在爬虫之路上,面对反爬虫措施,我们该怎样解决呢,当然,正所谓”你有反爬策略,我也有过墙梯”,所以下面将使用scrapy来爬取免费代理ip,让我们从此不在害怕IP被封了.由于免费代理比较多,这里就以西刺代理为例
相关的代码已经上传到GitHub
GitHub地址 : https://github.com/stormdony/scarpydemo,里面有一些scrapy的demo,欢迎fork和star
1.创建scrapy项目
scrapy startproject get_ip_demo
2.创建spider
scrapy genspider get_ip www.xicidaili.com
通过观察网站,找到需要获取的数据
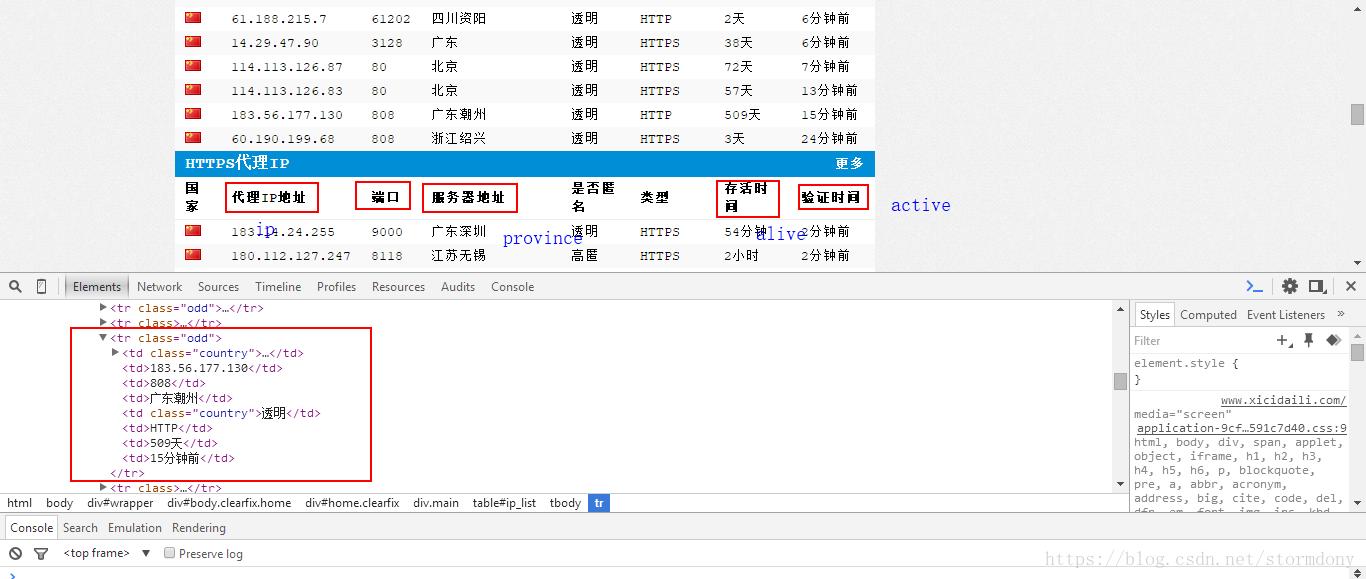
这里主要使用xpath来定位
# -*- coding: utf-8 -*-
import telnetlib
import scrapy
from get_ip_demo.items import GetIpDemoItem
class GetIpSpider(scrapy.Spider):
name = 'get_ip'
allowed_domains = ['xicidaili.com']
start_urls = ['http://www.xicidaili.com/']
def parse(self, response):
ip_list = response.css('.odd')
for each_ip in ip_list:
ip = each_ip.xpath('td[2]/text()').extract_first()
port = each_ip.xpath('td[3]/text()').extract_first()
province = each_ip.xpath('td[4]/text()').extract_first()
alive = each_ip.xpath('td[7]/text()').extract_first()
active = each_ip.xpath('td[8]/text()').extract_first()
item = GetIpDemoItem()
item['ip'] = ip
item['port'] = port
item['province'] = province
item['alive'] = alive
item['active'] = active
try:
telnetlib.Telnet(ip, port=port, timeout=20)#验证是否可用
except:
print('connect failed')
else:
print('success')
yield item
3.编写item
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class GetIpDemoItem(scrapy.Item):
# define the fields for your item here like:
ip = scrapy.Field()
port = scrapy.Field()
alive = scrapy.Field()#存活时间
province = scrapy.Field()#位置
active = scrapy.Field()#验证时间
4.设置存储—pipelines.py
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import pymongo
from scrapy.conf import settings
class GetIpDemoPipeline(object):
def __init__(self):
port = settings['MONGODB_PORT']
host = settings['MONGODB_HOST']
