爬取免费代理IP并测试
写在开头:这次总共爬了三个代理ip的网站,前两个网站经过测试,ip并不能访问我真正想爬的网站
Git仓库:https://gitee.com/jiangtongxueya/my-spider/tree/master/%E7%88%AC%E5%8F%96%E4%BB%A3%E7%90%86IP
一. 三一代理
这是我爬的第一个代理ip网站,爬的都是https的ip
1. 网页结构
首先,想要爬一个网站,肯定要先了解一下网站html的结构。

这是网页的图片,通过页面,我们大概知道他是一个table的形式来显示数据的,然后我们通过F12的审查元素来看看他的具体html代码。
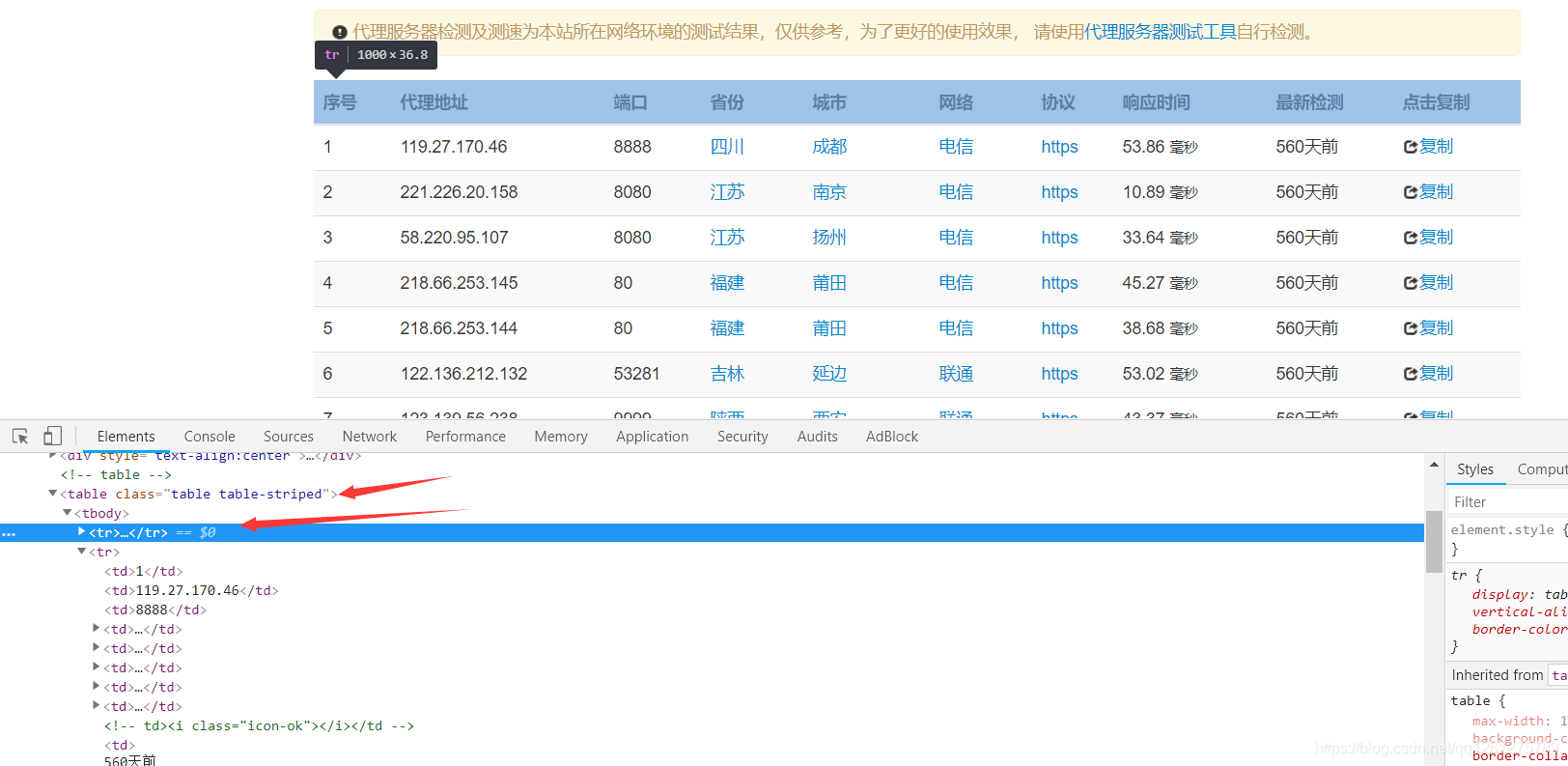
通过查看html代码,我们可以发现,整个table有一个属性,他的类名叫做table table-striped,那么我们之后就可以通过选取这个类名来准确获取到这个表的数据了。再来看第一个<tr>标签,这个<tr>标签显示的是表头,也就是表中每个字段的名字,所以我们在之后爬取的时候需要跳过第一个<tr>,爬取之后的tr标签。接着我们再仔细观察,一个<tr>里面有好多个<td>标签,其中第二个<td>存放的是ip,第三个<td>存放的是端口号,那么我们可以知道,根据table的规则,每一行的第二个和第三个都是ip和端口号,所以我们就知道该怎么爬取这几个数据了。接下来,我们一起看看具体怎么敲代码来爬取数据。
2. 导入库
from lxml import etree
import requests
from bs4 import BeautifulSoup
import os
import re
import time
import random
3. 定义的一些全局变量
我不想定义在函数内,而且又是不会变的东西,所以就写在函数外面,写成全局变量,url是代理ip的网站网址,basepath是当前程序运行的路径,user-agent是请求头中的参数,访问网站时,网站会根据请求头中的参数来识别访问者是谁(最简单的反爬措施,因为网站还可以通过cookie和ip等东西来判断来访者)
url='http://31f.cn/https-proxy/' #目标网站
basePath = os.getcwd() #当前程序所在的路径
userAgentList = [ #user-agent列表
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)",
"Mozilla/5.0 (Macintosh; U; PPC Mac OS X 10.5; en-US; rv:1.9.2.15) Gecko/20110303 Firefox/3.6.15",
