0、前言
前期博文适用于小样本时间序列预测的图半监督学习方法介绍了图半监督方法,本博文先将图半监督方法与ELM结合用于分类,检验图半监督学习方法的有效性。后期博文将复现博文适用于小样本时间序列预测的图半监督学习方法中的方法。
1、图半监督极限学习机原理
目前半监督极限学习机主要是建立在流形正则化方法基础上,在求解目标函数中加入流形正则化约束。而本文所提图半监督极限学习机并不是在其求解公式中加入流形惩罚,而是先利用图半监督学习方法自动给未标记的数据上标签,扩充样本集,尽量克服因已知标签数据不充分而无法训练得到高泛化性能分类器的局限性。
即图半监督极限学习机方法分为两步:①自动标记:基于图半监督算法自动给样本集中未标记的数据上标签;②再将新标记的数据和原少量带有标记的数据合并送入到ELM中进行训练,最后用训练好的ELM对测试集进行分类。
1.1 图半监督学习算法框架
图半监督算法认为在相同结构中的点有可能有相同的标签,所以图半监督算法是从数据的全局结构来标记未带标签样本。


1.2 ELM原理
此处不再详细描述。
2 、结果展示
如下图所示划分数据集: ①训练集由100个已知标签样本构成;②无标签样本集中有400个样本,其标签通过图半监督算法获取;③测试集有100个样本。基于图半监督算法自动给样本集中400个无标签样本上标签;②再将新标记的400个样本数据和训练集中100个已知标签样本数据合并送入到ELM中进行训练,最后用训练好的ELM对测试集进行分类,并与真实类别对比计算分类准确率。
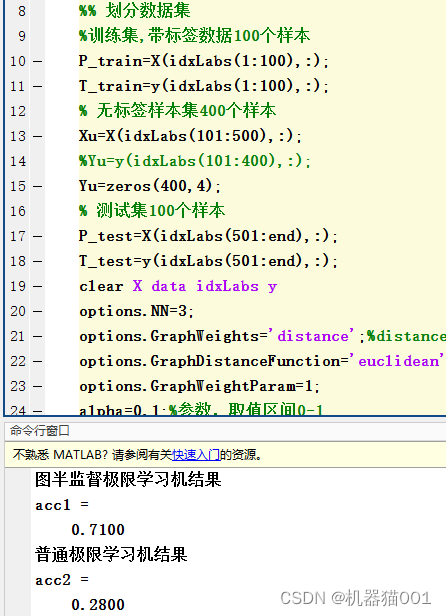
为方便对比, ELM极限学习机的网络结构参数设置一致。上图可以看出:由于带标签样本数据量少,普通极限学习机的分类准确率只有28%,而图半监督极限学习机的准确率有71%,准确率大幅度提升。可见图半监督方法在小样本环境下能发挥一定效果。