floorf(src_y);
int x_low = floorf(src_x);
int y_high = y_low + 1;
int x_high = x_low + 1;
uint8_t const_values[] = {
fill_value, fill_value, fill_value};
// 4 个数值都写出来
float ly = src_y - y_low;
float lx = src_x - x_low;
float hy = 1 - ly; // 上面算出来的是相对位置,这边直接减就可以了
float hx = 1 - lx;
// 定义4个面积, 用于双线性插值的计算
float w1 = hy * hx;
float w2 = hy * lx;
float w3 = ly * hx;
float w4 = ly * lx;
// 先给4个点赋予上初始值
uint8_t *v1 = const_values;
uint8_t *v2 = const_values;
uint8_t *v3 = const_values;
uint8_t *v4 = const_values;
// 这里计算v1, v2, v3, v4的地址
if (y_low >= 0){
if (x_low >= 0){
// 这里的src_line_size 在从main.cpp传入进来的时候就已经 * 3
v1 = src + y_low * src_line_size + x_low * 3;
}
if (x_high < src_width){
v2 = src + y_low * src_line_size + x_high * 3;
}
}
if(y_high < src_height){
if (x_low >= 0)
v3 = src + y_high * src_line_size + x_low * 3;
if (x_high < src_width)
v4 = src + y_high * src_line_size + x_high * 3;
}
// 计算双线性插值
c0 = floorf(w1 * v1[0] + w2 * v2[0] + w3 * v3[0] + w4 * v4[0] + 0.5f);
c1 = floorf(w1 * v1[1] + w2 * v2[1] + w3 * v3[1] + w4 * v4[1] + 0.5f);
c2 = floorf(w1 * v1[2] + w2 * v2[2] + w3 * v3[2] + w4 * v4[2] + 0.5f);
}
// 上面写完了经历了从目标图像找回原始图像坐标
// 从原始图像坐标做了个双线性插值,计算了目标图像的色调
// 直接去dst图像上修改,这里通过地址去修改
uint8_t* pdst = dst + dy * dst_line_size + dx * 3;
pdst[0] = c0; pdst[1] = c1; pdst[2] = c2; // RGB
pdst[2] = c0; pdst[1] = c1; pdst[0] = c2; // BGR
}