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3823.400 QQBrowser/10.7.4307.400",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4315.4 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"Opera/9.80 (Windows NT 6.1; U; zh-cn) Presto/2.9.168 Version/11.50",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 2.0.50727; SLCC2; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.3; .NET4.0C; Tablet PC 2.0; .NET4.0E)",
]
timeout = 10 #连接超时时间
4. 获取网页html代码部分
这里最好是要做try catch处理的,但是因为爬的东西少,而且简单,也就没去做异常处理了
在请求头中选择不同的user-agent可以一定程度上避免被网站监测到是爬虫,其效果较差
def get_one_page(url):
global timeout
time.sleep(5) #睡眠1秒,避免频繁范围
headers={
#在请求头中加入user-agent参数,通过random库,
'User-Agent':random.choice(userAgentList), #随机选取上面user-agent列表中的一条user-agent
}
response=requests.get( #发起请求
url, #目标网站
headers=headers, #请求头
timeout=timeout, #超时时间
verify=False, #不检测ssl证书
)
if response.status_code==200: #响应状态码为200的情况,表示访问成功
response.close() #按网上的方法来的,避免连接太多
return response.text #返回目标网站的html代码
return None
5. 解析html部分
这部分主要就是把获取的html解析成特定的格式,然后从中获取自己所需的标签和数据
def parse_one_page(html): #解析html部分
ipList = {
}
okList = {
}
soup=BeautifulSoup(html,'lxml') #用beautifulsoup进行解析
table = soup.find_all(class_="table table-striped")[0] #选取html代码中class为table table-striped的第一个标签
# print(table)
trList = table.select("tr") #再选取其中标签为tr的所有标签
for i in range(len(trList)): #循环获取tr的标签列表
if (i != 0): #由于第一个tr是表头中的tr,所以我们要去掉第一个tr,所以i要不等于0
tdList = trList[i].select("td") #选取当前tr标签中的td标签