db_name = settings['MONGODB_DBNAME']
client = pymongo.MongoClient(host=host, port=port)
db = client[db_name]
self.post = db[settings['MONGODB_DOCNAME']]
def process_item(self, item, spider):
ip_info = dict(item)
self.post.insert(ip_info)
return item5.修改settings.py
# -*- coding: utf-8 -*-
# Scrapy settings for get_ip_demo project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://doc.scrapy.org/en/latest/topics/settings.html
# https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'get_ip_demo'
SPIDER_MODULES = ['get_ip_demo.spiders']
NEWSPIDER_MODULE = 'get_ip_demo.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'get_ip_demo (+http://www.yourdomain.com)'
# Obey robots.txt rules
#这里一定要修改为False,否则会出错
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#设置请求头
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/4.0(compatible;MSIE7.0;WindowsNT5.1)'
}
# Enable or disable spider middlewares
# See https://doc.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'get_ip_demo.middlewares.GetIpDemoSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'get_ip_demo.middlewares.GetIpDemoDownloaderMiddleware': 543,
#}
# Enable or disable extensions
# See https://doc.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
#开启存储
ITEM_PIPELINES = {
'get_ip_demo.pipelines.GetIpDemoPipeline': 300,
}
MONGODB_HOST = '127.0.0.1'
MONGODB_PORT = 27017
MONGODB_DBNAME = 'XiCiDaiLi'
MONGODB_DOCNAME = 'ip_item'
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
6.运行
在Terminal运行下面的代码
scrapy crawl get_ip

打开Robomongodb,可以看到我们爬取下来的数据了
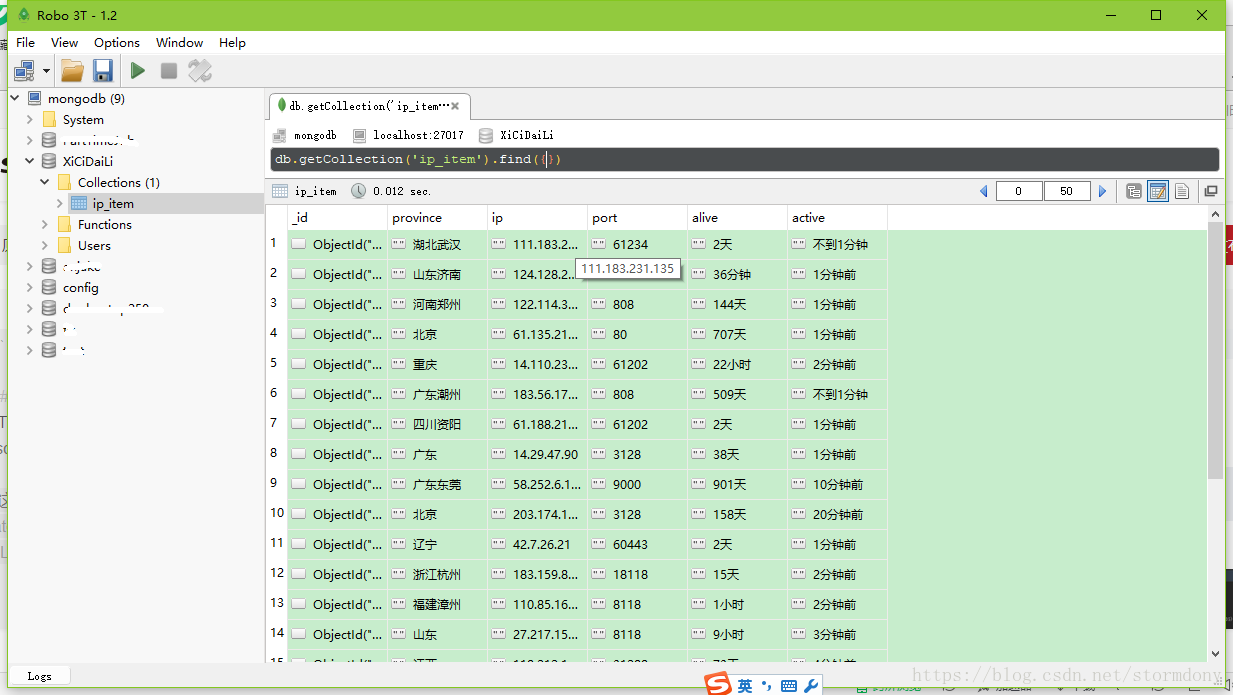
7.遇到的问题
- 在数据库中只抓到了20+条数据,但是网站有100+条,所以中间出了问题?
原来是因为只抓了class='.odd'的ip,但是有些ip列是没有class属性的,如果只筛选tr的话,又会抓到标题,所以该任务只是实现了一半而已
如果各位有解决的办法,请告知我,蟹蟹 ^_^,如果对你有帮助,请点个赞哦