# print(tdList)
# print(tdList[1].next_element)
# print(tdList[1].next_element+":"+tdList[2].next_element)
ip = tdList[1].next_element+":"+tdList[2].next_element #通过分析html代码我们可以知道,第二个和第三个td是我们需要的ip和端口号
aDict = {
"https":ip} #将ip做成一个字典(其实这么做是错的,字典的key只能唯一,所以会覆盖之前的ip)
ok = checkIpIsOK(aDict) #测试这个ip能不能访问之后真正想爬取的网站(请看我下一篇博客)
ipList.update(aDict) #将aDict存进ipList
okList.update({
ip:ok}) #如果测试ip可以成功访问的,就把ip存进okList
return ipList,okList #这个return其实没用,因为我直接在上面进行了检测,不需要出去再检测
6. 检测ip是否可用部分
其实和第四步的代码基本相同,只是换了个不同的url而已
def checkIpIsOK(ipList): #检测ip是否可以成功访问的函数
headers={
'User-Agent':random.choice(userAgentList),
}
try:
response=requests.get(
url='https://unpkg.com/browse/[email protected]/',
headers=headers,
timeout=timeout,
verify=False,
proxies=ipList,
)
if response.status_code==200: #只要状态码是200就说明可以正常访问,不需要做更多操作
response.close()
return True
return False
except BaseException:
return False
7. 主函数
这里我本来是想最后再一块检测ip是否可用的,但是后来想想,爬一个检测一个更方便,这样工作量小一点,所以就把检测放到爬取中间做了。
def main():
global url
html=get_one_page(url)
ipList,okList = parse_one_page(html)
print(okList)
# checkIpIsOK(ipList)
main()
8.最后结果
结果说明,这个网站的免费代理ip无法当做我的代理ip去爬我想爬的网站

二.齐云代理
这是我爬的第二个网站,这个网站和上一个大体相同,不同的地方是这个网站ip量大,有做分页处理,所以可以爬很多个页面。
1. 网页结构
和第一个网站一样,首先先来分析一下网页结构
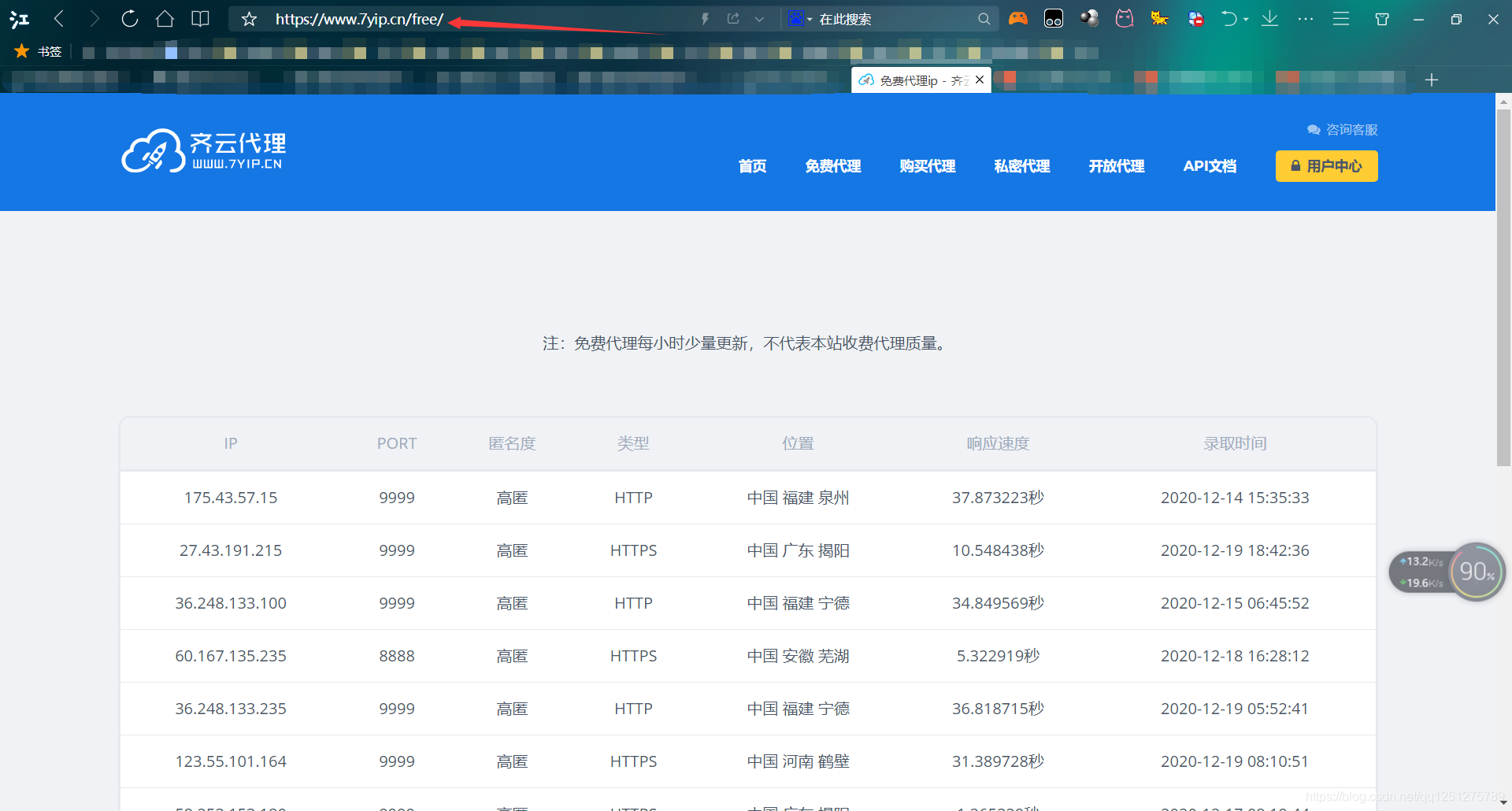
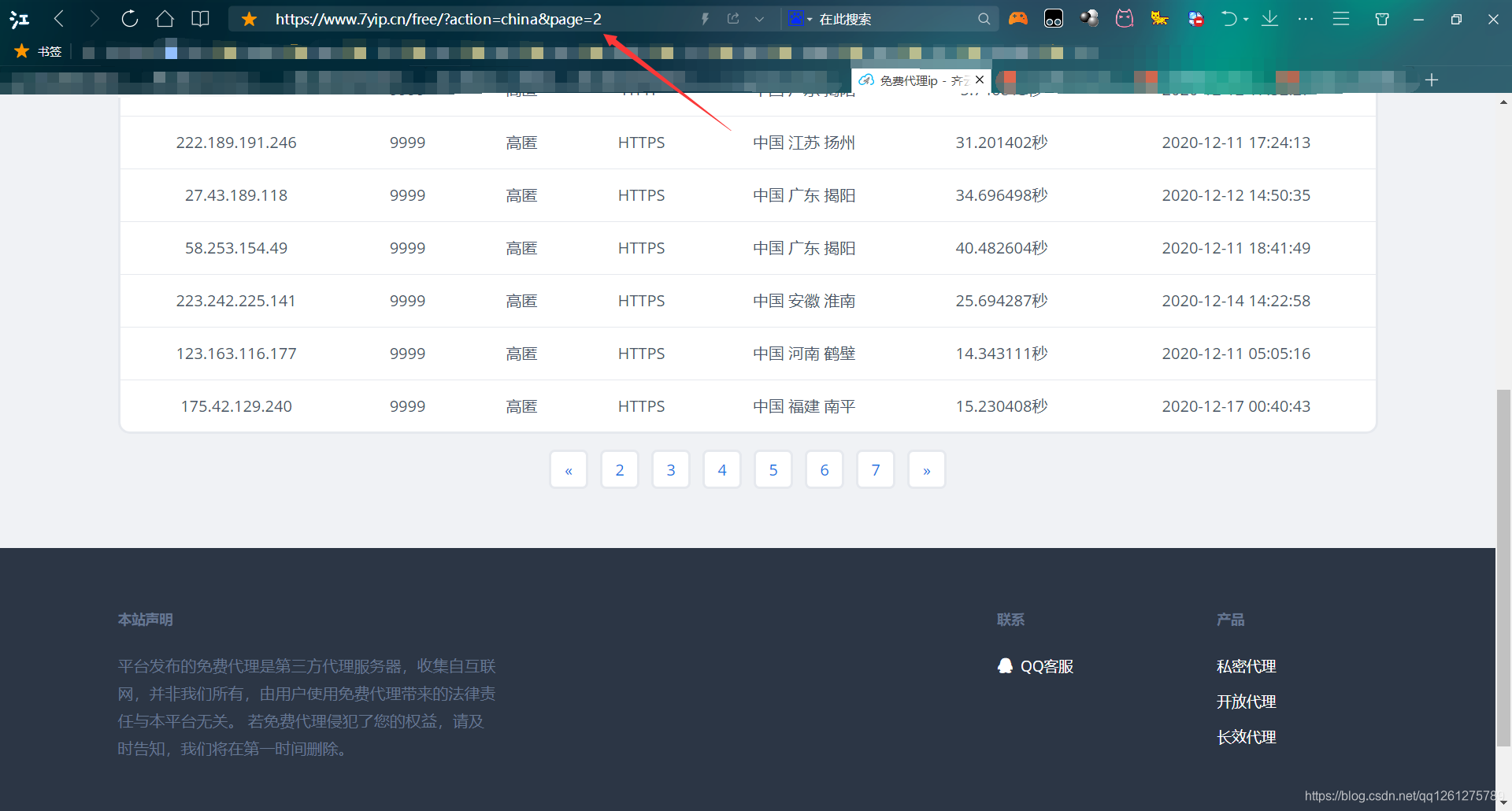
这是网站的页面,首先先来注意一下这个网址,当我点击第二页后,他变成了这样子。说明这个网站是通过在url后面追加page这个参数来显示不同的页面的,所以,我们之后只需要动态变化这个page的值就可以做到爬取每一页的内容了。接下来F12审查元素看看网页源代码,
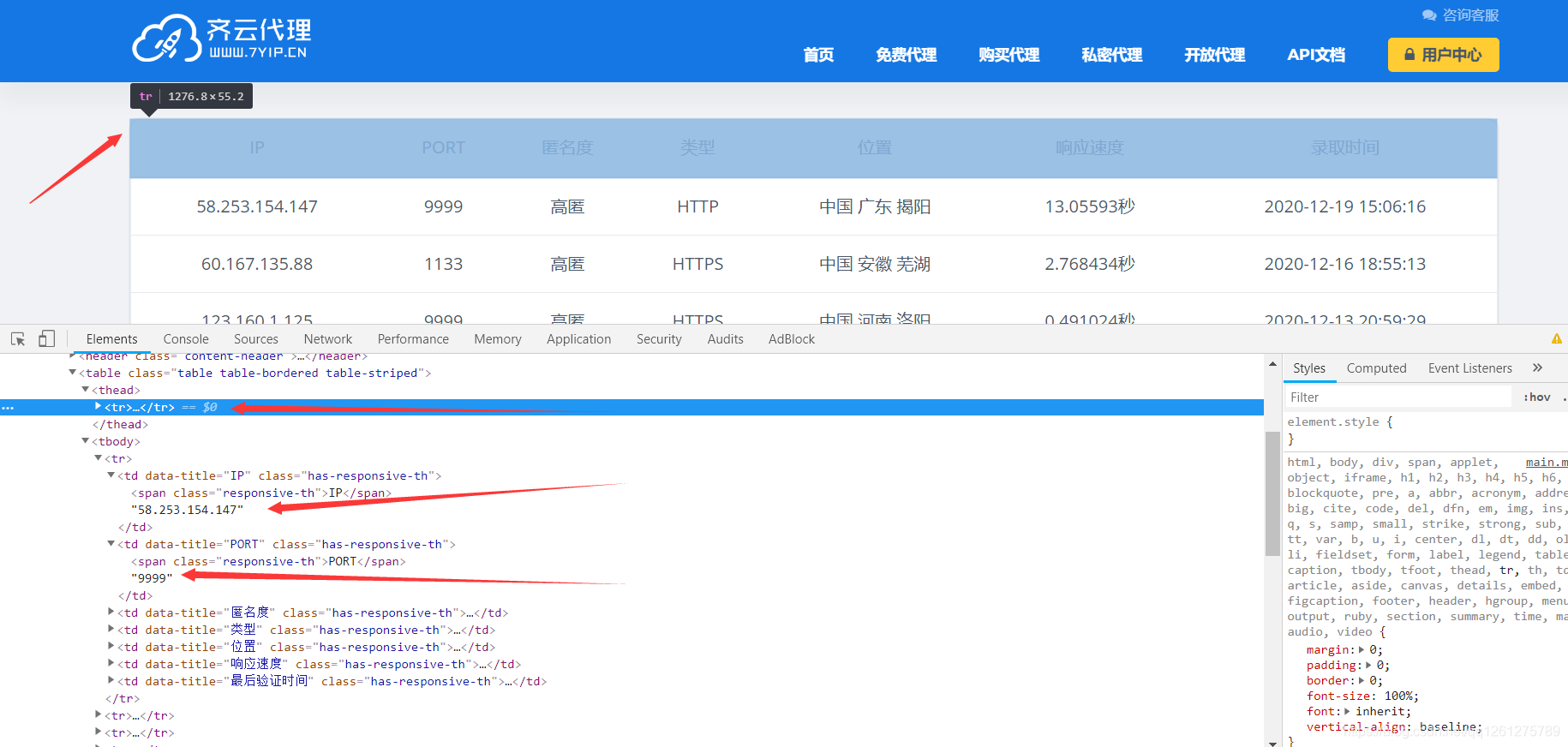
首先和第一个网站一样,这都是一个table的形式,<table>的类名叫table table-bordered table-striped,接着注意这个<tr>,第一个<tr>存放的内容是表头,所以我们还是照例需要跳过。
然后我们来看看接下来的<tr>标签,<tr>还是有好几个<td>,第一个<td>是ip,第二个<td>是端口号,所以同样的方法,我们开始爬虫。
2. 导入库
from lxml import etree
import requests
from bs4 import BeautifulSoup
import os
import re
import time
import random
3. 定义的一些全局变量
大体和第一个网站的代码相同,但是注意,这里的url没有page的参数,只到page=,因为后面的页码,需要我们动态添加,不能写死。
url='https://www.7yip.cn/free/?action=china&page=' #目标网站
basePath = os.getcwd() #当前程序所在的路径
userAgentList = [ #user-agent列表
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)",
"Mozilla/5.0 (Macintosh; U; PPC Mac OS X 10.5; en-US; rv:1.9.2.15) Gecko/20110303 Firefox/3.6.15",
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3823.400 QQBrowser/10.7.4307.400",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4315.4 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"Opera/9.80 (Windows NT 6.1; U; zh-cn) Presto/2.9.168 Version/11.50",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 2.0.50727; SLCC2; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.3; .NET4.0C; Tablet PC 2.0; .NET4.0E)",
]
timeout = 10 #连接超时时间
ipList = {
} #这里我把这两个列表也直接全局变量了
okList = {
} #这里我把这两个列表也直接全局变量了
4. 获取网页html代码部分
这里和第一个网站的代码基本相同,没做什么改动,就去掉了睡眠时间,ssl证书检测和超时时间,因为对于爬取这种小小的东西来说,实在没必要加着
def get_one_page(url):
global timeout
# time.sleep(5) #睡眠1秒,避免频繁范围
headers={
#在请求头中加入user-agent参数,通过random库,
'User-Agent':random.choice(userAgentList), #随机选取上面user-agent列表中的一条user-agent
}
response=requests.get( #发起请求
url, #目标网站
headers=headers, #请求头
# timeout=timeout, #超时时间
# verify=False, #不检测ssl证书
)
if response.status_code==200: #响应状态码为200的情况,表示访问成功
response.close() #按网上的方法来的,避免连接太多
return response.text #返回目标网站的html代码
return None
5. 解析html部分
这里和第一个网站的代码也是基本相同,我甚至震惊了,看上去也没用什么前端框架,页面效果完全不同的两个网站,其中的类名竟然惊人的相似。
def parse_one_page(html): #解析html部分
global ipList,okList
soup=BeautifulSoup(html,'lxml') #用beautifulsoup进行解析
table = soup.find_all(class_="table table-bordered table-striped")[0] #选取html代码中class为table table-bordered table-striped的第一个标签
# print(table)
trList = table.select("tr") #再选取其中标签为tr的所有标签
# print(trList)
for i in range(len(trList)): #循环获取tr的标签列表
if (i != 0): #由于第一个tr是表头中的tr,所以我们要去掉第一个tr,所以i要不等于0
tdList = trList[i].select("td") #选取当前tr标签中的td标签
# print(tdList)
# print(tdList[1].next_element)
# print(tdList[1].next_element+":"+tdList[2].next_element)
ip = tdList[0].next_element+":"+tdList[1].next_element #通过分析html代码我们可以知道,第一个和第二个td是我们需要的ip和端口号
aDict = {
"https":ip} #将ip做成一个字典(其实这么做是错的,字典的key只能唯一,所以会覆盖之前的ip)
ok = checkIpIsOK(aDict) #测试这个ip能不能访问之后真正想爬取的网站(请看我下一篇博客)
ipList.update(aDict) #将aDict存进ipList
okList.update({
ip:ok}) #如果测试ip可以成功访问的,就把ip存进okList
return ipList,okList #这个return其实没用,因为这两个list已经是全局变量了,外面也可以看得到
6. 检测ip是否可用部分
这里和上面的代码完全一样,因为整个代码我都是复制上一个网站的过来改的ヾ(@▽@)ノ
def checkIpIsOK(ipList): #检测ip是否可以成功访问的函数
headers={
'User-Agent':random.choice(userAgentList),
}
try:
response=requests.get(
url='https://unpkg.com/browse/[email protected]/',
headers=headers,
timeout=timeout,
verify=False,
proxies=ipList,
)
if response.status_code==200: #只要状态码是200就说明可以正常访问,不需要做更多操作
response.close()
return True
return False
except BaseException:
return False
7. 主函数
这里稍微和第一个网站有些区别了,通过for循环,动态添加url中的page参数,使得可以爬取每页的内容。
def main():
global url
for i in range(10): #通过循环取得一个数字i
html=get_one_page(url+str(i+1)) #因为循环是从0开始的,所以i+1,并且转换成str类型添加在url末尾
parse_one_page(html)
print(okList)
# checkIpIsOK(ipList)
main()
8.最后结果
结果说明,这个网站的免费代理ip还是无法当做我的代理ip去爬我想爬的网站
三.西拉代理
这是我爬的第三个网站,首先一提,这个网站的ip有很多可用的,所以这是我爬的最后一个网站
##### 1. 网页结构
首先,还是看看网页结构

同样的也是table的样子,然后我们通过审查元素看看源代码

大致相同的布局,和前两个基本没差,注意table的类名叫fl-table,第一个<tr>是表头,每一列的第一个<td>是ip和端口号
2. 导入库
from lxml import etree
import requests
from bs4 import BeautifulSoup
import os
import re
import time
import random
3. 定义的一些全局变量
和上面的一样,除了url有变化
url='http://www.xiladaili.com/https/' #目标网站
basePath = os.getcwd() #当前程序所在的路径
userAgentList = [ #user-agent列表
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)",
"Mozilla/5.0 (Macintosh; U; PPC Mac OS X 10.5; en-US; rv:1.9.2.15) Gecko/20110303 Firefox/3.6.15",
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3823.400 QQBrowser/10.7.4307.400",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4315.4 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"Opera/9.80 (Windows NT 6.1; U; zh-cn) Presto/2.9.168 Version/11.50",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 2.0.50727; SLCC2; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.3; .NET4.0C; Tablet PC 2.0; .NET4.0E)",
]
timeout = 10 #连接超时时间
ipList = {
} #这里我把这两个列表也直接全局变量了
okList = {
} #这里我把这两个列表也直接全局变量了
4. 获取网页html代码部分
和上面的一样
def get_one_page(url):
global timeout
# time.sleep(5) #睡眠1秒,避免频繁范围
headers={
#在请求头中加入user-agent参数,通过random库,
'User-Agent':random.choice(userAgentList), #随机选取上面user-agent列表中的一条user-agent
}
response=requests.get( #发起请求
url, #目标网站
headers=headers, #请求头
# timeout=timeout, #超时时间
# verify=False, #不检测ssl证书
)
if response.status_code==200: #响应状态码为200的情况,表示访问成功
response.close() #按网上的方法来的,避免连接太多
# print(response.text)
return response.text #返回目标网站的html代码
return None
5. 解析html部分
基本没变,稍微改了一点地方
def parse_one_page(html): #解析html部分
global ipList,okList
soup=BeautifulSoup(html,'html5lib') #用beautifulsoup进行解析,这个地方稍微有点不同,lxml解析不了,需要跳过html5lib来解析
table = soup.find_all(class_="fl-table")[0] #选取html代码中class为fl-table的第一个标签
# print(table)
trList = table.select("tr") #再选取其中标签为tr的所有标签
# print(trList)
for i in range(len(trList)): #循环获取tr的标签列表
if (i != 0): #由于第一个tr是表头中的tr,所以我们要去掉第一个tr,所以i要不等于0
tdList = trList[i].select("td") #选取当前tr标签中的td标签
# print(tdList)
# print(tdList[1].next_element)
# print(tdList[1].next_element+":"+tdList[2].next_element)
# ip = tdList[0].next_element+":"+tdList[1].next_element
ip = tdList[0].next_element #通过分析html代码我们可以知道,第一个td是我们需要的ip和端口号
# print(ip)
aDict = {
"https":ip} #将ip做成一个字典(其实这么做是错的,字典的key只能唯一,所以会覆盖之前的ip)
ok = checkIpIsOK(aDict) #测试这个ip能不能访问之后真正想爬取的网站(请看我下一篇博客)
ipList.update(aDict) #将aDict存进ipList
okList.update({
ip:ok}) #如果测试ip可以成功访问的,就把ip存进okList
return ipList,okList #这个return其实没用,因为这两个list已经是全局变量了,外面也可以看得到
6. 检测ip是否可用部分
没改动
def checkIpIsOK(ipList): #检测ip是否可以成功访问的函数
headers={
'User-Agent':random.choice(userAgentList),
}
try:
print(ipList)
response=requests.get(
url='https://unpkg.com/browse/[email protected]/',
headers=headers,
timeout=timeout,
verify=False,
proxies=ipList,
)
if response.status_code==200: #只要状态码是200就说明可以正常访问,不需要做更多操作
print("ok")
response.close()
return True
return False
except BaseException:
return False
7. 主函数
这里稍微和第一个网站有些区别了,通过for循环,动态添加url中的page参数,使得可以爬取每页的内容。
def main():
global url
for i in range(1): #不需要循环,但是懒得改代码了,所以就循环改成1,相当于没有循环
html=get_one_page(url)
parse_one_page(html)
# print(okList)
# checkIpIsOK(ipList)
main()
8.最后结果
终于成功了,有很多可用的ip
